 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit-assigned Policy Gradient for Early Stage Retrieval in Two-stage Ranking
May 25, 2026Large-scale search, recommendation, and retrieval-augmented generation (RAG) systems typically employ a two-stage architecture: an early-stage ranker (ESR) generates a candidate set, which is subsequently re-ranked by a late-stage ranker (LSR). While there are many reinforcement learning (RL) methods for training the LSR, end-to-end training of the ESR has proven challenging. In particular, naive application of "vanilla" policy gradient (V-PG) is not scalable for candidate-set sizes relevant for practical use due to exploding variance. This issue arises because V-PG propagates the gradient to the joint probability of the candidate sets, ignoring the contribution of each specific item in the candidate set to the reward. To mitigate this issue, we propose a novel "credit-assigned" policy gradient (CA-PG), which computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e. marginalizing over all candidate sets that contain it. Our theoretical analysis reveals that CA-PG significantly reduces the variance of V-PG by marginalizing over the specific composition of the candidate set, while preserving the ability to learn the correct ranking of items under a reasonably aligned LSR policy. Experiments on both synthetic and real-world data demonstrate that CA-PG improves the convergence speed and training stability for ESRs utilizing the canonical Plackett-Luce model, especially when the candidate-set size is large.
Initializing Services in Interactive ML Systems for Diverse Users
Dec 19, 2023This paper studies ML systems that interactively learn from users across multiple subpopulations with heterogeneous data distributions. The primary objective is to provide specialized services for different user groups while also predicting user preferences. Once the users select a service based on how well the service anticipated their preference, the services subsequently adapt and refine themselves based on the user data they accumulate, resulting in an iterative, alternating minimization process between users and services (learning dynamics). Employing such tailored approaches has two main challenges: (i) Unknown user preferences: Typically, data on user preferences are unavailable without interaction, and uniform data collection across a large and diverse user base can be prohibitively expensive. (ii) Suboptimal Local Solutions: The total loss (sum of loss functions across all users and all services) landscape is not convex even if the individual losses on a single service are convex, making it likely for the learning dynamics to get stuck in local minima. The final outcome of the aforementioned learning dynamics is thus strongly influenced by the initial set of services offered to users, and is not guaranteed to be close to the globally optimal outcome. In this work, we propose a randomized algorithm to adaptively select very few users to collect preference data from, while simultaneously initializing a set of services. We prove that under mild assumptions on the loss functions, the expected total loss achieved by the algorithm right after initialization is within a factor of the globally optimal total loss with complete user preference data, and this factor scales only logarithmically in the number of services. Our theory is complemented by experiments on real as well as semi-synthetic datasets.
Private Matrix Factorization with Public Item Features
Sep 17, 2023



We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
Delayed and Indirect Impacts of Link Recommendations
Mar 17, 2023



The impacts of link recommendations on social networks are challenging to evaluate, and so far they have been studied in limited settings. Observational studies are restricted in the kinds of causal questions they can answer and naive A/B tests often lead to biased evaluations due to unaccounted network interference. Furthermore, evaluations in simulation settings are often limited to static network models that do not take into account the potential feedback loops between link recommendation and organic network evolution. To this end, we study the impacts of recommendations on social networks in dynamic settings. Adopting a simulation-based approach, we consider an explicit dynamic formation model -- an extension of the celebrated Jackson-Rogers model -- and investigate how link recommendations affect network evolution over time. Empirically, we find that link recommendations have surprising delayed and indirect effects on the structural properties of networks. Specifically, we find that link recommendations can exhibit considerably different impacts in the immediate term and in the long term. For instance, we observe that friend-of-friend recommendations can have an immediate effect in decreasing degree inequality, but in the long term, they can make the degree distribution substantially more unequal. Moreover, we show that the effects of recommendations can persist in networks, in part due to their indirect impacts on natural dynamics even after recommendations are turned off. We show that, in counterfactual simulations, removing the indirect effects of link recommendations can make the network trend faster toward what it would have been under natural growth dynamics.
