 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct-NeRF2NeRF: Editing 3D Scenes with Instructions
Mar 22, 2023We propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an image-conditioned diffusion model (InstructPix2Pix) to iteratively edit the input images while optimizing the underlying scene, resulting in an optimized 3D scene that respects the edit instruction. We demonstrate that our proposed method is able to edit large-scale, real-world scenes, and is able to accomplish more realistic, targeted edits than prior work.
Self-Supervised Contrastive Representation Learning for 3D Mesh Segmentation
Aug 08, 2022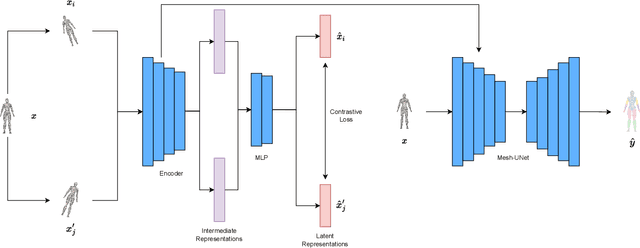
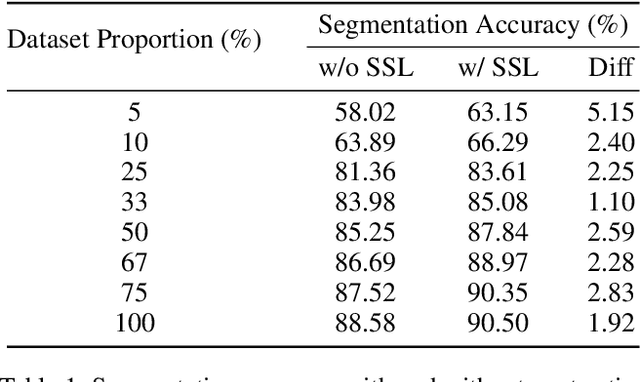
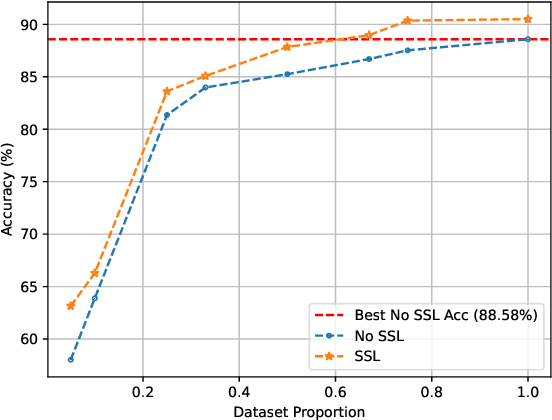
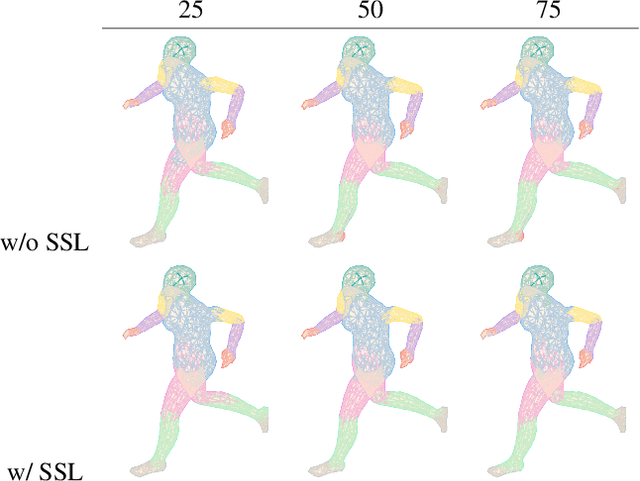
3D deep learning is a growing field of interest due to the vast amount of information stored in 3D formats. Triangular meshes are an efficient representation for irregular, non-uniform 3D objects. However, meshes are often challenging to annotate due to their high geometrical complexity. Specifically, creating segmentation masks for meshes is tedious and time-consuming. Therefore, it is desirable to train segmentation networks with limited-labeled data. Self-supervised learning (SSL), a form of unsupervised representation learning, is a growing alternative to fully-supervised learning which can decrease the burden of supervision for training. We propose SSL-MeshCNN, a self-supervised contrastive learning method for pre-training CNNs for mesh segmentation. We take inspiration from traditional contrastive learning frameworks to design a novel contrastive learning algorithm specifically for meshes. Our preliminary experiments show promising results in reducing the heavy labeled data requirement needed for mesh segmentation by at least 33%.
