 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alpha Blending Hypothesis: Compositing Shortcut in Deepfake Detection
May 11, 2026Recent deepfake detection methods demonstrate improved cross-dataset generalization, yet the underlying mechanisms remain underexplored. We introduce the Alpha Blending Hypothesis, positing that state-of-the-art frame-based detectors primarily function as alpha blending searchers; rather than learning semantic anomalies or specific generative neural fingerprints, they localize low-level compositing artifacts introduced during the integration of manipulated faces into target frames. We experimentally validate the hypothesis, demonstrating that deepfake detectors exhibit high sensitivity to the so-called self-blended images (SBI) and non-generative manipulations. We propose the method BlenD that leverages a large-scale, diverse dataset of real-only facial images augmented with SBI. This approach achieves the best average cross-dataset generalization on 15 compositional deepfake datasets released between 2019 and 2025 without utilizing explicitly generated deepfakes during training. Furthermore, we show that predictions from explicit blending searchers and models resilient to blending shortcuts are highly complementary, yielding a state-of-the-art AUROC of 94.0% in an ensemble configuration. The code with experiments and the trained model will be publicly released.
BLANKET: Anonymizing Faces in Infant Video Recordings
Dec 17, 2025



Ensuring the ethical use of video data involving human subjects, particularly infants, requires robust anonymization methods. We propose BLANKET (Baby-face Landmark-preserving ANonymization with Keypoint dEtection consisTency), a novel approach designed to anonymize infant faces in video recordings while preserving essential facial attributes. Our method comprises two stages. First, a new random face, compatible with the original identity, is generated via inpainting using a diffusion model. Second, the new identity is seamlessly incorporated into each video frame through temporally consistent face swapping with authentic expression transfer. The method is evaluated on a dataset of short video recordings of babies and is compared to the popular anonymization method, DeepPrivacy2. Key metrics assessed include the level of de-identification, preservation of facial attributes, impact on human pose estimation (as an example of a downstream task), and presence of artifacts. Both methods alter the identity, and our method outperforms DeepPrivacy2 in all other respects. The code is available as an easy-to-use anonymization demo at https://github.com/ctu-vras/blanket-infant-face-anonym.
* Project website: https://github.com/ctu-vras/blanket-infant-face-anonym
Deepfake Detection that Generalizes Across Benchmarks
Aug 08, 2025The generalization of deepfake detectors to unseen manipulation techniques remains a challenge for practical deployment. Although many approaches adapt foundation models by introducing significant architectural complexity, this work demonstrates that robust generalization is achievable through a parameter-efficient adaptation of a pre-trained CLIP vision encoder. The proposed method, LNCLIP-DF, fine-tunes only the Layer Normalization parameters (0.03% of the total) and enhances generalization by enforcing a hyperspherical feature manifold using L2 normalization and latent space augmentations. We conducted an extensive evaluation on 13 benchmark datasets spanning from 2019 to 2025. The proposed method achieves state-of-the-art performance, outperforming more complex, recent approaches in average cross-dataset AUROC. Our analysis yields two primary findings for the field: 1) training on paired real-fake data from the same source video is essential for mitigating shortcut learning and improving generalization, and 2) detection difficulty on academic datasets has not strictly increased over time, with models trained on older, diverse datasets showing strong generalization capabilities. This work delivers a computationally efficient and reproducible method, proving that state-of-the-art generalization is attainable by making targeted, minimal changes to a pre-trained CLIP model. The code will be made publicly available upon acceptance.
Predicting Road Surface Anomalies by Visual Tracking of a Preceding Vehicle
May 07, 2025



