 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Gaze and Visual Focus of Attention of People Involved in Social Interaction
Nov 21, 2017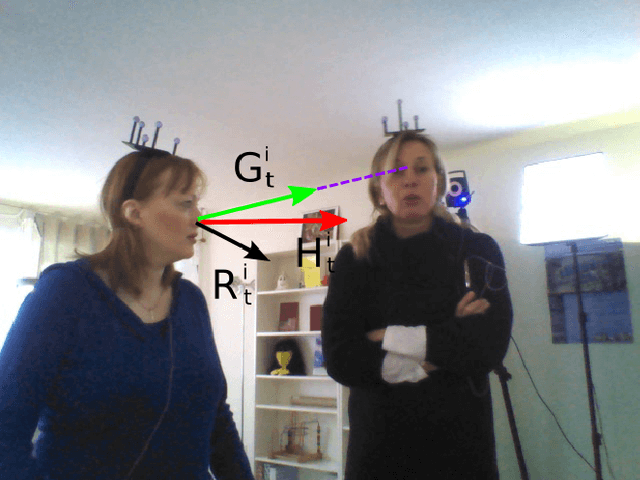
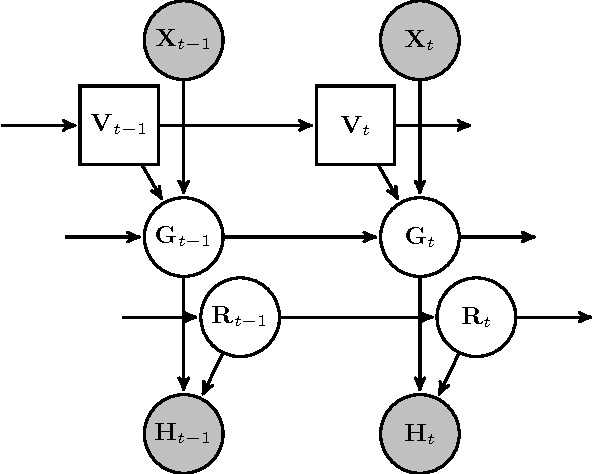
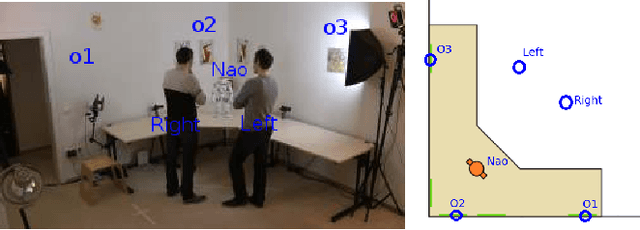
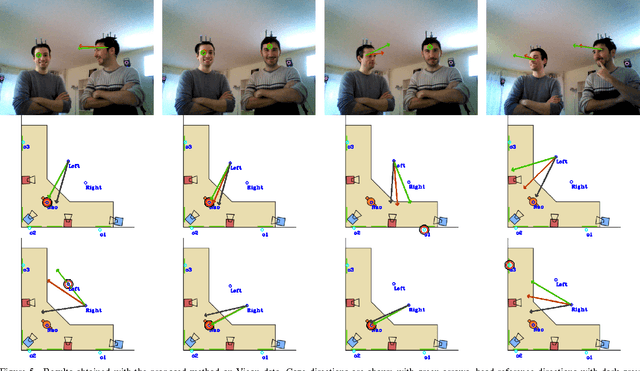
The visual focus of attention (VFOA) has been recognized as a prominent conversational cue. We are interested in estimating and tracking the VFOAs associated with multi-party social interactions. We note that in this type of situations the participants either look at each other or at an object of interest; therefore their eyes are not always visible. Consequently both gaze and VFOA estimation cannot be based on eye detection and tracking. We propose a method that exploits the correlation between eye gaze and head movements. Both VFOA and gaze are modeled as latent variables in a Bayesian switching state-space model. The proposed formulation leads to a tractable learning procedure and to an efficient algorithm that simultaneously tracks gaze and visual focus. The method is tested and benchmarked using two publicly available datasets that contain typical multi-party human-robot and human-human interactions.