Generalized Multi-Task Learning from Substantially Unlabeled Multi-Source Medical Image Data
Oct 25, 2021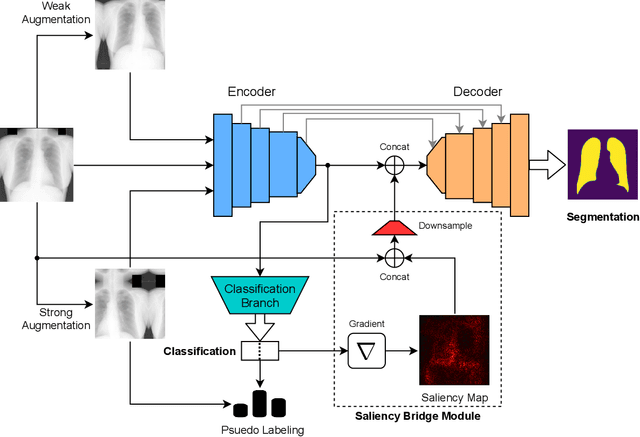

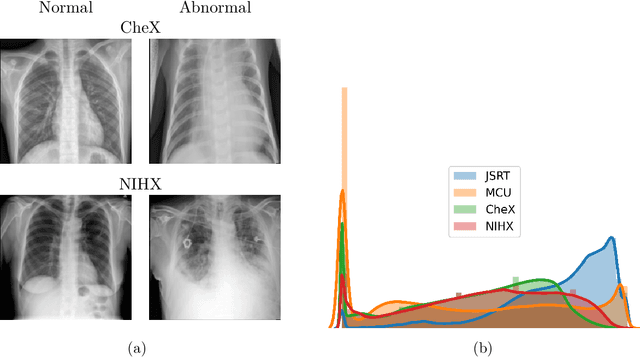
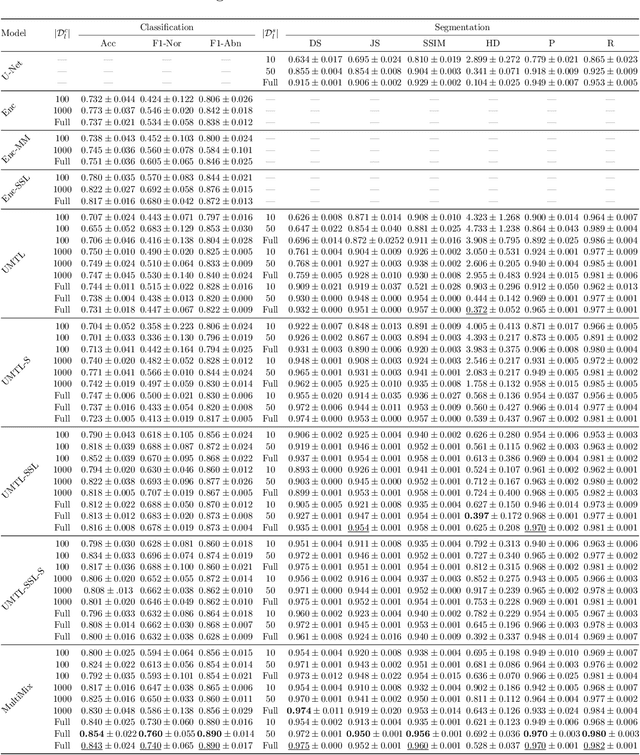
Deep learning-based models, when trained in a fully-supervised manner, can be effective in performing complex image analysis tasks, although contingent upon the availability of large labeled datasets. Especially in the medical imaging domain, however, expert image annotation is expensive, time-consuming, and prone to variability. Semi-supervised learning from limited quantities of labeled data has shown promise as an alternative. Maximizing knowledge gains from copious unlabeled data benefits semi-supervised learning models. Moreover, learning multiple tasks within the same model further improves its generalizability. We propose MultiMix, a new multi-task learning model that jointly learns disease classification and anatomical segmentation in a semi-supervised manner, while preserving explainability through a novel saliency bridge between the two tasks. Our experiments with varying quantities of multi-source labeled data in the training sets confirm the effectiveness of MultiMix in the simultaneous classification of pneumonia and segmentation of the lungs in chest X-ray images. Moreover, both in-domain and cross-domain evaluations across these tasks further showcase the potential of our model to adapt to challenging generalization scenarios.
