 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023



Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.
Rethinking Vision Transformers for MobileNet Size and Speed
Dec 15, 2022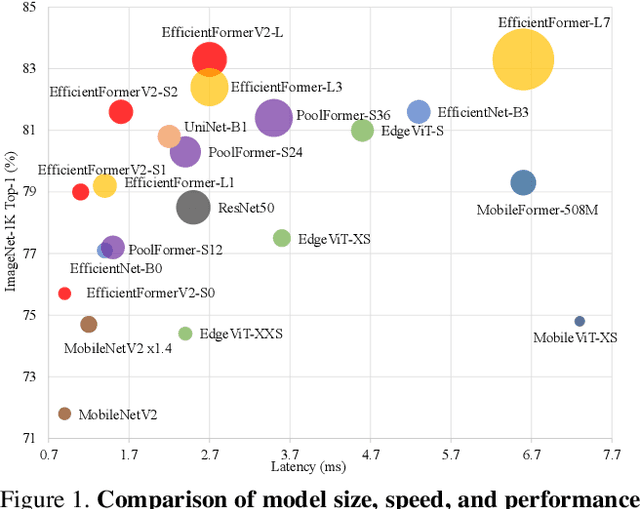



With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose an improved supernet with low latency and high parameter efficiency. We further introduce a fine-grained joint search strategy that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve about $4\%$ higher top-1 accuracy than MobileNetV2 and MobileNetV2$\times1.4$ on ImageNet-1K with similar latency and parameters. We demonstrate that properly designed and optimized vision transformers can achieve high performance with MobileNet-level size and speed.
Minimax Active Learning
Dec 18, 2020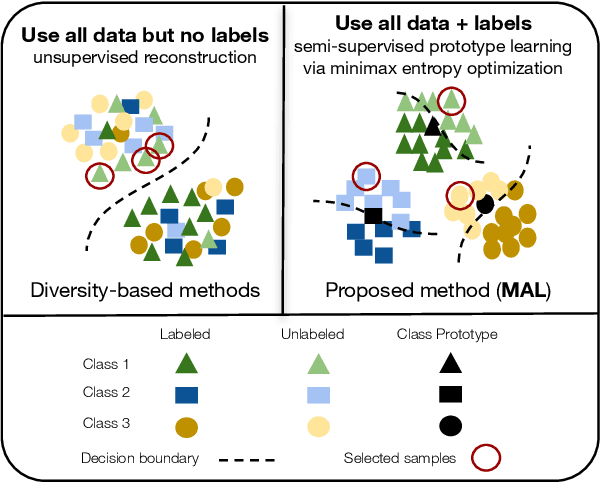
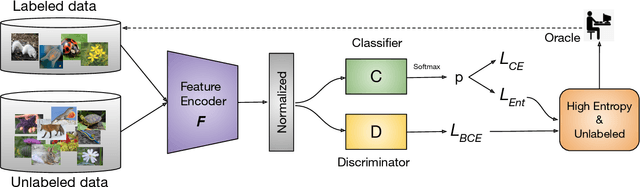

Active learning aims to develop label-efficient algorithms by querying the most representative samples to be labeled by a human annotator. Current active learning techniques either rely on model uncertainty to select the most uncertain samples or use clustering or reconstruction to choose the most diverse set of unlabeled examples. While uncertainty-based strategies are susceptible to outliers, solely relying on sample diversity does not capture the information available on the main task. In this work, we develop a semi-supervised minimax entropy-based active learning algorithm that leverages both uncertainty and diversity in an adversarial manner. Our model consists of an entropy minimizing feature encoding network followed by an entropy maximizing classification layer. This minimax formulation reduces the distribution gap between the labeled/unlabeled data, while a discriminator is simultaneously trained to distinguish the labeled/unlabeled data. The highest entropy samples from the classifier that the discriminator predicts as unlabeled are selected for labeling. We extensively evaluate our method on various image classification and semantic segmentation benchmark datasets and show superior performance over the state-of-the-art methods.