 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-ECC: Asynchronous Tracking of Events with Continuous Optimization
Sep 22, 2024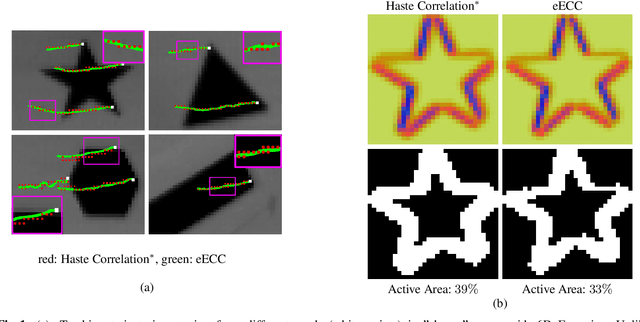



In this paper, an event-based tracker is presented. Inspired by recent advances in asynchronous processing of individual events, we develop a direct matching scheme that aligns spatial distributions of events at different times. More specifically, we adopt the Enhanced Correlation Coefficient (ECC) criterion and propose a tracking algorithm that computes a 2D motion warp per single event, called event-ECC (eECC). The complete tracking of a feature along time is cast as a \emph{single} iterative continuous optimization problem, whereby every single iteration is executed per event. The computational burden of event-wise processing is alleviated through a lightweight version that benefits from incremental processing and updating scheme. We test the proposed algorithm on publicly available datasets and we report improvements in tracking accuracy and feature age over state-of-the-art event-based asynchronous trackers.
Continuous Cost Aggregation for Dual-Pixel Disparity Extraction
Jun 13, 2023
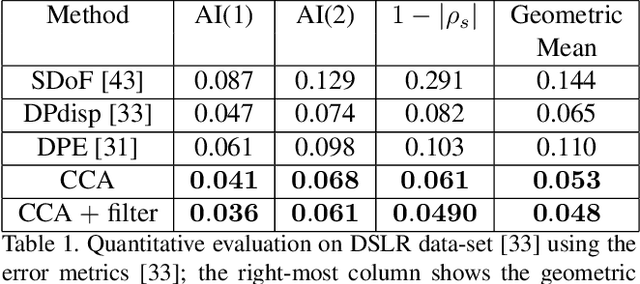
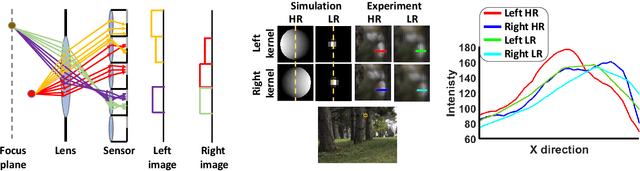

Recent works have shown that depth information can be obtained from Dual-Pixel (DP) sensors. A DP arrangement provides two views in a single shot, thus resembling a stereo image pair with a tiny baseline. However, the different point spread function (PSF) per view, as well as the small disparity range, makes the use of typical stereo matching algorithms problematic. To address the above shortcomings, we propose a Continuous Cost Aggregation (CCA) scheme within a semi-global matching framework that is able to provide accurate continuous disparities from DP images. The proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths. The aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs. This gives rise to an inherently efficient disparity propagation scheme with a pixel-wise minimization in closed-form. Furthermore, the continuous form allows for a robust multi-scale aggregation that better compensates for the varying PSF. Experiments on DP data from both DSLR and phone cameras show that the proposed scheme attains state-of-the-art performance in DP disparity estimation.
