 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Geometry from Probability in the Analysis of Generalization
Apr 21, 2026The goal of machine learning is to find models that minimize prediction error on data that has not yet been seen. Its operational paradigm assumes access to a dataset $S$ and articulates a scheme for evaluating how well a given model performs on an arbitrary sample. The sample can be $S$ (in which case we speak of ``in-sample'' performance) or some entirely new $S'$ (in which case we speak of ``out-of-sample'' performance). Traditional analysis of generalization assumes that both in- and out-of-sample data are i.i.d.\ draws from an infinite population. However, these probabilistic assumptions cannot be verified even in principle. This paper presents an alternative view of generalization through the lens of sensitivity analysis of solutions of optimization problems to perturbations in the problem data. Under this framework, generalization bounds are obtained by purely deterministic means and take the form of variational principles that relate in-sample and out-of-sample evaluations through an error term that quantifies how close out-of-sample data are to in-sample data. Statistical assumptions can then be used \textit{ex post} to characterize the situations when this error term is small (either on average or with high probability).
In Defense of Defensive Forecasting
Jun 13, 2025This tutorial provides a survey of algorithms for Defensive Forecasting, where predictions are derived not by prognostication but by correcting past mistakes. Pioneered by Vovk, Defensive Forecasting frames the goal of prediction as a sequential game, and derives predictions to minimize metrics no matter what outcomes occur. We present an elementary introduction to this general theory and derive simple, near-optimal algorithms for online learning, calibration, prediction with expert advice, and online conformal prediction.
From Individual Experience to Collective Evidence: A Reporting-Based Framework for Identifying Systemic Harms
Feb 12, 2025When an individual reports a negative interaction with some system, how can their personal experience be contextualized within broader patterns of system behavior? We study the incident database problem, where individual reports of adverse events arrive sequentially, and are aggregated over time. In this work, our goal is to identify whether there are subgroups--defined by any combination of relevant features--that are disproportionately likely to experience harmful interactions with the system. We formalize this problem as a sequential hypothesis test, and identify conditions on reporting behavior that are sufficient for making inferences about disparities in true rates of harm across subgroups. We show that algorithms for sequential hypothesis tests can be applied to this problem with a standard multiple testing correction. We then demonstrate our method on real-world datasets, including mortgage decisions and vaccine side effects; on each, our method (re-)identifies subgroups known to experience disproportionate harm using only a fraction of the data that was initially used to discover them.
Gradient Descent Provably Solves Nonlinear Tomographic Reconstruction
Oct 06, 2023



In computed tomography (CT), the forward model consists of a linear Radon transform followed by an exponential nonlinearity based on the attenuation of light according to the Beer-Lambert Law. Conventional reconstruction often involves inverting this nonlinearity as a preprocessing step and then solving a convex inverse problem. However, this nonlinear measurement preprocessing required to use the Radon transform is poorly conditioned in the vicinity of high-density materials, such as metal. This preprocessing makes CT reconstruction methods numerically sensitive and susceptible to artifacts near high-density regions. In this paper, we study a technique where the signal is directly reconstructed from raw measurements through the nonlinear forward model. Though this optimization is nonconvex, we show that gradient descent provably converges to the global optimum at a geometric rate, perfectly reconstructing the underlying signal with a near minimal number of random measurements. We also prove similar results in the under-determined setting where the number of measurements is significantly smaller than the dimension of the signal. This is achieved by enforcing prior structural information about the signal through constraints on the optimization variables. We illustrate the benefits of direct nonlinear CT reconstruction with cone-beam CT experiments on synthetic and real 3D volumes. We show that this approach reduces metal artifacts compared to a commercial reconstruction of a human skull with metal dental crowns.
