 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
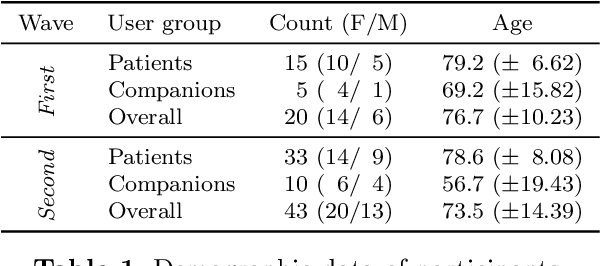
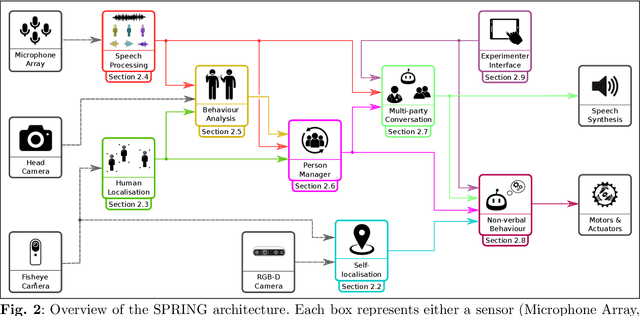
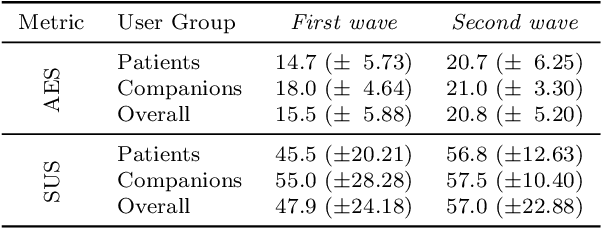
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Hand-Eye Calibration
Nov 22, 2023Whenever a sensor is mounted on a robot hand it is important to know the relationship between the sensor and the hand. The problem of determining this relationship is referred to as hand-eye calibration, which is important in at least two types of tasks: (i) map sensor centered measurements into the robot workspace and (ii) allow the robot to precisely move the sensor. In the past some solutions were proposed in the particular case of a camera. With almost no exception, all existing solutions attempt to solve the homogeneous matrix equation AX=XB. First we show that there are two possible formulations of the hand-eye calibration problem. One formulation is the classical one that we just mentioned. A second formulation takes the form of the following homogeneous matrix equation: MY=M'YB. The advantage of the latter is that the extrinsic and intrinsic camera parameters need not be made explicit. Indeed, this formulation directly uses the 3 by 4 perspective matrices (M and M') associated with two positions of the camera. Moreover, this formulation together with the classical one cover a wider range of camera-based sensors to be calibrated with respect to the robot hand. Second, we develop a common mathematical framework to solve for the hand-eye calibration problem using either of the two formulations. We present two methods, (i) a rotation then translation and (ii) a non-linear solver for rotation and translation. Third, we perform a stability analysis both for our two methods and for the classical linear method of Tsai and Lenz (1989). In the light of this comparison, the non-linear optimization method, that solves for rotation and translation simultaneously, seems to be the most robust one with respect to noise and to measurement errors.
Robot Hand-Eye Calibration using Structure-from-Motion
Nov 21, 2023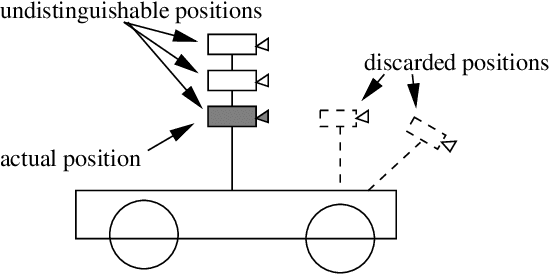

In this paper we propose a new flexible method for hand-eye calibration. The vast majority of existing hand-eye calibration techniques requires a calibration rig which is used in conjunction with camera pose estimation methods. Instead, we combine structure-from-motion with known robot motions and we show that the solution can be obtained in linear form. The latter solves for both the hand-eye parameters and for the unknown scale factor inherent with structure-from-motion methods. The algebraic analysis that is made possible with such a linear formulation allows to investigate not only the well known case of general screw motions but also such singular motions as pure translations, pure rotations, and planar motions. In essence, the robot-mounted camera looks to an unknown rigid layout, tracks points over an image sequence and estimates the camera-to-robot relationship. Such a self calibration process is relevant for unmanned vehicles, robots working in remote places, and so forth. We conduct a large number of experiments which validate the quality of the method by comparing it with existing ones.