Rethinking Vision Transformers for MobileNet Size and Speed
Dec 15, 2022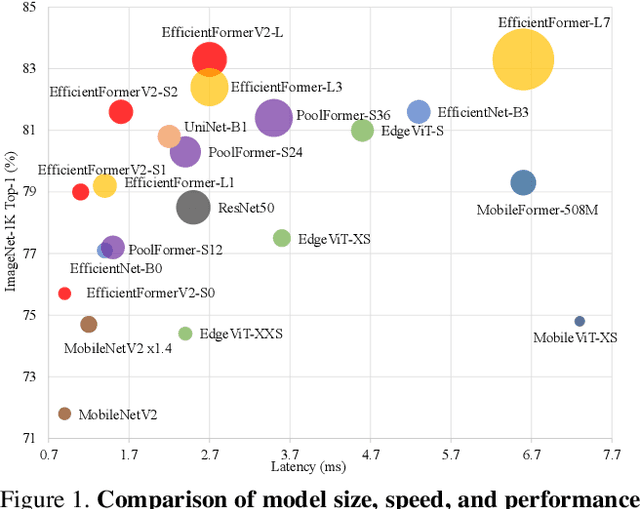



With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose an improved supernet with low latency and high parameter efficiency. We further introduce a fine-grained joint search strategy that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve about $4\%$ higher top-1 accuracy than MobileNetV2 and MobileNetV2$\times1.4$ on ImageNet-1K with similar latency and parameters. We demonstrate that properly designed and optimized vision transformers can achieve high performance with MobileNet-level size and speed.
EfficientFormer: Vision Transformers at MobileNet Speed
Jun 02, 2022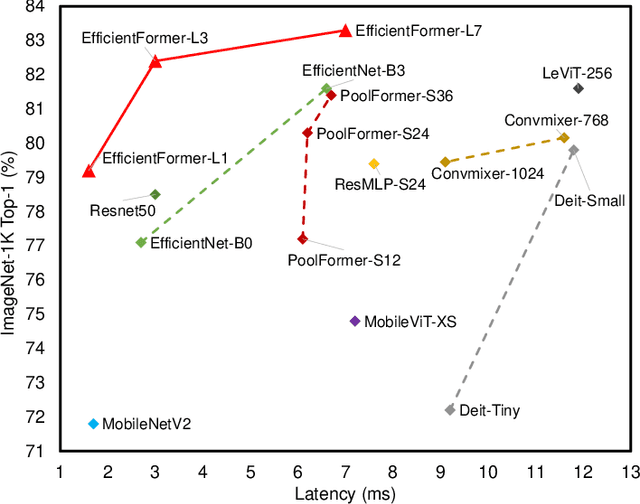
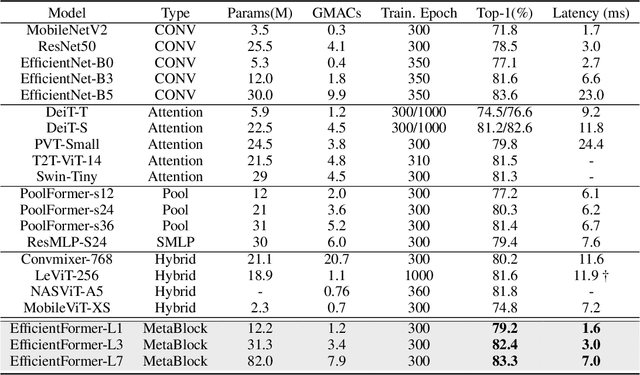
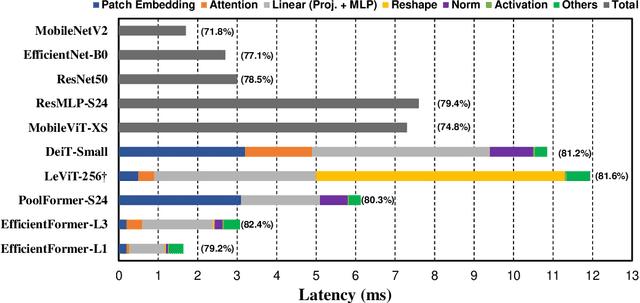
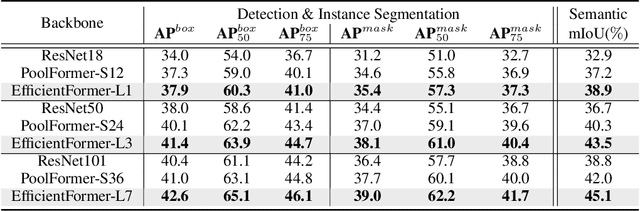
Vision Transformers (ViT) have shown rapid progress in computer vision tasks, achieving promising results on various benchmarks. However, due to the massive number of parameters and model design, e.g., attention mechanism, ViT-based models are generally times slower than lightweight convolutional networks. Therefore, the deployment of ViT for real-time applications is particularly challenging, especially on resource-constrained hardware such as mobile devices. Recent efforts try to reduce the computation complexity of ViT through network architecture search or hybrid design with MobileNet block, yet the inference speed is still unsatisfactory. This leads to an important question: can transformers run as fast as MobileNet while obtaining high performance? To answer this, we first revisit the network architecture and operators used in ViT-based models and identify inefficient designs. Then we introduce a dimension-consistent pure transformer (without MobileNet blocks) as design paradigm. Finally, we perform latency-driven slimming to get a series of final models dubbed EfficientFormer. Extensive experiments show the superiority of EfficientFormer