 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLHub: Model and Data Serving for Science
Paper and Code
Nov 27, 2018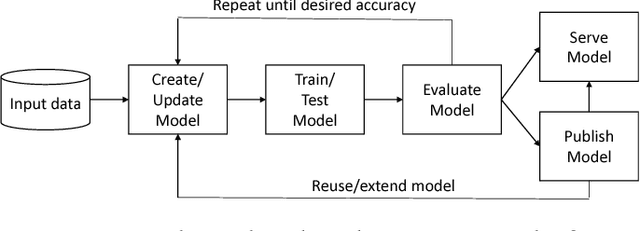
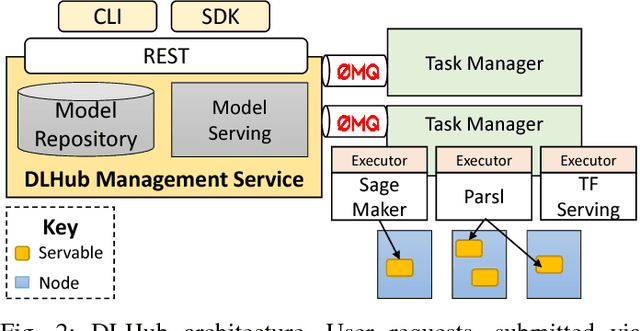
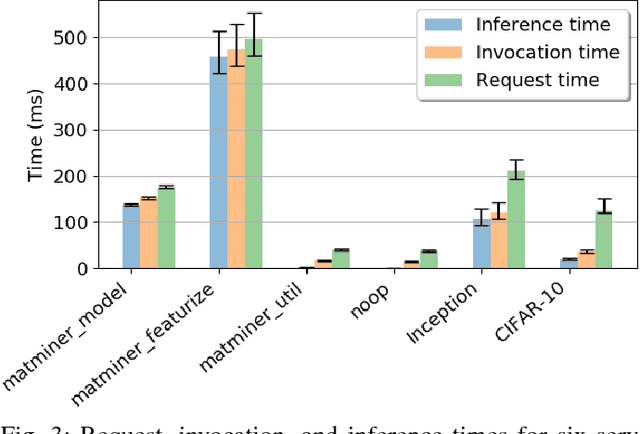
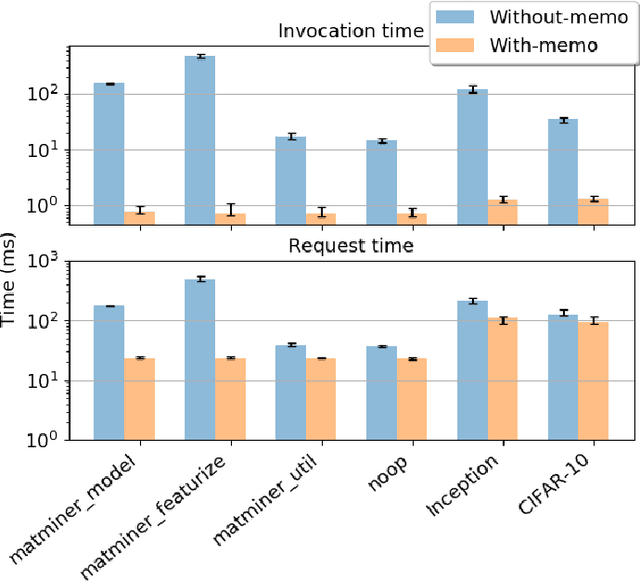
While the Machine Learning (ML) landscape is evolving rapidly, there has been a relative lag in the development of the "learning systems" needed to enable broad adoption. Furthermore, few such systems are designed to support the specialized requirements of scientific ML. Here we present the Data and Learning Hub for science (DLHub), a multi-tenant system that provides both model repository and serving capabilities with a focus on science applications. DLHub addresses two significant shortcomings in current systems. First, its selfservice model repository allows users to share, publish, verify, reproduce, and reuse models, and addresses concerns related to model reproducibility by packaging and distributing models and all constituent components. Second, it implements scalable and low-latency serving capabilities that can leverage parallel and distributed computing resources to democratize access to published models through a simple web interface. Unlike other model serving frameworks, DLHub can store and serve any Python 3-compatible model or processing function, plus multiple-function pipelines. We show that relative to other model serving systems including TensorFlow Serving, SageMaker, and Clipper, DLHub provides greater capabilities, comparable performance without memoization and batching, and significantly better performance when the latter two techniques can be employed. We also describe early uses of DLHub for scientific applications.