* 15 pages, 8 figures, 6 tables
Robust Head-Pose Estimation Based on Partially-Latent Mixture of Linear Regressions
Mar 06, 2017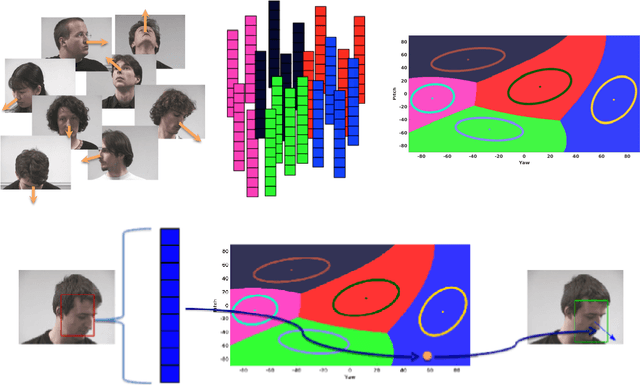
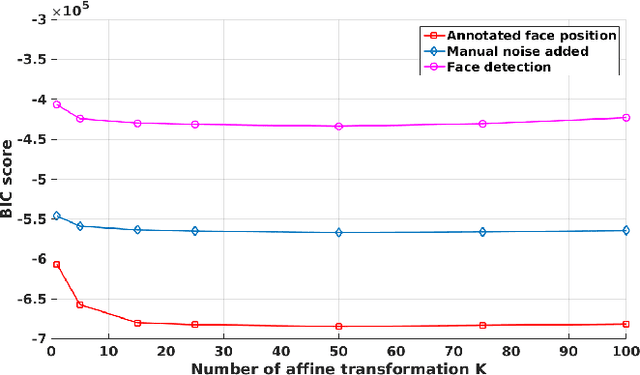
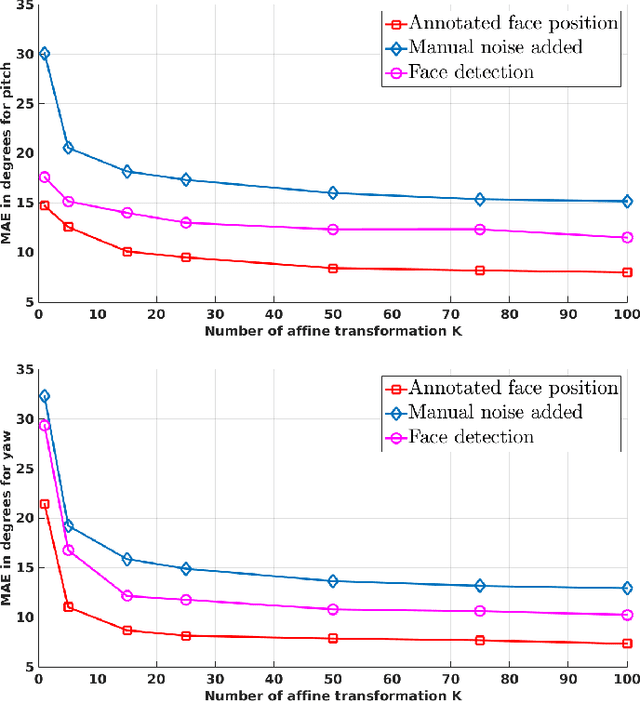

Head-pose estimation has many applications, such as social event analysis, human-robot and human-computer interaction, driving assistance, and so forth. Head-pose estimation is challenging because it must cope with changing illumination conditions, variabilities in face orientation and in appearance, partial occlusions of facial landmarks, as well as bounding-box-to-face alignment errors. We propose tu use a mixture of linear regressions with partially-latent output. This regression method learns to map high-dimensional feature vectors (extracted from bounding boxes of faces) onto the joint space of head-pose angles and bounding-box shifts, such that they are robustly predicted in the presence of unobservable phenomena. We describe in detail the mapping method that combines the merits of unsupervised manifold learning techniques and of mixtures of regressions. We validate our method with three publicly available datasets and we thoroughly benchmark four variants of the proposed algorithm with several state-of-the-art head-pose estimation methods.