in performance and speed on mobile devices. Our fastest model, EfficientFormer-L1, achieves 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on iPhone 12 (compiled with CoreML), which is even a bit faster than MobileNetV2 (1.7 ms, 71.8% top-1), and our largest model, EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency. Our work proves that properly designed transformers can reach extremely low latency on mobile devices while maintaining high performance
An Overview of Depth Cameras and Range Scanners Based on Time-of-Flight Technologies
Dec 12, 2020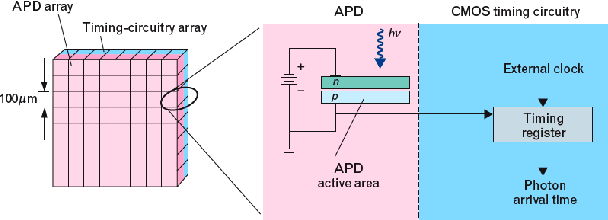



Time-of-flight (TOF) cameras are sensors that can measure the depths of scene-points, by illuminating the scene with a controlled laser or LED source, and then analyzing the reflected light. In this paper, we will first describe the underlying measurement principles of time-of-flight cameras, including: (i) pulsed-light cameras, which measure directly the time taken for a light pulse to travel from the device to the object and back again, and (ii) continuous-wave modulated-light cameras, which measure the phase difference between the emitted and received signals, and hence obtain the travel time indirectly. We review the main existing designs, including prototypes as well as commercially available devices. We also review the relevant camera calibration principles, and how they are applied to TOF devices. Finally, we discuss the benefits and challenges of combined TOF and color camera systems.
Ego-Motion Alignment from Face Detections for Collaborative Augmented Reality
Oct 05, 2020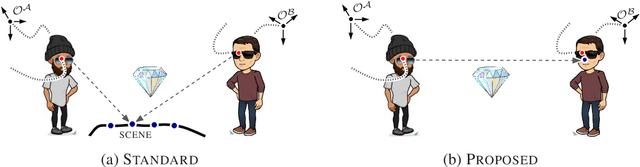

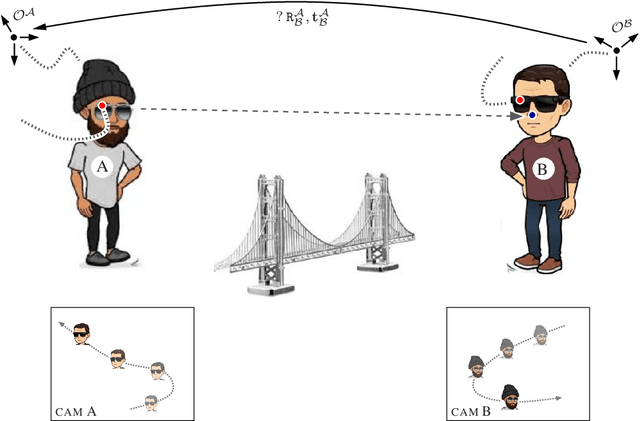
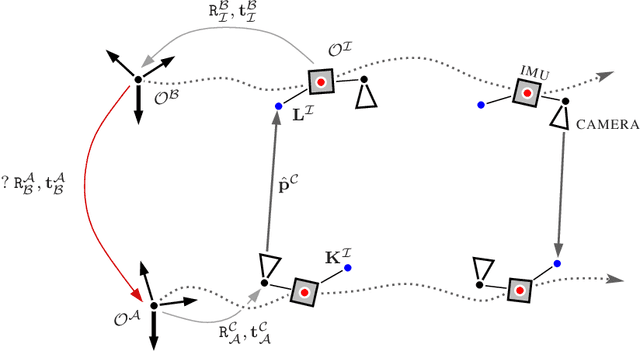