3N-GAN: Semi-Supervised Classification of X-Ray Images with a 3-Player Adversarial Framework
Sep 22, 2021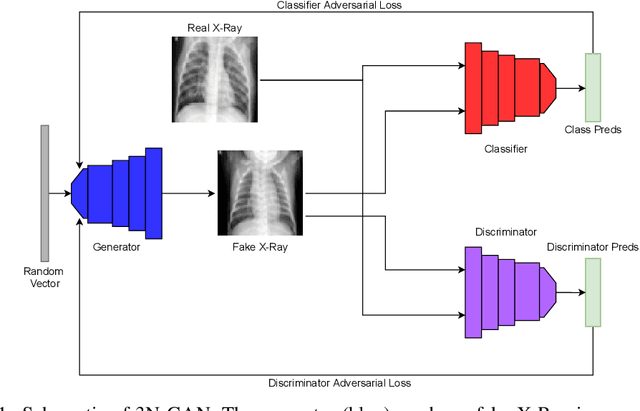
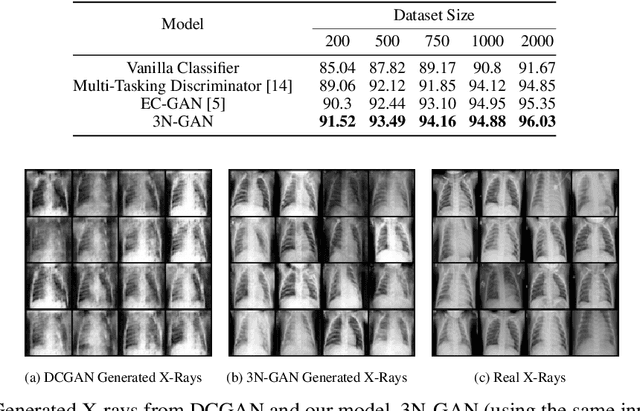
The success of deep learning for medical imaging tasks, such as classification, is heavily reliant on the availability of large-scale datasets. However, acquiring datasets with large quantities of labeled data is challenging, as labeling is expensive and time-consuming. Semi-supervised learning (SSL) is a growing alternative to fully-supervised learning, but requires unlabeled samples for training. In medical imaging, many datasets lack unlabeled data entirely, so SSL can't be conventionally utilized. We propose 3N-GAN, or 3 Network Generative Adversarial Networks, to perform semi-supervised classification of medical images in fully-supervised settings. We incorporate a classifier into the adversarial relationship such that the generator trains adversarially against both the classifier and discriminator. Our preliminary results show improved classification performance and GAN generations over various algorithms. Our work can seamlessly integrate with numerous other medical imaging model architectures and SSL methods for greater performance.