* 12 pages, 5 figures, 3 tables
Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion
Nov 03, 2016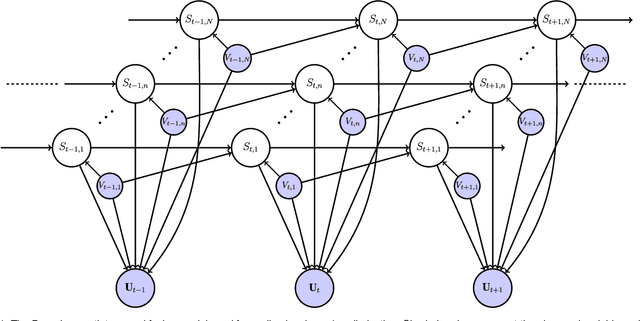
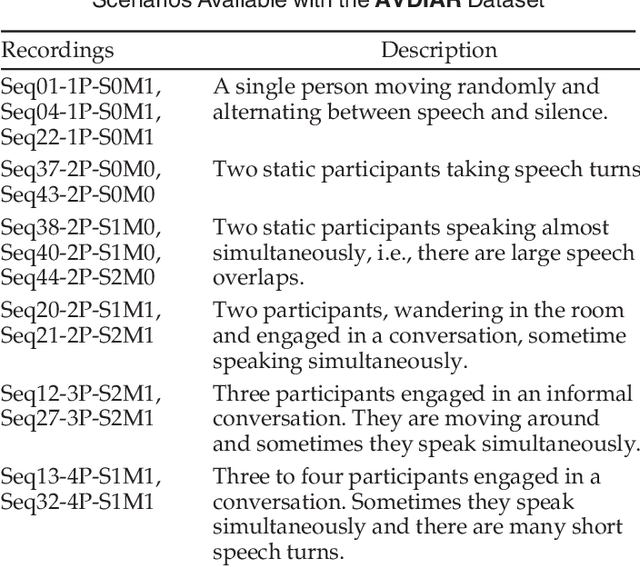
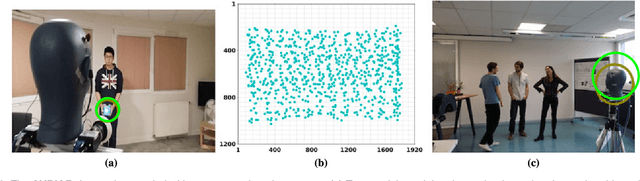
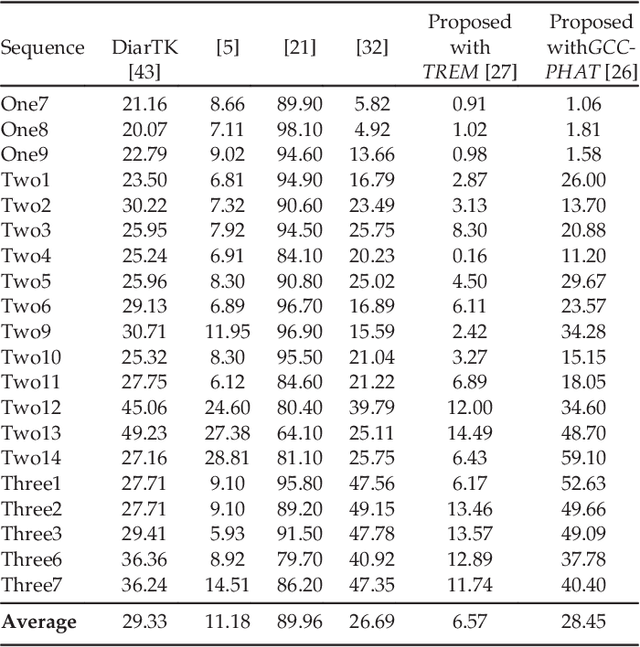
Speaker diarization consists of assigning speech signals to people engaged in a dialogue. An audio-visual spatiotemporal diarization model is proposed. The model is well suited for challenging scenarios that consist of several participants engaged in multi-party interaction while they move around and turn their heads towards the other participants rather than facing the cameras and the microphones. Multiple-person visual tracking is combined with multiple speech-source localization in order to tackle the speech-to-person association problem. The latter is solved within a novel audio-visual fusion method on the following grounds: binaural spectral features are first extracted from a microphone pair, then a supervised audio-visual alignment technique maps these features onto an image, and finally a semi-supervised clustering method assigns binaural spectral features to visible persons. The main advantage of this method over previous work is that it processes in a principled way speech signals uttered simultaneously by multiple persons. The diarization itself is cast into a latent-variable temporal graphical model that infers speaker identities and speech turns, based on the output of an audio-visual association process, executed at each time slice, and on the dynamics of the diarization variable itself. The proposed formulation yields an efficient exact inference procedure. A novel dataset, that contains audio-visual training data as well as a number of scenarios involving several participants engaged in formal and informal dialogue, is introduced. The proposed method is thoroughly tested and benchmarked with respect to several state-of-the art diarization algorithms.
* 14 pages, 6 figures, 5 tables