Sharing virtual content among multiple smart glasses wearers is an essential feature of a seamless Collaborative Augmented Reality experience. To enable the sharing, local coordinate systems of the underlying 6D ego-pose trackers, running independently on each set of glasses, have to be spatially and temporally aligned with respect to each other. In this paper, we propose a novel lightweight solution for this problem, which is referred as ego-motion alignment. We show that detecting each other's face or glasses together with tracker ego-poses sufficiently conditions the problem to spatially relate local coordinate systems. Importantly, the detected glasses can serve as reliable anchors to bring sufficient accuracy for the targeted practical use. The proposed idea allows us to abandon the traditional visual localization step with fiducial markers or scene points as anchors. A novel closed form minimal solver which solves a Quadratic Eigenvalue Problem is derived and its refinement with Gaussian Belief Propagation is introduced. Experiments validate the presented approach and show its high practical potential.
Renormalization for Initialization of Rolling Shutter Visual-Inertial Odometry
Aug 14, 2020

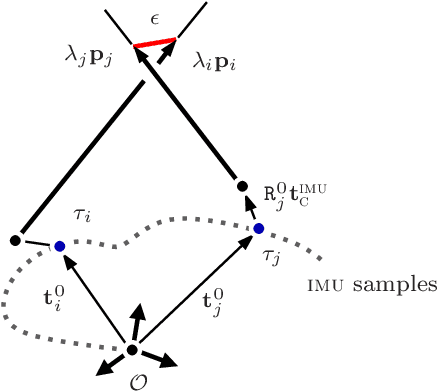
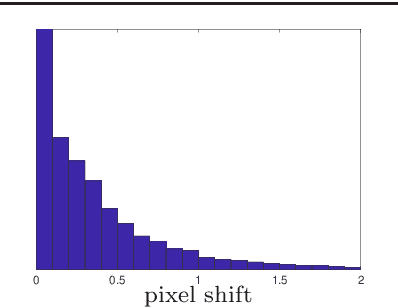
In this paper we deal with the initialization problem of a visual-inertial odometry system with rolling shutter cameras. The initialization is a prerequisite to utilize inertial signals and fuse them with the visual data. We propose a novel way to solve this problem on visual and inertial data simultaneously in a statistical sense, by casting it into the renormalization scheme of Kanatani. The renormalization is an optimization scheme which intends to reduce the inherent statistical bias of common linear systems. We derive and present necessary steps and methodology specific for the initialization problem. Extensive evaluations on perfect ground truth exhibit superior performance and up to 20% accuracy gain to the originally proposed Least Squares solution. The renormalization performs similarly to the optimal Maximum Likelihood estimate, despite arriving to the solution by different means. By this, we extend the set of common Computer Vision problems which can be cast into the renormalization scheme.