Convolutional Nets for Diabetic Retinopathy Screening in Bangladeshi Patients
Jul 31, 2021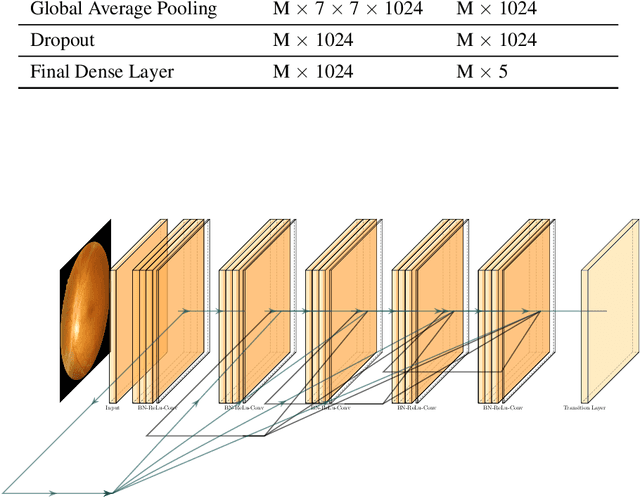
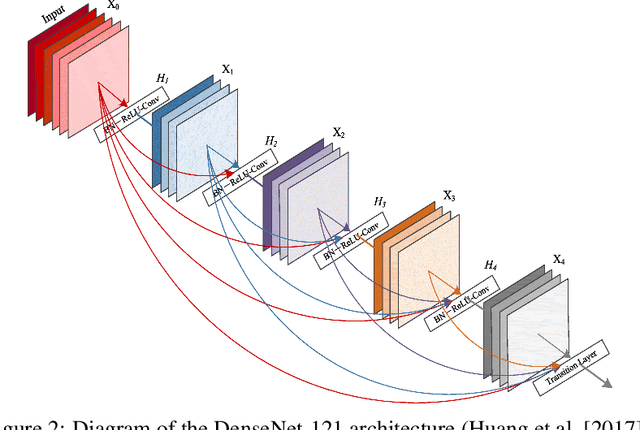
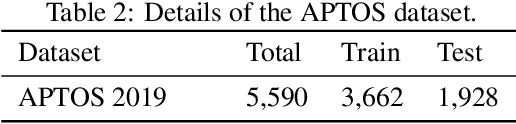
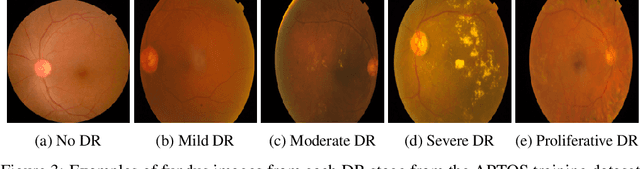
Diabetes is one of the most prevalent chronic diseases in Bangladesh, and as a result, Diabetic Retinopathy (DR) is widespread in the population. DR, an eye illness caused by diabetes, can lead to blindness if it is not identified and treated in its early stages. Unfortunately, diagnosis of DR requires medically trained professionals, but Bangladesh has limited specialists in comparison to its population. Moreover, the screening process is often expensive, prohibiting many from receiving timely and proper diagnosis. To address the problem, we introduce a deep learning algorithm which screens for different stages of DR. We use a state-of-the-art CNN architecture to diagnose patients based on retinal fundus imagery. This paper is an experimental evaluation of the algorithm we developed for DR diagnosis and screening specifically for Bangladeshi patients. We perform this validation study using separate pools of retinal image data of real patients from a hospital and field studies in Bangladesh. Our results show that the algorithm is effective at screening Bangladeshi eyes even when trained on a public dataset which is out of domain, and can accurately determine the stage of DR as well, achieving an overall accuracy of 92.27\% and 93.02\% on two validation sets of Bangladeshi eyes. The results confirm the ability of the algorithm to be used in real clinical settings and applications due to its high accuracy and classwise metrics. Our algorithm is implemented in the application Drishti, which is used to screen for DR in patients living in rural areas in Bangladesh, where access to professional screening is limited.
Simulated Data Generation Through Algorithmic Force Coefficient Estimation for AI-Based Robotic Projectile Launch Modeling
May 28, 2021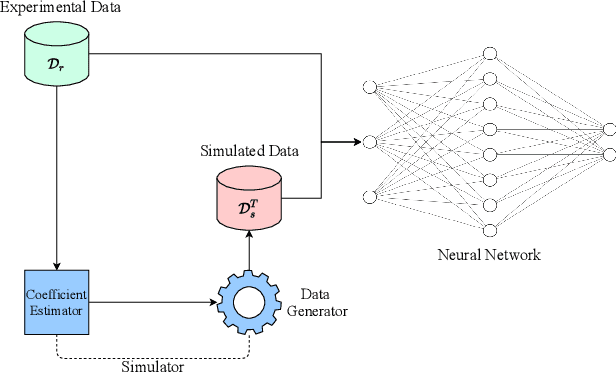
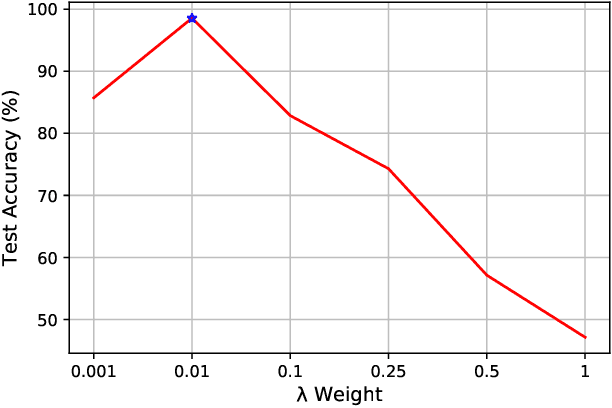
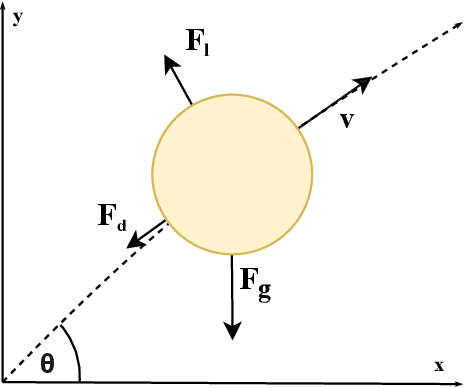
Modeling of non-rigid object launching and manipulation is complex considering the wide range of dynamics affecting trajectory, many of which may be unknown. Using physics models can be inaccurate because they cannot account for unknown factors and the effects of the deformation of the object as it is launched; moreover, deriving force coefficients for these models is not possible without extensive experimental testing. Recently, advancements in data-powered artificial intelligence methods have