Polyhedral Object Recognition by Indexing
Nov 21, 2023In computer vision, the indexing problem is the problem of recognizing a few objects in a large database of objects while avoiding the help of the classical image-feature-to-object-feature matching paradigm. In this paper we address the problem of recognizing 3-D polyhedral objects from 2-D images by indexing. Both the objects to be recognized and the images are represented by weighted graphs. The indexing problem is therefore the problem of determining whether a graph extracted from the image is present or absent in a database of model graphs. We introduce a novel method for performing this graph indexing process which is based both on polynomial characterization of binary and weighted graphs and on hashing. We describe in detail this polynomial characterization and then we show how it can be used in the context of polyhedral object recognition. Next we describe a practical recognition-by-indexing system that includes the organization of the database, the representation of polyhedral objects in terms of 2-D characteristic views, the representation of this views in terms of weighted graphs, and the associated image processing. Finally, some experimental results allow the evaluation of the system performance.
Visually Guided Object Grasping
Nov 21, 2023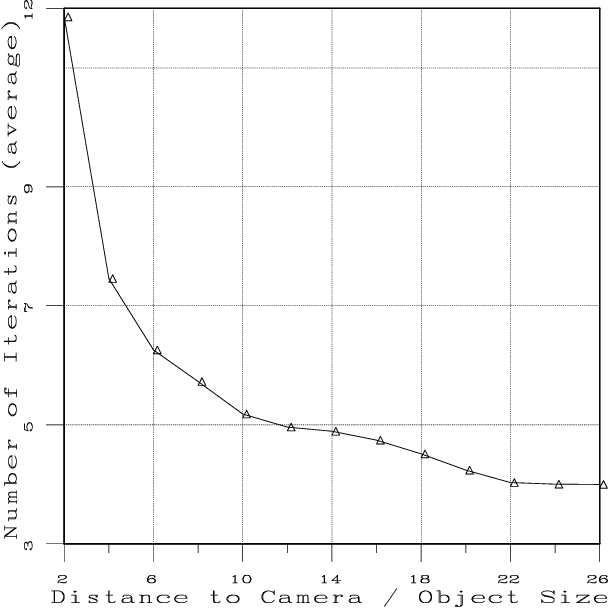

In this paper we present a visual servoing approach to the problem of object grasping and more generally, to the problem of aligning an end-effector with an object. First we extend the method proposed by Espiau et al. [1] to the case of a camera which is not mounted onto the robot being controlled and we stress the importance of the real-time estimation of the image Jacobian. Second, we show how to represent a grasp or more generally, an alignment between two solids in 3-D projective space using an uncalibrated stereo rig. Such a 3-D projective representation is view-invariant in the sense that it can be easily mapped into an image set-point without any knowledge about the camera parameters. Third, we perform an analysis of the performances of the visual servoing algorithm and of the grasping precision that can be expected from this type of approach.
Simultaneous Robot-World and Hand-Eye Calibration
Nov 20, 2023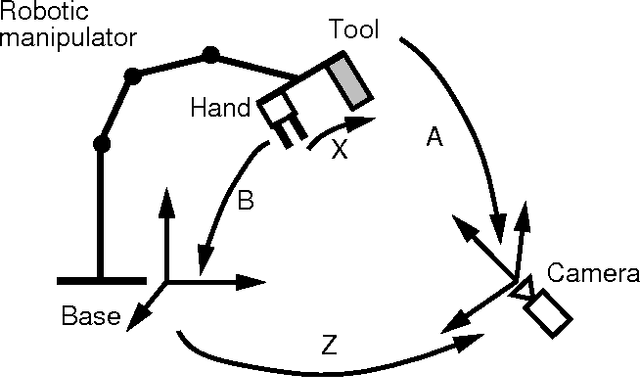
Recently, Zhuang, Roth, \& Sudhakar [1] proposed a method that allows simultaneous computation of the rigid transformations from world frame to robot base frame and from hand frame to camera frame. Their method attempts to solve a homogeneous matrix equation of the form AX=ZB. They use quaternions to derive explicit linear solutions for X and Z. In this short paper, we present two new solutions that attempt to solve the homogeneous matrix equation mentioned above: (i) a closed-form method which uses quaternion algebra and a positive quadratic error function associated with this representation and (ii) a method based on non-linear constrained minimization and which simultaneously solves for rotations and translations. These results may be useful to other problems that can be formulated in the same mathematical form. We perform a sensitivity analysis for both our two methods and the linear method developed by Zhuang et al. This analysis allows the comparison of the three methods. In the light of this comparison the non-linear optimization method, which solves for rotations and translations simultaneously, seems to be the most stable one with respect to noise and to measurement errors.