Towards Psychologically-Grounded Dynamic Preference Models
Aug 06, 2022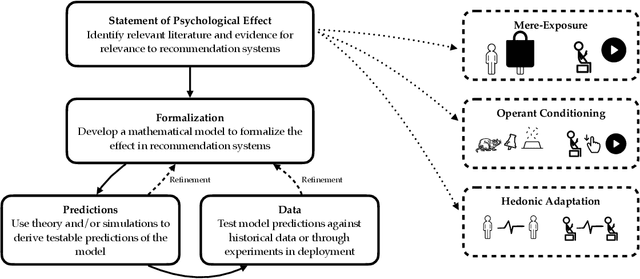
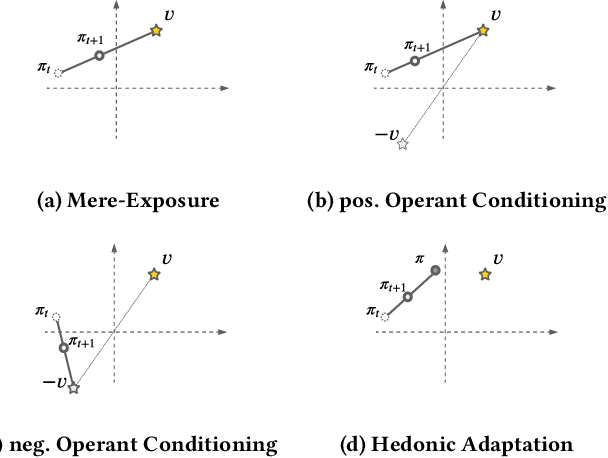
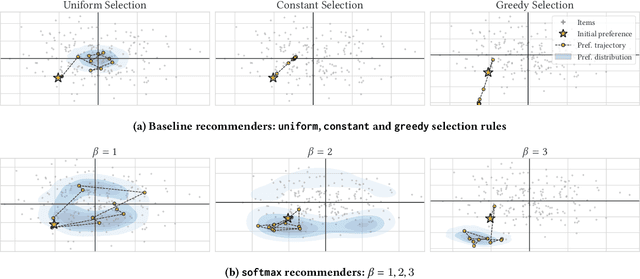
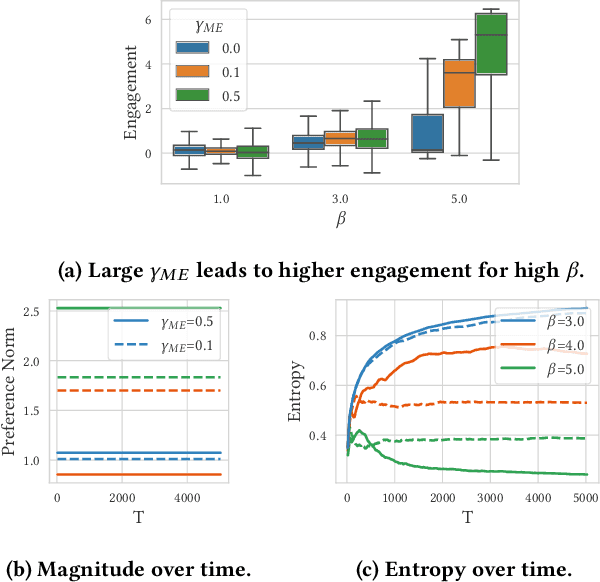
Designing recommendation systems that serve content aligned with time varying preferences requires proper accounting of the feedback effects of recommendations on human behavior and psychological condition. We argue that modeling the influence of recommendations on people's preferences must be grounded in psychologically plausible models. We contribute a methodology for developing grounded dynamic preference models. We demonstrate this method with models that capture three classic effects from the psychology literature: Mere-Exposure, Operant Conditioning, and Hedonic Adaptation. We conduct simulation-based studies to show that the psychological models manifest distinct behaviors that can inform system design. Our study has two direct implications for dynamic user modeling in recommendation systems. First, the methodology we outline is broadly applicable for psychologically grounding dynamic preference models. It allows us to critique recent contributions based on their limited discussion of psychological foundation and their implausible predictions. Second, we discuss implications of dynamic preference models for recommendation systems evaluation and design. In an example, we show that engagement and diversity metrics may be unable to capture desirable recommendation system performance.
Multi-learner risk reduction under endogenous participation dynamics
Jun 06, 2022
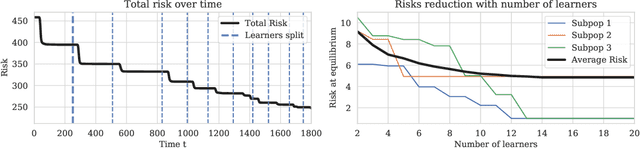
Prediction systems face exogenous and endogenous distribution shift -- the world constantly changes, and the predictions the system makes change the environment in which it operates. For example, a music recommender observes exogeneous changes in the user distribution as different communities have increased access to high speed internet. If users under the age of 18 enjoy their recommendations, the proportion of the user base comprised of those under 18 may endogeneously increase. Most of the study of endogenous shifts has focused on the single decision-maker setting, where there is one learner that users either choose to use or not. This paper studies participation dynamics between sub-populations and possibly many learners. We study the behavior of systems with \emph{risk-reducing} learners and sub-populations. A risk-reducing learner updates their decision upon observing a mixture distribution of the sub-populations $\mathcal{D}$ in such a way that it decreases the risk of the learner on that mixture. A risk reducing sub-population updates its apportionment amongst learners in a way which reduces its overall loss. Previous work on the single learner case shows that myopic risk minimization can result in high overall loss~\citep{perdomo2020performative, miller2021outside} and representation disparity~\citep{hashimoto2018fairness, zhang2019group}. Our work analyzes the outcomes of multiple myopic learners and market forces, often leading to better global loss and less representation disparity.