allowed learnable models and systems to emerge. It is desirable to train a model for launch prediction on a robot, as deep neural networks can account for immeasurable dynamics. However, the inability to collect large amounts of experimental data decreases performance of deep neural networks. Through estimating force coefficients, the accepted physics models can be leveraged to produce adequate supplemental data to artificially increase the size of the training set, yielding improved neural networks. In this paper, we introduce a new framework for algorithmic estimation of force coefficients for non-rigid object launching, which can be generalized to other domains, in order to generate large datasets. We implement a novel training algorithm and objective for our deep neural network to accurately model launch trajectory of non-rigid objects and predict whether they will hit a series of targets. Our experimental results demonstrate the effectiveness of using simulated data from force coefficient estimation and shows the importance of simulated data for training an effective neural network.
Window-Level is a Strong Denoising Surrogate
May 15, 2021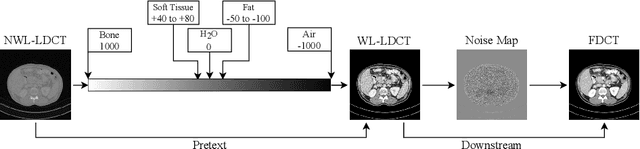

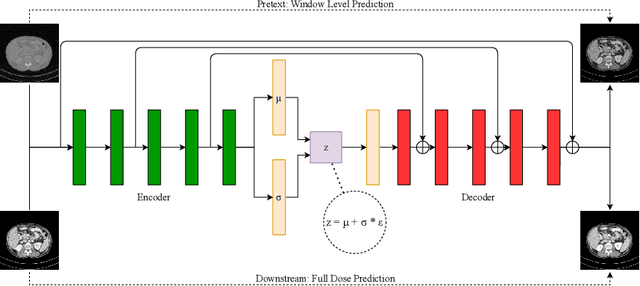
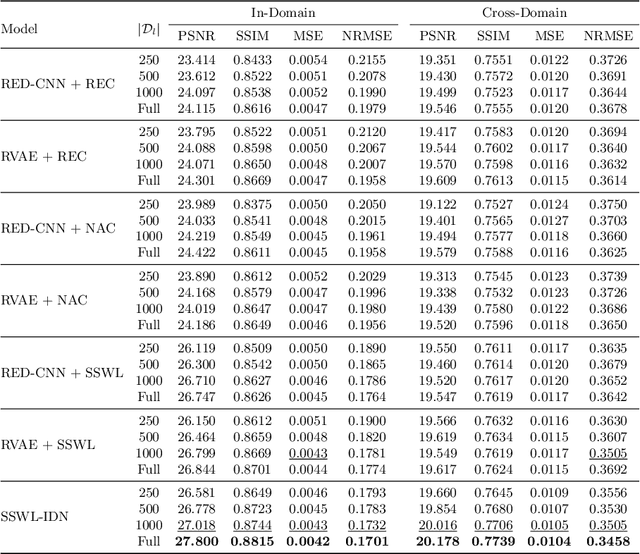
CT image quality is heavily reliant on radiation dose, which causes a trade-off between radiation dose and image quality that affects the subsequent image-based diagnostic performance. However, high radiation can be harmful to both patients and operators. Several (deep learning-based) approaches have been attempted to denoise low dose images. However, those approaches require access to large training sets, specifically the full dose CT images for reference, which can often be difficult to obtain. Self-supervised learning is an emerging alternative for lowering the reference data requirement facilitating unsupervised learning. Currently available self-supervised CT denoising works are either dependent on foreign domain or pretexts are not very task-relevant. To tackle the aforementioned challenges, we propose a novel self-supervised learning approach, namely Self-Supervised Window-Leveling for Image DeNoising (SSWL-IDN), leveraging an innovative, task-relevant, simple, yet effective surrogate -- prediction of the window-leveled equivalent. SSWL-IDN leverages residual learning and a hybrid loss combining perceptual loss and MSE, all incorporated in a VAE framework. Our extensive (in- and cross-domain) experimentation demonstrates the effectiveness of SSWL-IDN in aggressive denoising of CT (abdomen and chest) images acquired at 5\% dose level only.
Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction
Feb 18, 2021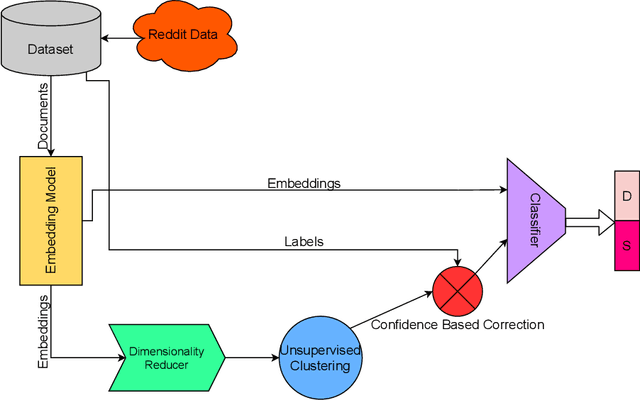
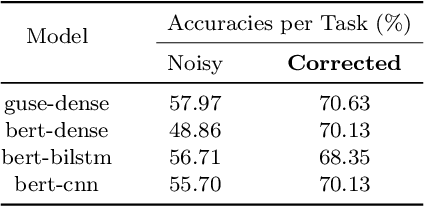


Early detection of suicidal ideation in depressed individuals can allow for adequate medical attention and support, which in many cases is life-saving. Recent NLP research focuses on classifying, from a given piece of text, if an individual is suicidal or clinically healthy. However, there have been no major attempts to differentiate between depression and suicidal ideation, which is an important clinical challenge. Due to the scarce availability of EHR data, suicide notes, or other similar verified sources, web query data has emerged as a promising alternative. Online sources, such as Reddit, allow for anonymity that prompts honest disclosure of symptoms, making it a plausible source even in a clinical setting. However, these online datasets also result in lower performance, which can be attributed to the inherent noise in web-scraped labels, which necessitates a noise-removal process. Thus, we propose SDCNL, a suicide versus depression classification method through a deep learning approach. We utilize online content from Reddit to train our algorithm, and to verify and correct noisy labels, we propose a novel unsupervised label correction method which, unlike previous work, does not require prior noise distribution information. Our extensive experimentation with multiple deep word embedding models and classifiers display the strong performance of the method in anew, challenging classification application. We make our code and dataset available at https://github.com/ayaanzhaque/SDCNL
EC-GAN: Low-Sample Classification using Semi-Supervised Algorithms and GANs
Dec 26, 2020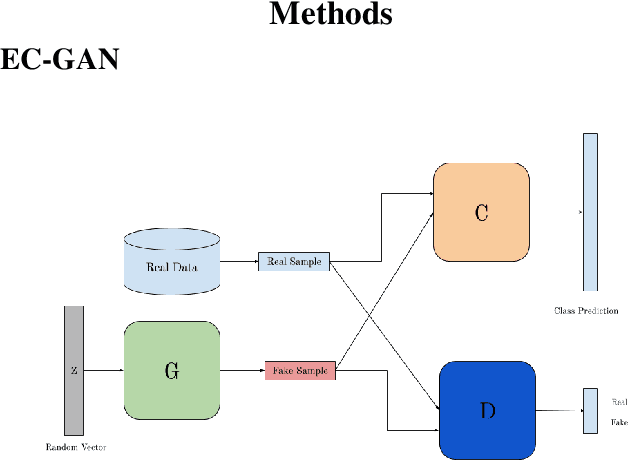
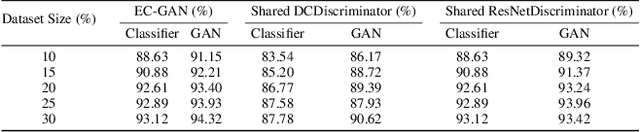

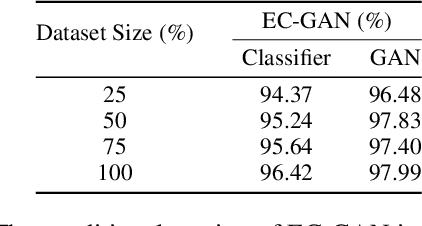
