 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeystoneML: Optimizing Pipelines for Large-Scale Advanced Analytics
Oct 29, 2016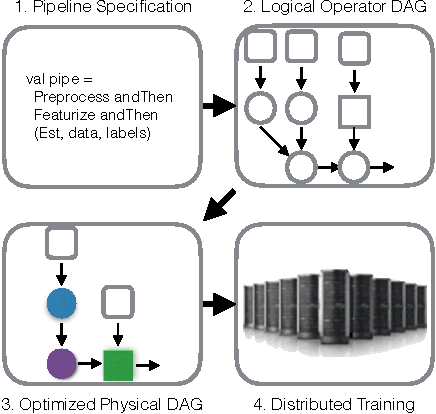


Modern advanced analytics applications make use of machine learning techniques and contain multiple steps of domain-specific and general-purpose processing with high resource requirements. We present KeystoneML, a system that captures and optimizes the end-to-end large-scale machine learning applications for high-throughput training in a distributed environment with a high-level API. This approach offers increased ease of use and higher performance over existing systems for large scale learning. We demonstrate the effectiveness of KeystoneML in achieving high quality statistical accuracy and scalable training using real world datasets in several domains. By optimizing execution KeystoneML achieves up to 15x training throughput over unoptimized execution on a real image classification application.
Scalable Linear Causal Inference for Irregularly Sampled Time Series with Long Range Dependencies
Mar 10, 2016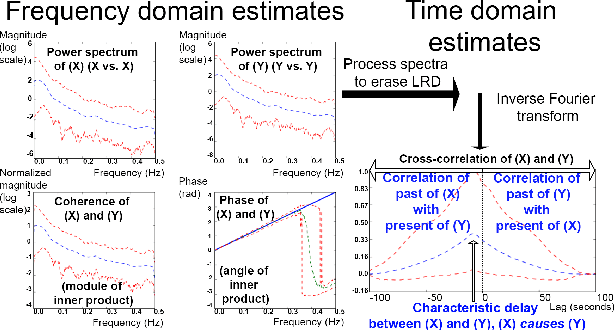
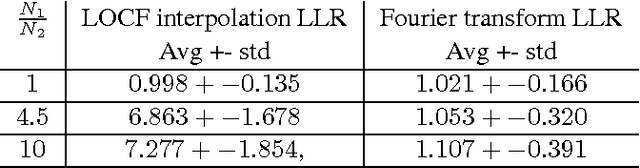
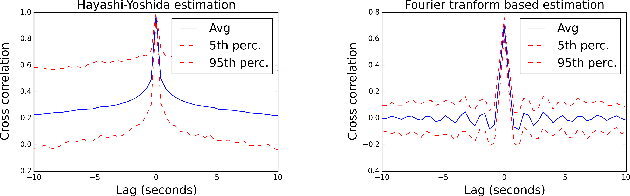
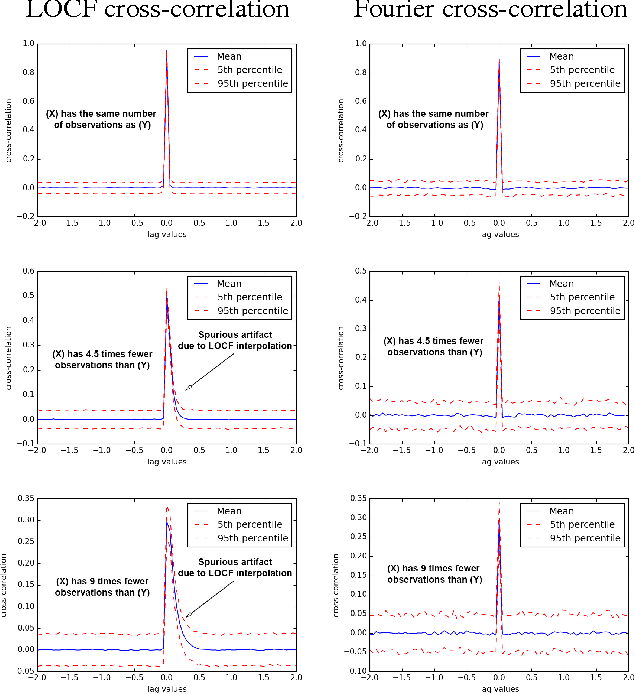
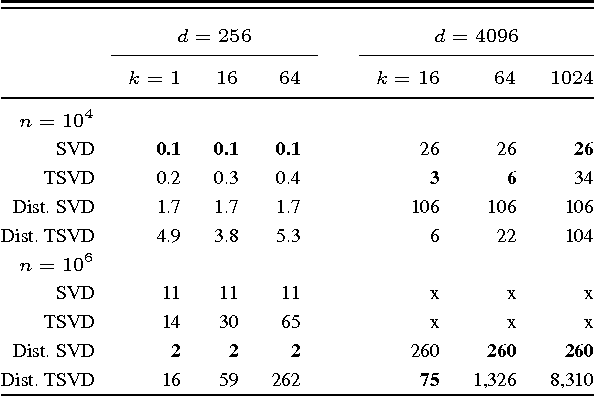
Linear causal analysis is central to a wide range of important application spanning finance, the physical sciences, and engineering. Much of the existing literature in linear causal analysis operates in the time domain. Unfortunately, the direct application of time domain linear causal analysis