Quantifying Availability and Discovery in Recommender Systems via Stochastic Reachability
Jun 30, 2021
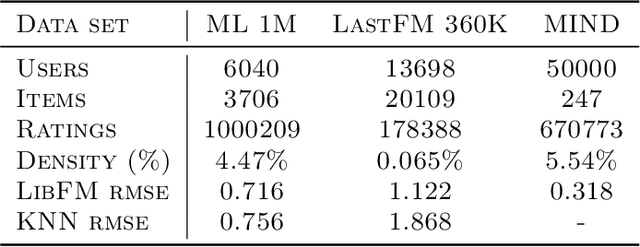
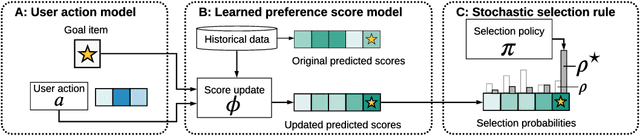
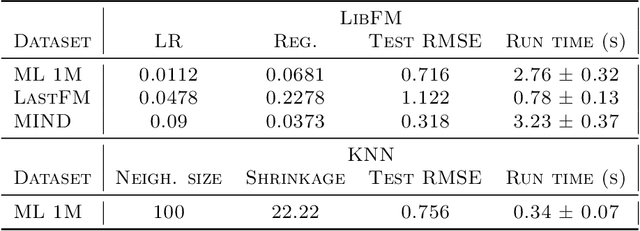
In this work, we consider how preference models in interactive recommendation systems determine the availability of content and users' opportunities for discovery. We propose an evaluation procedure based on stochastic reachability to quantify the maximum probability of recommending a target piece of content to an user for a set of allowable strategic modifications. This framework allows us to compute an upper bound on the likelihood of recommendation with minimal assumptions about user behavior. Stochastic reachability can be used to detect biases in the availability of content and diagnose limitations in the opportunities for discovery granted to users. We show that this metric can be computed efficiently as a convex program for a variety of practical settings, and further argue that reachability is not inherently at odds with accuracy. We demonstrate evaluations of recommendation algorithms trained on large datasets of explicit and implicit ratings. Our results illustrate how preference models, selection rules, and user interventions impact reachability and how these effects can be distributed unevenly.
Do Offline Metrics Predict Online Performance in Recommender Systems?
Nov 07, 2020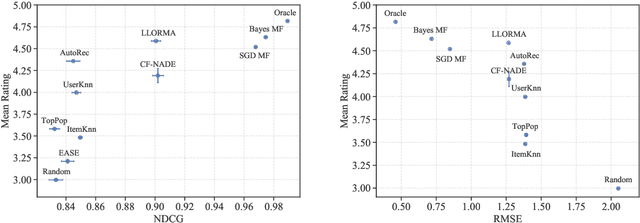
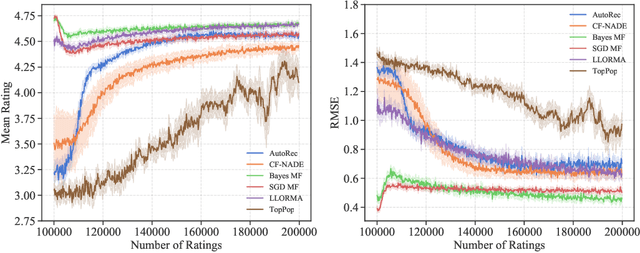
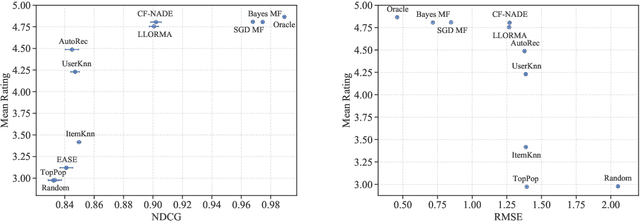
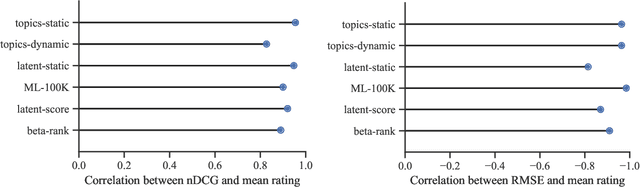
Recommender systems operate in an inherently dynamical setting. Past recommendations influence future behavior, including which data points are observed and how user preferences change. However, experimenting in production systems with real user dynamics is often infeasible, and existing simulation-based approaches have limited scale. As a result, many state-of-the-art algorithms are designed to solve supervised learning problems, and progress is judged only by offline metrics. In this work we investigate the extent to which offline metrics predict online performance by evaluating eleven recommenders across six controlled simulated environments. We observe that offline metrics are correlated with online performance over a range of environments. However, improvements in offline metrics lead to diminishing returns in online performance. Furthermore, we observe that the ranking of recommenders varies depending on the amount of initial offline data available. We study the impact of adding exploration strategies, and observe that their effectiveness, when compared to greedy recommendation, is highly dependent on the recommendation algorithm. We provide the environments and recommenders described in this paper as Reclab: an extensible ready-to-use simulation framework at https://github.com/berkeley-reclab/RecLab.