Revisiting visual-inertial structure from motion for odometry and SLAM initialization
Jun 10, 2020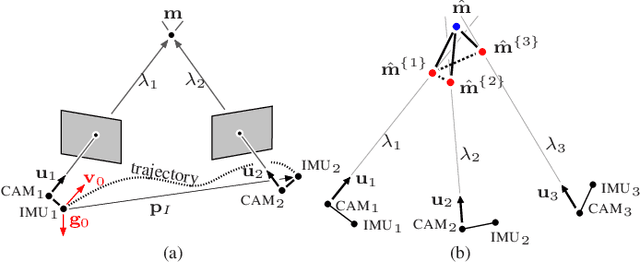

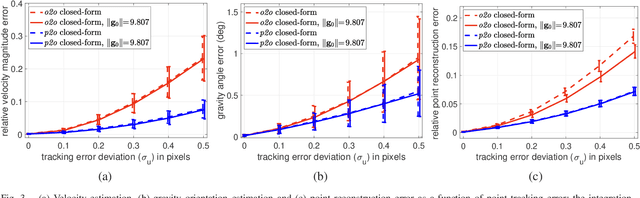
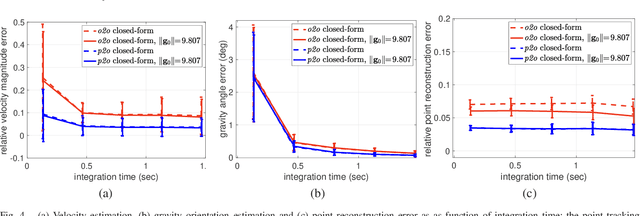
In this paper, an efficient closed-form solution for the state initialization in visual-inertial odometry (VIO) and simultaneous localization and mapping (SLAM) is presented. Unlike the state-of-the-art, we do not derive linear equations from triangulating pairs of point observations. Instead, we build on a direct triangulation of the unknown $3D$ point paired with each of its observations. We show and validate the high impact of such a simple difference. The resulting linear system has a simpler structure and the solution through analytic elimination only requires solving a $6\times 6$ linear system (or $9 \times 9$ when accelerometer bias is included). In addition, all the observations of every scene point are jointly related, thereby leading to a less biased and more robust solution. The proposed formulation attains up to $50$ percent decreased velocity and point reconstruction error compared to the standard closed-form solver. Apart from the inherent efficiency, fewer iterations are needed by any further non-linear refinement thanks to better parameter initialization. In this context, we provide the analytic Jacobians for a non-linear optimizer that optionally refines the initial parameters. The superior performance of the proposed solver is established by quantitative comparisons with the state-of-the-art solver.
Robust Head-Pose Estimation Based on Partially-Latent Mixture of Linear Regressions
Mar 06, 2017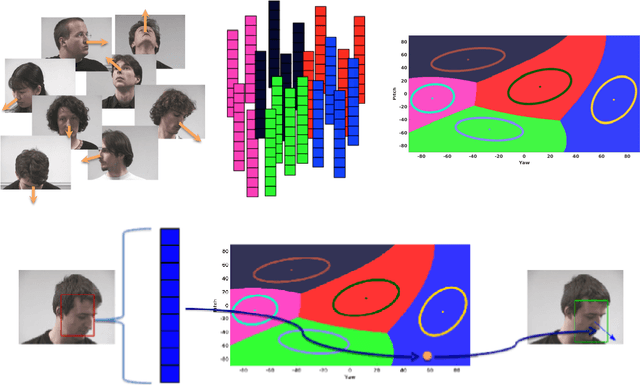
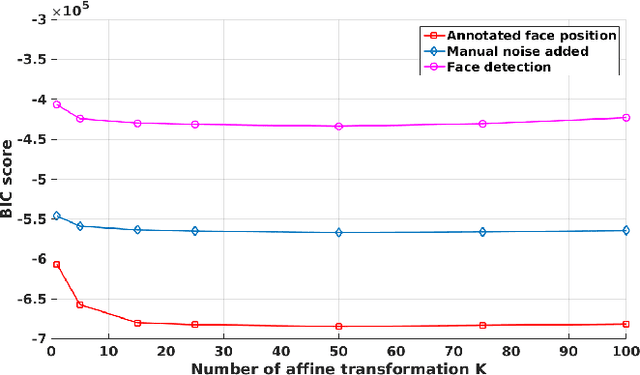
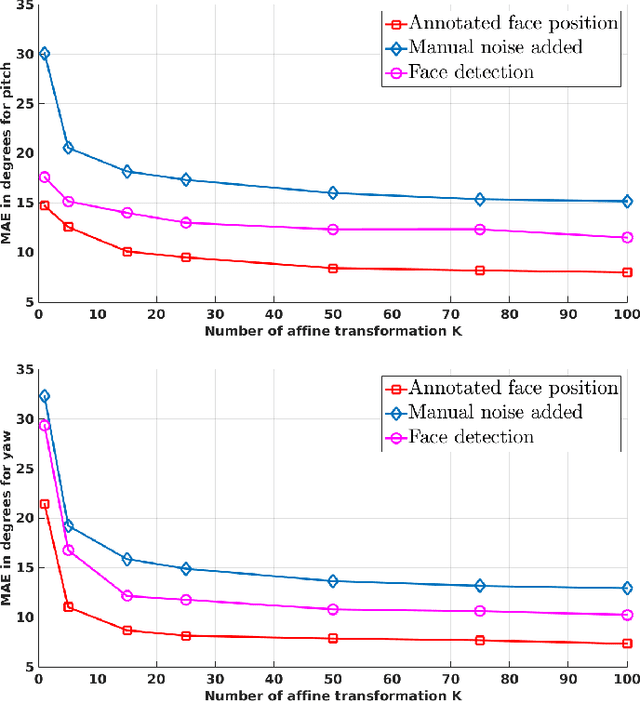

Head-pose estimation has many applications, such as social event analysis, human-robot and human-computer interaction, driving assistance, and so forth. Head-pose estimation is challenging because it must cope with changing illumination conditions, variabilities in face orientation and in appearance, partial occlusions of facial landmarks, as well as