 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
Decentralized Diffusion Models
Jan 10, 2025Large-scale AI model training divides work across thousands of GPUs, then synchronizes gradients across them at each step. This incurs a significant network burden that only centralized, monolithic clusters can support, driving up infrastructure costs and straining power systems. We propose Decentralized Diffusion Models, a scalable framework for distributing diffusion model training across independent clusters or datacenters by eliminating the dependence on a centralized, high-bandwidth networking fabric. Our method trains a set of expert diffusion models over partitions of the dataset, each in full isolation from one another. At inference time, the experts ensemble through a lightweight router. We show that the ensemble collectively optimizes the same objective as a single model trained over the whole dataset. This means we can divide the training burden among a number of "compute islands," lowering infrastructure costs and improving resilience to localized GPU failures. Decentralized diffusion models empower researchers to take advantage of smaller, more cost-effective and more readily available compute like on-demand GPU nodes rather than central integrated systems. We conduct extensive experiments on ImageNet and LAION Aesthetics, showing that decentralized diffusion models FLOP-for-FLOP outperform standard diffusion models. We finally scale our approach to 24 billion parameters, demonstrating that high-quality diffusion models can now be trained with just eight individual GPU nodes in less than a week.
gsplat: An Open-Source Library for Gaussian Splatting
Sep 10, 2024gsplat is an open-source library designed for training and developing Gaussian Splatting methods. It features a front-end with Python bindings compatible with the PyTorch library and a back-end with highly optimized CUDA kernels. gsplat offers numerous features that enhance the optimization of Gaussian Splatting models, which include optimization improvements for speed, memory, and convergence times. Experimental results demonstrate that gsplat achieves up to 10% less training time and 4x less memory than the original implementation. Utilized in several research projects, gsplat is actively maintained on GitHub. Source code is available at https://github.com/nerfstudio-project/gsplat under Apache License 2.0. We welcome contributions from the open-source community.
GARField: Group Anything with Radiance Fields
Jan 17, 2024



Grouping is inherently ambiguous due to the multiple levels of granularity in which one can decompose a scene -- should the wheels of an excavator be considered separate or part of the whole? We present Group Anything with Radiance Fields (GARField), an approach for decomposing 3D scenes into a hierarchy of semantically meaningful groups from posed image inputs. To do this we embrace group ambiguity through physical scale: by optimizing a scale-conditioned 3D affinity feature field, a point in the world can belong to different groups of different sizes. We optimize this field from a set of 2D masks provided by Segment Anything (SAM) in a way that respects coarse-to-fine hierarchy, using scale to consistently fuse conflicting masks from different viewpoints. From this field we can derive a hierarchy of possible groupings via automatic tree construction or user interaction. We evaluate GARField on a variety of in-the-wild scenes and find it effectively extracts groups at many levels: clusters of objects, objects, and various subparts. GARField inherently represents multi-view consistent groupings and produces higher fidelity groups than the input SAM masks. GARField's hierarchical grouping could have exciting downstream applications such as 3D asset extraction or dynamic scene understanding. See the project website at https://www.garfield.studio/
NerfAcc: Efficient Sampling Accelerates NeRFs
May 08, 2023Optimizing and rendering Neural Radiance Fields is computationally expensive due to the vast number of samples required by volume rendering. Recent works have included alternative sampling approaches to help accelerate their methods, however, they are often not the focus of the work. In this paper, we investigate and compare multiple sampling approaches and demonstrate that improved sampling is generally applicable across NeRF variants under an unified concept of transmittance estimator. To facilitate future experiments, we develop NerfAcc, a Python toolbox that provides flexible APIs for incorporating advanced sampling methods into NeRF related methods. We demonstrate its flexibility by showing that it can reduce the training time of several recent NeRF methods by 1.5x to 20x with minimal modifications to the existing codebase. Additionally, highly customized NeRFs, such as Instant-NGP, can be implemented in native PyTorch using NerfAcc.
Nerfbusters: Removing Ghostly Artifacts from Casually Captured NeRFs
Apr 21, 2023Casually captured Neural Radiance Fields (NeRFs) suffer from artifacts such as floaters or flawed geometry when rendered outside the camera trajectory. Existing evaluation protocols often do not capture these effects, since they usually only assess image quality at every 8th frame of the training capture. To push forward progress in novel-view synthesis, we propose a new dataset and evaluation procedure, where two camera trajectories are recorded of the scene: one used for training, and the other for evaluation. In this more challenging in-the-wild setting, we find that existing hand-crafted regularizers do not remove floaters nor improve scene geometry. Thus, we propose a 3D diffusion-based method that leverages local 3D priors and a novel density-based score distillation sampling loss to discourage artifacts during NeRF optimization. We show that this data-driven prior removes floaters and improves scene geometry for casual captures.
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
Mar 22, 2023We propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an image-conditioned diffusion model (InstructPix2Pix) to iteratively edit the input images while optimizing the underlying scene, resulting in an optimized 3D scene that respects the edit instruction. We demonstrate that our proposed method is able to edit large-scale, real-world scenes, and is able to accomplish more realistic, targeted edits than prior work.
LERF: Language Embedded Radiance Fields
Mar 16, 2023Humans describe the physical world using natural language to refer to specific 3D locations based on a vast range of properties: visual appearance, semantics, abstract associations, or actionable affordances. In this work we propose Language Embedded Radiance Fields (LERFs), a method for grounding language embeddings from off-the-shelf models like CLIP into NeRF, which enable these types of open-ended language queries in 3D. LERF learns a dense, multi-scale language field inside NeRF by volume rendering CLIP embeddings along training rays, supervising these embeddings across training views to provide multi-view consistency and smooth the underlying language field. After optimization, LERF can extract 3D relevancy maps for a broad range of language prompts interactively in real-time, which has potential use cases in robotics, understanding vision-language models, and interacting with 3D scenes. LERF enables pixel-aligned, zero-shot queries on the distilled 3D CLIP embeddings without relying on region proposals or masks, supporting long-tail open-vocabulary queries hierarchically across the volume. The project website can be found at https://lerf.io .
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023



Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.
NerfAcc: A General NeRF Acceleration Toolbox
Oct 10, 2022


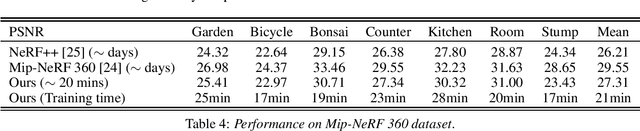
We propose NerfAcc, a toolbox for efficient volumetric rendering of radiance fields. We build on the techniques proposed in Instant-NGP, and extend these techniques to not only support bounded static scenes, but also for dynamic scenes and unbounded scenes. NerfAcc comes with a user-friendly Python API, and is ready for plug-and-play acceleration of most NeRFs. Various examples are provided to show how to use this toolbox. Code can be found here: https://github.com/KAIR-BAIR/nerfacc.