to many real-world time series presents three critical challenges: irregular temporal sampling, long range dependencies, and scale. Moreover, real-world data is often collected at irregular time intervals across vast arrays of decentralized sensors and with long range dependencies which make naive time domain correlation estimators spurious. In this paper we present a frequency domain based estimation framework which naturally handles irregularly sampled data and long range dependencies while enabled memory and communication efficient distributed processing of time series data. By operating in the frequency domain we eliminate the need to interpolate and help mitigate the effects of long range dependencies. We implement and evaluate our new work-flow in the distributed setting using Apache Spark and demonstrate on both Monte Carlo simulations and high-frequency financial trading that we can accurately recover causal structure at scale.
TuPAQ: An Efficient Planner for Large-scale Predictive Analytic Queries
Mar 08, 2015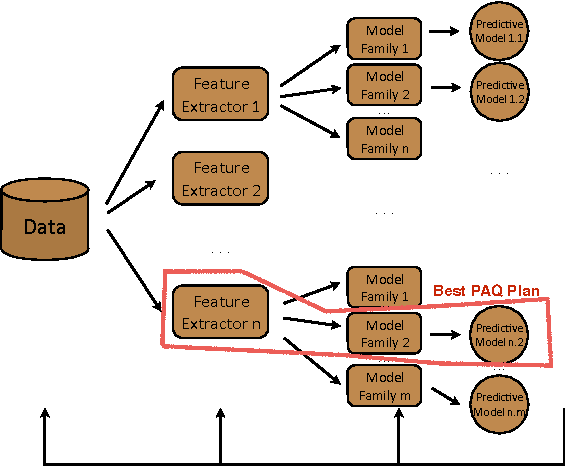
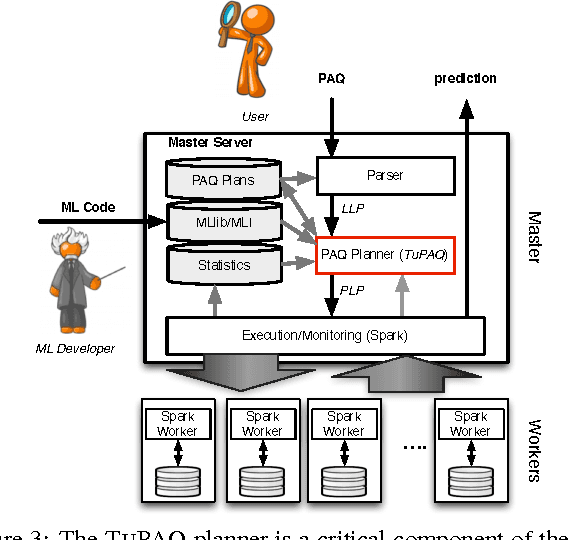
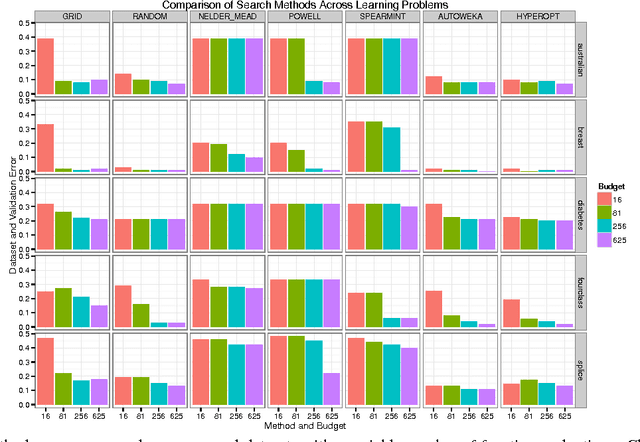
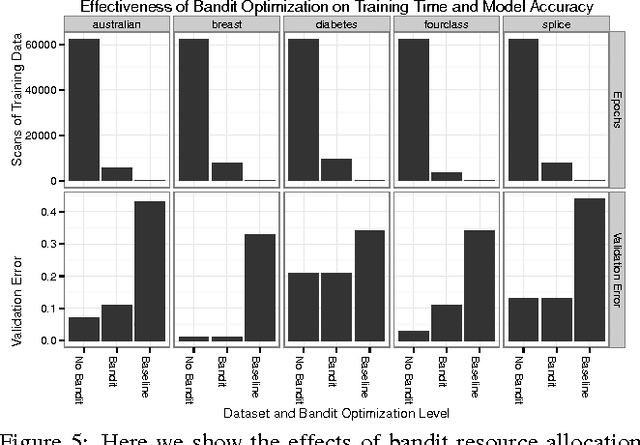
The proliferation of massive datasets combined with the development of sophisticated analytical techniques have enabled a wide variety of novel applications such as improved product recommendations, automatic image tagging, and improved speech-driven interfaces. These and many other applications can be supported by Predictive Analytic Queries (PAQs). A major obstacle to supporting PAQs is the