Expression-preserving face frontalization improves visually assisted speech processing
Apr 07, 2022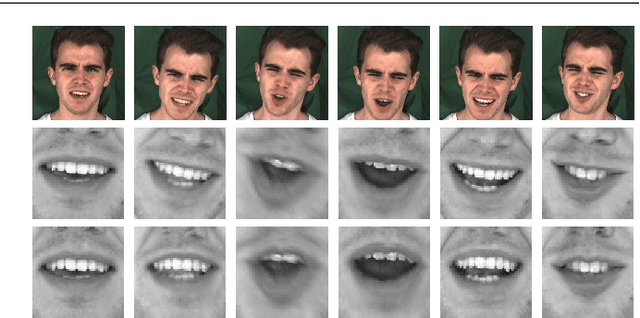

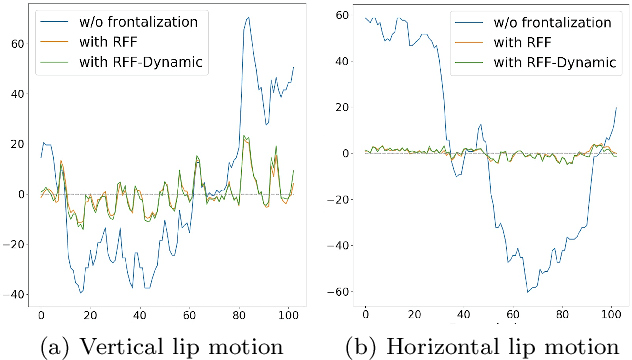
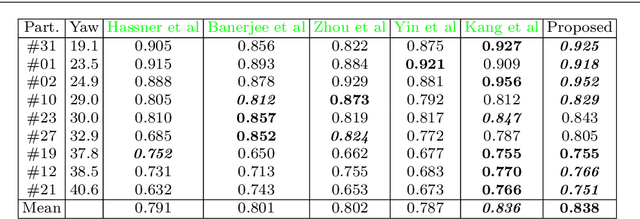
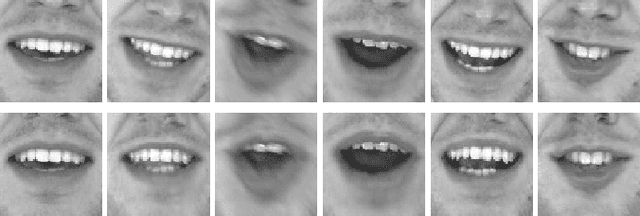
Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a frontalization methodology that preserves non-rigid facial deformations in order to boost the performance of visually assisted speech communication. The method alternates between the estimation of (i)~the rigid transformation (scale, rotation, and translation) and (ii)~the non-rigid deformation between an arbitrarily-viewed face and a face model. The method has two important merits: it can deal with non-Gaussian errors in the data and it incorporates a dynamical face deformation model. For that purpose, we use the generalized Student t-distribution in combination with a linear dynamic system in order to account for both rigid head motions and time-varying facial deformations caused by speech production. We propose to use the zero-mean normalized cross-correlation (ZNCC) score to evaluate the ability of the method to preserve facial expressions. The method is thoroughly evaluated and compared with several state of the art methods, either based on traditional geometric models or on deep learning. Moreover, we show that the method, when incorporated into deep learning pipelines, namely lip reading and speech enhancement, improves word recognition and speech intelligibilty scores by a considerable margin. Supplemental material is accessible at https://team.inria.fr/robotlearn/research/facefrontalization-benchmark/
The impact of removing head movements on audio-visual speech enhancement
Feb 02, 2022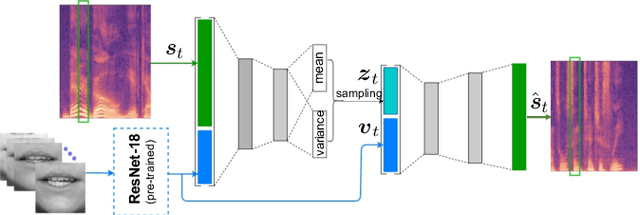
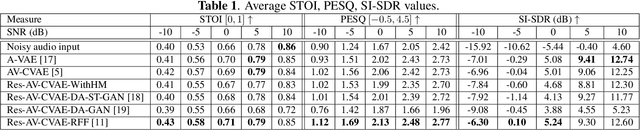
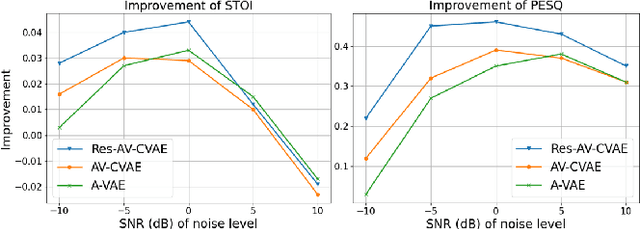
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
High-Resolution Depth Maps Based on TOF-Stereo Fusion
Jul 30, 2021

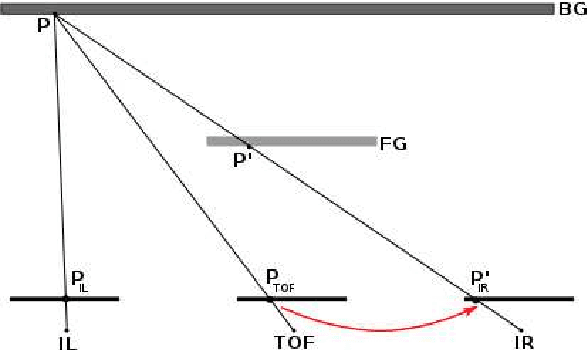

The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial "seeds" are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.