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
Jan 24, 2023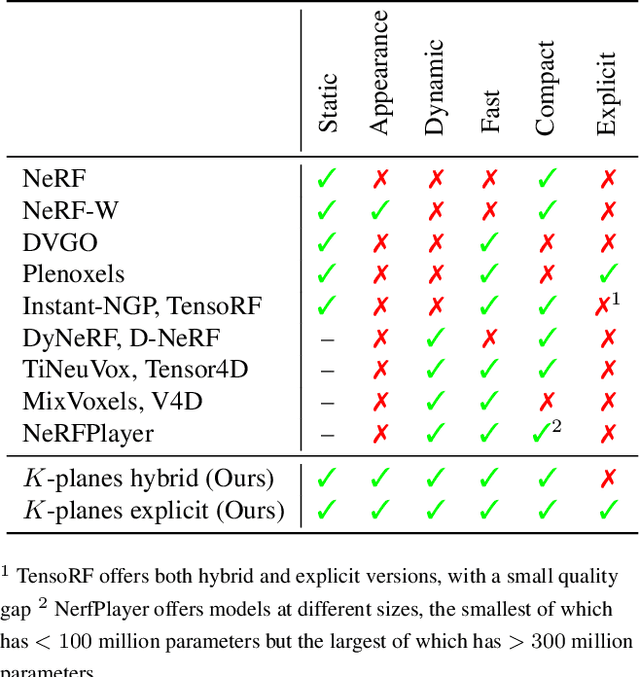
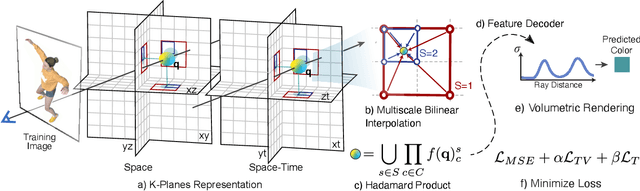

We introduce k-planes, a white-box model for radiance fields in arbitrary dimensions. Our model uses d choose 2 planes to represent a d-dimensional scene, providing a seamless way to go from static (d=3) to dynamic (d=4) scenes. This planar factorization makes adding dimension-specific priors easy, e.g. temporal smoothness and multi-resolution spatial structure, and induces a natural decomposition of static and dynamic components of a scene. We use a linear feature decoder with a learned color basis that yields similar performance as a nonlinear black-box MLP decoder. Across a range of synthetic and real, static and dynamic, fixed and varying appearance scenes, k-planes yields competitive and often state-of-the-art reconstruction fidelity with low memory usage, achieving 1000x compression over a full 4D grid, and fast optimization with a pure PyTorch implementation. For video results and code, please see sarafridov.github.io/K-Planes.
Towards Psychologically-Grounded Dynamic Preference Models
Aug 06, 2022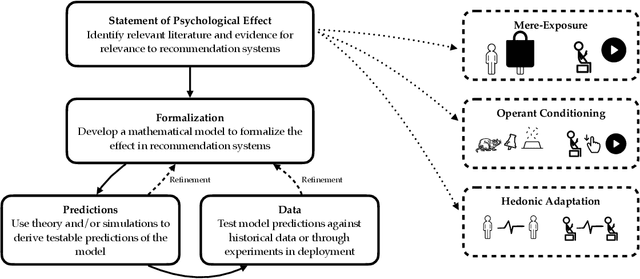
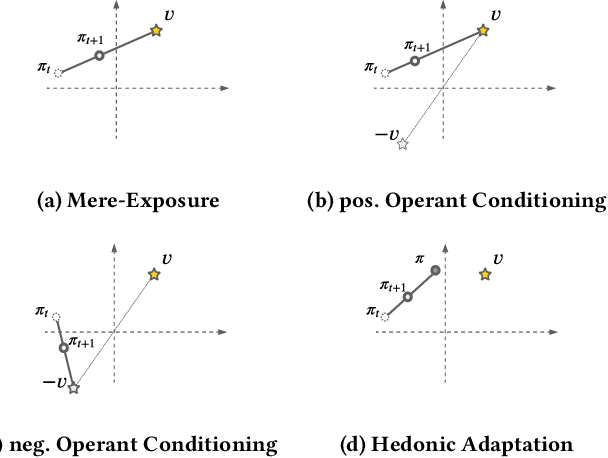
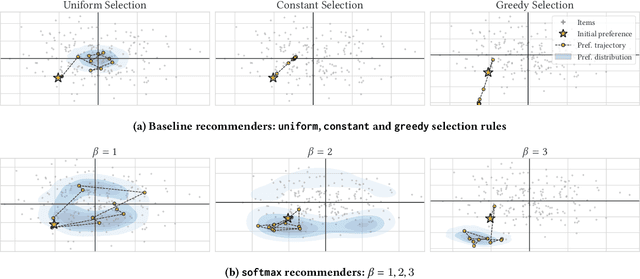
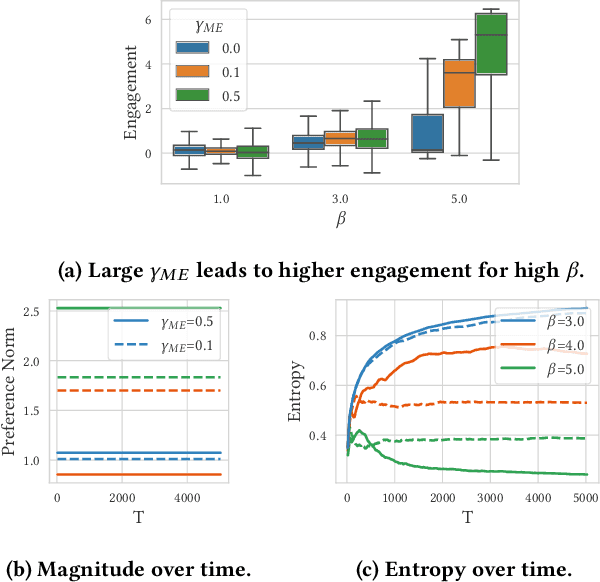
Designing recommendation systems that serve content aligned with time varying preferences requires proper accounting of the feedback effects of recommendations on human behavior and psychological condition. We argue that modeling the influence of recommendations on people's preferences must be grounded in psychologically