bounding-box-to-face alignment errors. We propose tu use a mixture of linear regressions with partially-latent output. This regression method learns to map high-dimensional feature vectors (extracted from bounding boxes of faces) onto the joint space of head-pose angles and bounding-box shifts, such that they are robustly predicted in the presence of unobservable phenomena. We describe in detail the mapping method that combines the merits of unsupervised manifold learning techniques and of mixtures of regressions. We validate our method with three publicly available datasets and we thoroughly benchmark four variants of the proposed algorithm with several state-of-the-art head-pose estimation methods.
* 12 pages, 5 figures, 3 tables
Joint Alignment of Multiple Point Sets with Batch and Incremental Expectation-Maximization
Mar 06, 2017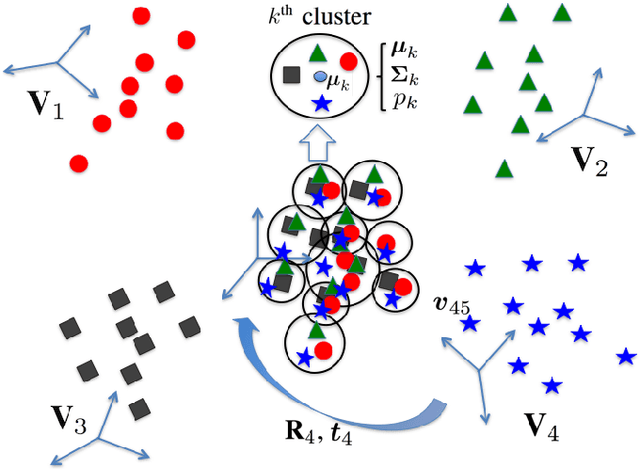



This paper addresses the problem of registering multiple point sets. Solutions to this problem are often approximated by repeatedly solving for pairwise registration, which results in an uneven treatment of the sets forming a pair: a model set and a data set. The main drawback of this strategy is that the model set may contain noise and outliers, which negatively affects the estimation of the registration parameters. In contrast, the proposed formulation treats all the point sets on an equal footing. Indeed, all the points are drawn from a central Gaussian mixture, hence the registration is cast into a clustering problem. We formally derive batch and incremental EM algorithms that robustly estimate both the GMM parameters and the rotations and translations that optimally align the sets. Moreover, the mixture's means play the role of the registered set of points while the variances provide rich information about the contribution of each component to the alignment. We thoroughly test the proposed algorithms on simulated data and on challenging real data collected with range sensors. We compare them with several state-of-the-art algorithms, and we show their potential for surface reconstruction from depth data.
* 14 pages, 12 figures, 5 tables