challenging and expensive process of identifying and training an appropriate predictive model. Recent efforts aiming to automate this process have focused on single node implementations and have assumed that model training itself is a black box, thus limiting the effectiveness of such approaches on large-scale problems. In this work, we build upon these recent efforts and propose an integrated PAQ planning architecture that combines advanced model search techniques, bandit resource allocation via runtime algorithm introspection, and physical optimization via batching. The result is TuPAQ, a component of the MLbase system, which solves the PAQ planning problem with comparable quality to exhaustive strategies but an order of magnitude more efficiently than the standard baseline approach, and can scale to models trained on terabytes of data across hundreds of machines.
MLI: An API for Distributed Machine Learning
Oct 25, 2013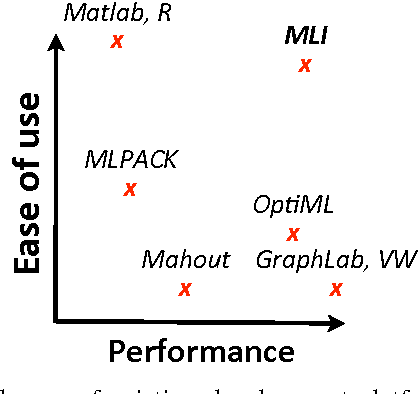
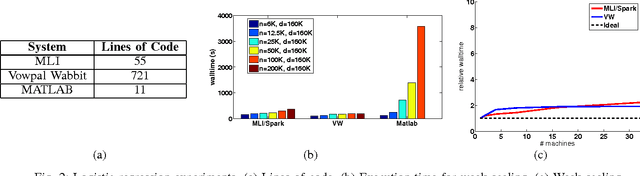
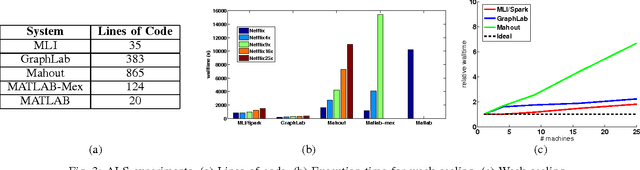
MLI is an Application Programming Interface designed to address the challenges of building Machine Learn- ing algorithms in a distributed setting based on data-centric computing. Its primary goal is to simplify the development of high-performance, scalable, distributed algorithms. Our initial results show that, relative to existing systems, this interface can be used to build distributed implementations of a wide variety of common Machine Learning algorithms with minimal complexity and highly competitive performance and scalability.