plausible models. We contribute a methodology for developing grounded dynamic preference models. We demonstrate this method with models that capture three classic effects from the psychology literature: Mere-Exposure, Operant Conditioning, and Hedonic Adaptation. We conduct simulation-based studies to show that the psychological models manifest distinct behaviors that can inform system design. Our study has two direct implications for dynamic user modeling in recommendation systems. First, the methodology we outline is broadly applicable for psychologically grounding dynamic preference models. It allows us to critique recent contributions based on their limited discussion of psychological foundation and their implausible predictions. Second, we discuss implications of dynamic preference models for recommendation systems evaluation and design. In an example, we show that engagement and diversity metrics may be unable to capture desirable recommendation system performance.
Plenoxels: Radiance Fields without Neural Networks
Dec 09, 2021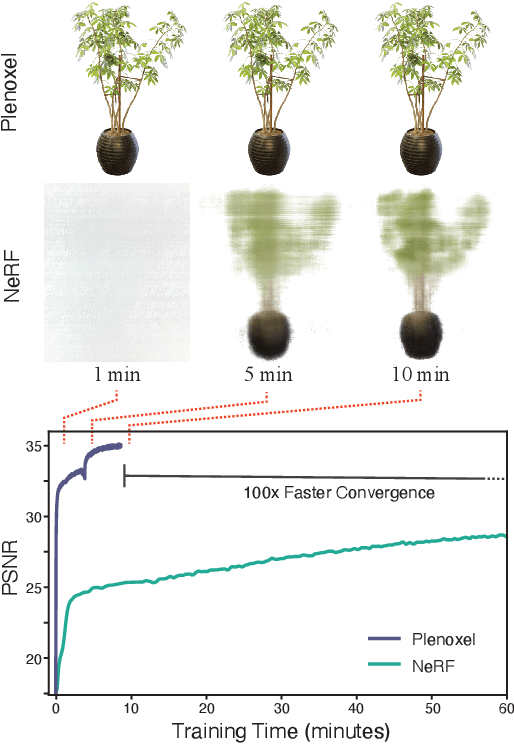
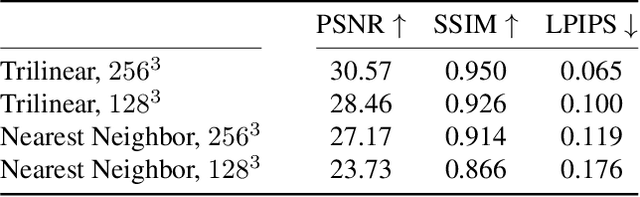
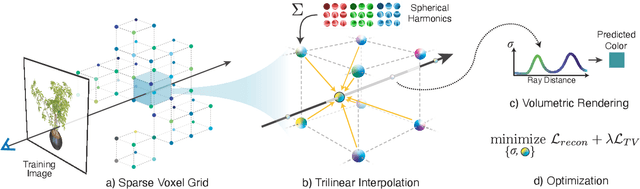
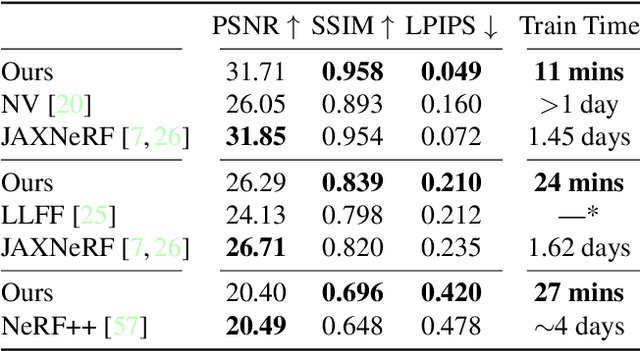
We introduce Plenoxels (plenoptic voxels), a system for photorealistic view synthesis. Plenoxels represent a scene as a sparse 3D grid with spherical harmonics. This representation can be optimized from calibrated images via gradient methods and regularization without any neural components. On standard, benchmark tasks, Plenoxels are optimized two orders of magnitude faster than Neural Radiance Fields with no loss in visual quality.