3D Shape Registration Using Spectral Graph Embedding and Probabilistic Matching
Jun 21, 2021

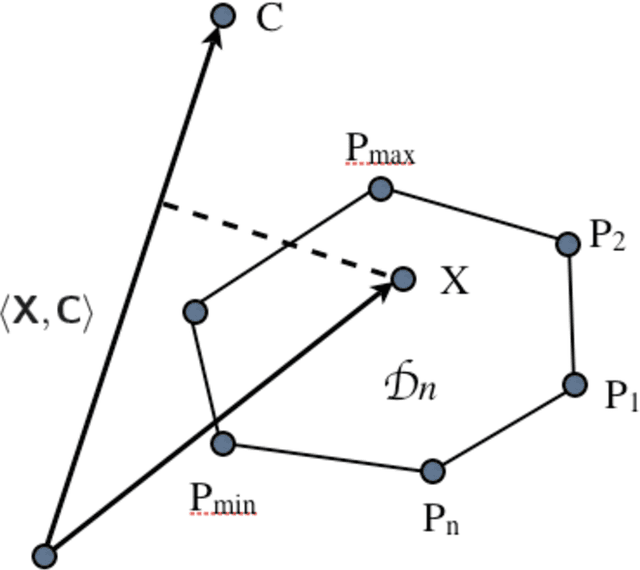
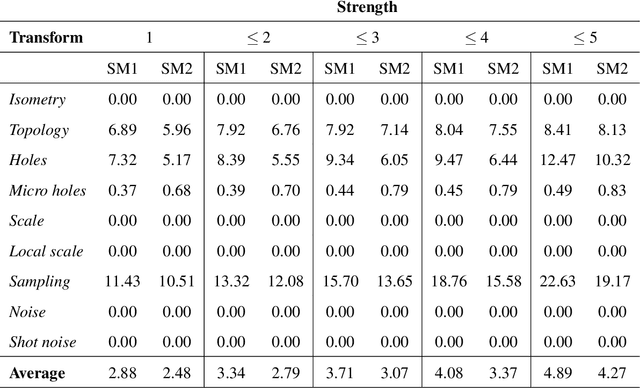
We address the problem of 3D shape registration and we propose a novel technique based on spectral graph theory and probabilistic matching. The task of 3D shape analysis involves tracking, recognition, registration, etc. Analyzing 3D data in a single framework is still a challenging task considering the large variability of the data gathered with different acquisition devices. 3D shape registration is one such challenging shape analysis task. The main contribution of this chapter is to extend the spectral graph matching methods to very large graphs by combining spectral graph matching with Laplacian embedding. Since the embedded representation of a graph is obtained by dimensionality reduction we claim that the existing spectral-based methods are not easily applicable. We discuss solutions for the exact and inexact graph isomorphism problems and recall the main spectral properties of the combinatorial graph Laplacian; We provide a novel analysis of the commute-time embedding that allows us to interpret the latter in terms of the PCA of a graph, and to select the appropriate dimension of the associated embedded metric space; We derive a unit hyper-sphere normalization for the commute-time embedding that allows us to register two shapes with different samplings; We propose a novel method to find the eigenvalue-eigenvector ordering and the eigenvector signs using the eigensignature (histogram) which is invariant to the isometric shape deformations and fits well in the spectral graph matching framework, and we present a probabilistic shape matching formulation using an expectation maximization point registration algorithm which alternates between aligning the eigenbases and finding a vertex-to-vertex assignment.