 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuPAQ: An Efficient Planner for Large-scale Predictive Analytic Queries
Paper and Code
Mar 08, 2015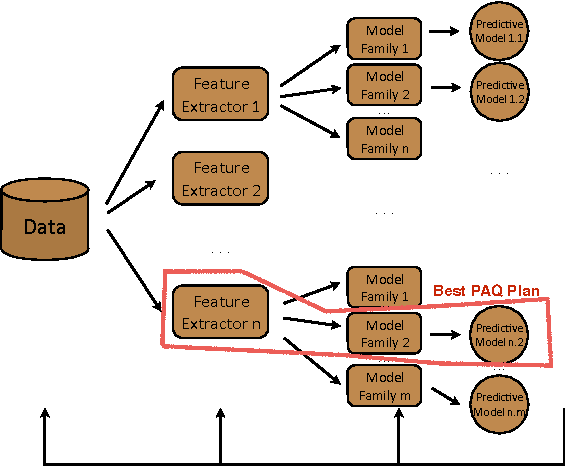
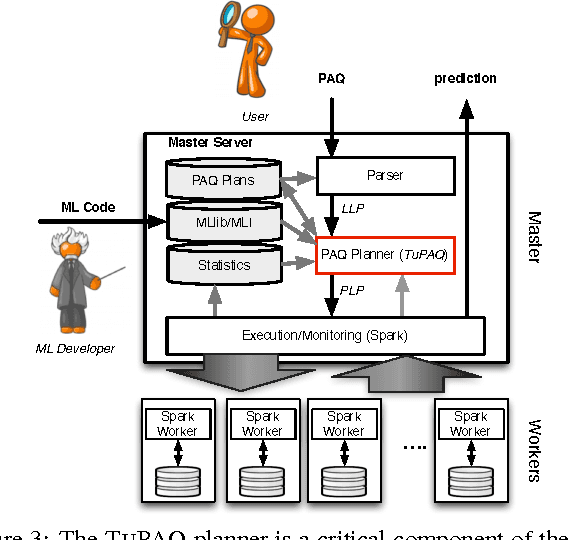
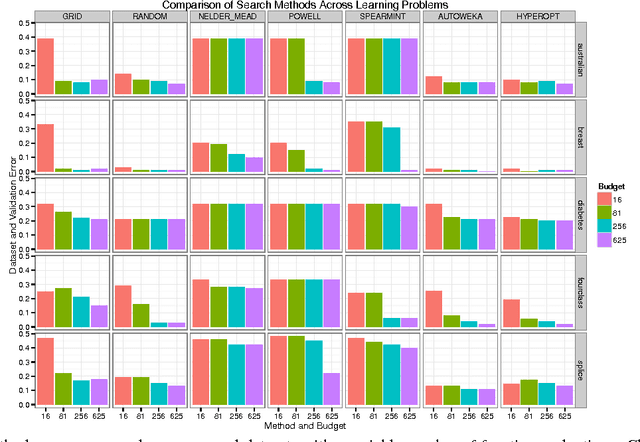
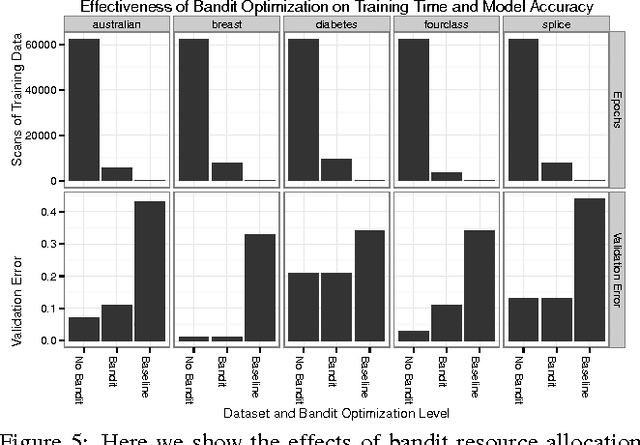
The proliferation of massive datasets combined with the development of sophisticated analytical techniques have enabled a wide variety of novel applications such as improved product recommendations, automatic image tagging, and improved speech-driven interfaces. These and many other applications can be supported by Predictive Analytic Queries (PAQs). A major obstacle to supporting PAQs is the challenging and expensive process of identifying and training an appropriate predictive model. Recent efforts aiming to automate this process have focused on single node implementations and have assumed that model training itself is a black box, thus limiting the effectiveness of such approaches on large-scale problems. In this work, we build upon these recent efforts and propose an integrated PAQ planning architecture that combines advanced model search techniques, bandit resource allocation via runtime algorithm introspection, and physical optimization via batching. The result is TuPAQ, a component of the MLbase system, which solves the PAQ planning problem with comparable quality to exhaustive strategies but an order of magnitude more efficiently than the standard baseline approach, and can scale to models trained on terabytes of data across hundreds of machines.