Quantifying Availability and Discovery in Recommender Systems via Stochastic Reachability
Jun 30, 2021
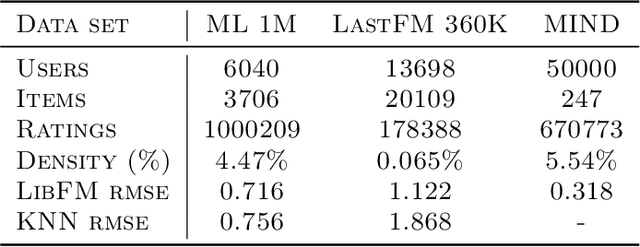
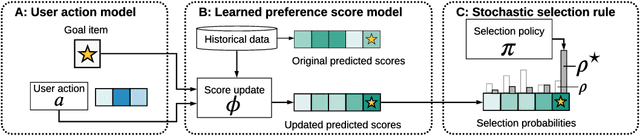
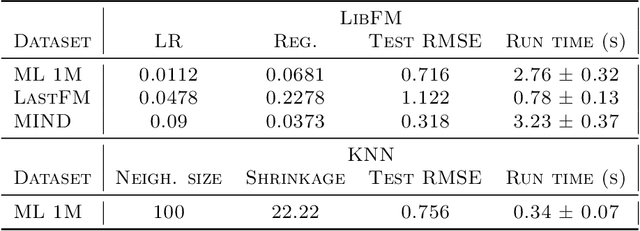
In this work, we consider how preference models in interactive recommendation systems determine the availability of content and users' opportunities for discovery. We propose an evaluation procedure based on stochastic reachability to quantify the maximum probability of recommending a target piece of content to an user for a set of allowable strategic modifications. This framework allows us to compute an upper bound on the likelihood of recommendation with minimal assumptions about user behavior. Stochastic reachability can be used to detect biases in the availability of content and diagnose limitations in the opportunities for discovery granted to users. We show that this metric can be computed efficiently as a convex program for a variety of practical settings, and further argue that reachability is not inherently at odds with accuracy. We demonstrate evaluations of recommendation algorithms trained on large datasets of explicit and implicit ratings. Our results illustrate how preference models, selection rules, and user interventions impact reachability and how these effects can be distributed unevenly.
Representation Matters: Assessing the Importance of Subgroup Allocations in Training Data
Mar 05, 2021
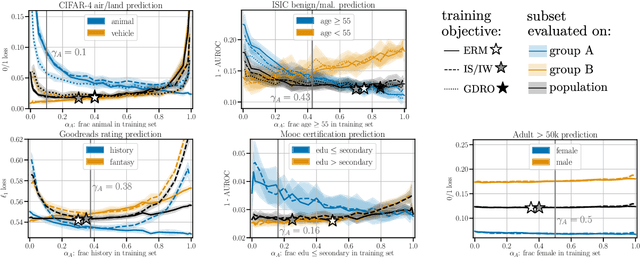
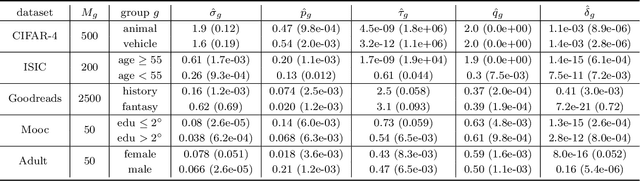
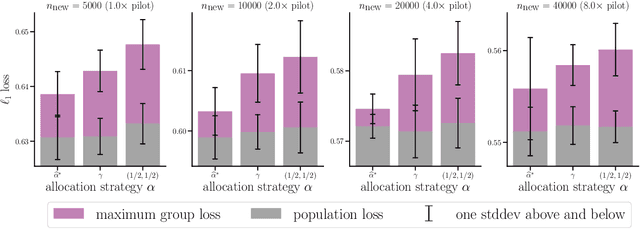
Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design.
Patterns, predictions, and actions: A story about machine learning
Feb 10, 2021


This graduate textbook on machine learning tells a story of how patterns in data support predictions and consequential actions. Starting with the foundations of decision making, we cover representation, optimization, and generalization as the constituents of supervised learning. A chapter on datasets as benchmarks examines their histories and scientific bases. Self-contained introductions to causality, the practice of causal inference, sequential decision making, and reinforcement learning equip the reader with concepts and tools to reason about actions and their consequences. Throughout, the text discusses historical context and societal impact. We invite readers from all backgrounds; some experience with probability, calculus, and linear algebra suffices.