Semi-supervised learning has been gaining attention as it allows for performing image analysis tasks such as classification with limited labeled data. Some popular algorithms using Generative Adversarial Networks (GANs) for semi-supervised classification share a single architecture for classification and discrimination. However, this may require a model to converge to a separate data distribution for each task, which may reduce overall performance. While progress in semi-supervised learning has been made, less addressed are small-scale, fully-supervised tasks where even unlabeled data is unavailable and unattainable. We therefore, propose a novel GAN model namely External Classifier GAN (EC-GAN), that utilizes GANs and semi-supervised algorithms to improve classification in fully-supervised regimes. Our method leverages a GAN to generate artificial data used to supplement supervised classification. More specifically, we attach an external classifier, hence the name EC-GAN, to the GAN's generator, as opposed to sharing an architecture with the discriminator. Our experiments demonstrate that EC-GAN's performance is comparable to the shared architecture method, far superior to the standard data augmentation and regularization-based approach, and effective on a small, realistic dataset.
MultiMix: Sparingly Supervised, Extreme Multitask Learning From Medical Images
Oct 28, 2020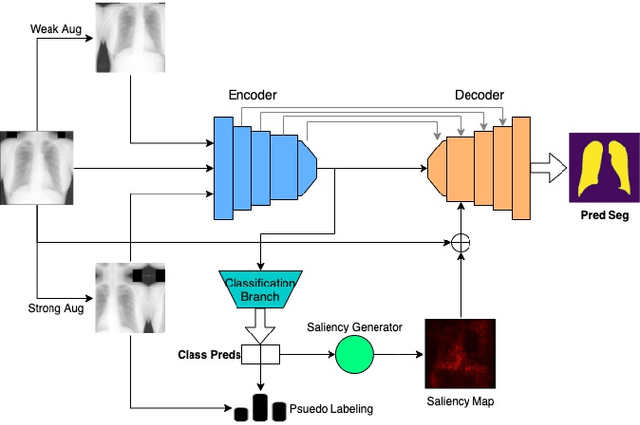
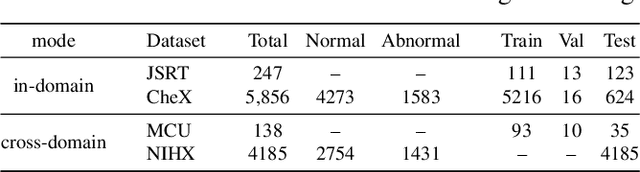


Semi-supervised learning via learning from limited quantities of labeled data has been investigated as an alternative to supervised counterparts. Maximizing knowledge gains from copious unlabeled data benefit semi-supervised learning settings. Moreover, learning multiple tasks within the same model further improves model generalizability. We propose a novel multitask learning model, namely MultiMix, which jointly learns disease classification and anatomical segmentation in a sparingly supervised manner, while preserving explainability through bridge saliency between the two tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justify the effectiveness of our multitasking model for the classification of pneumonia and segmentation of lungs from chest X-ray images. Moreover, both in-domain and cross-domain evaluations across the tasks further showcase the potential of our model to adapt to challenging generalization scenarios.