A novel approach to detect road surface anomalies by visual tracking of a preceding vehicle is proposed. The method is versatile, predicting any kind of road anomalies, such as potholes, bumps, debris, etc., unlike direct observation methods that rely on training visual detectors of those cases. The method operates in low visibility conditions or in dense traffic where the anomaly is occluded by a preceding vehicle. Anomalies are detected predictively, i.e., before a vehicle encounters them, which allows to pre-configure low-level vehicle systems (such as chassis) or to plan an avoidance maneuver in case of autonomous driving. A challenge is that the signal coming from camera-based tracking of a preceding vehicle may be weak and disturbed by camera ego motion due to vibrations affecting the ego vehicle. Therefore, we propose an efficient method to compensate camera pitch rotation by an iterative robust estimator. Our experiments on both controlled setup and normal traffic conditions show that road anomalies can be detected reliably at a distance even in challenging cases where the ego vehicle traverses imperfect road surfaces. The method is effective and performs in real time on standard consumer hardware.
Pose and Facial Expression Transfer by using StyleGAN
Apr 17, 2025



We propose a method to transfer pose and expression between face images. Given a source and target face portrait, the model produces an output image in which the pose and expression of the source face image are transferred onto the target identity. The architecture consists of two encoders and a mapping network that projects the two inputs into the latent space of StyleGAN2, which finally generates the output. The training is self-supervised from video sequences of many individuals. Manual labeling is not required. Our model enables the synthesis of random identities with controllable pose and expression. Close-to-real-time performance is achieved.
* Accepted at CVWW 2024. Presented in Terme Olimia, Slovenia
Unlocking the Hidden Potential of CLIP in Generalizable Deepfake Detection
Mar 26, 2025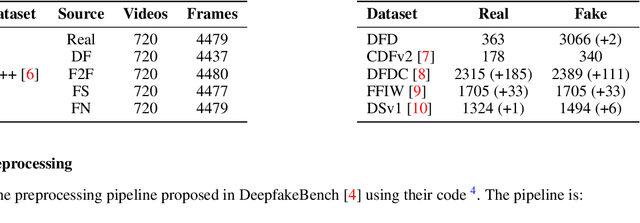
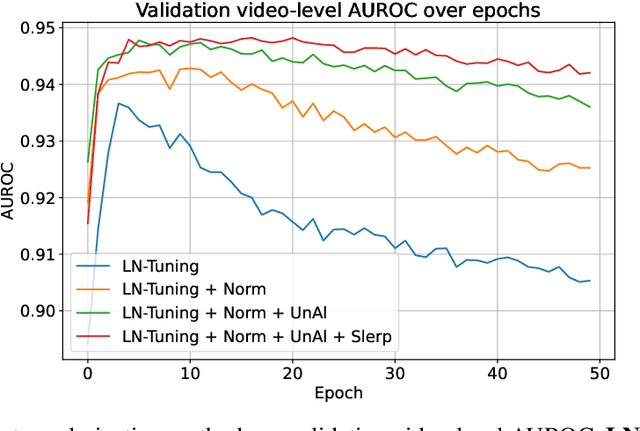
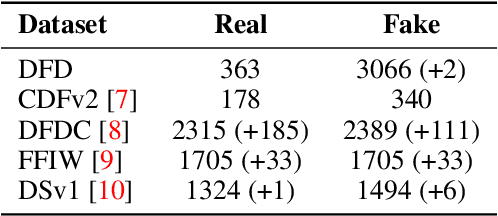
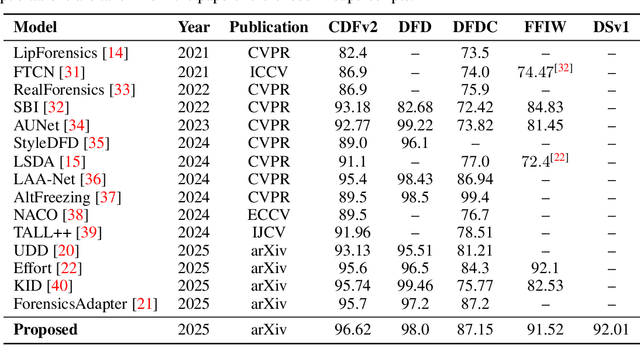
This paper tackles the challenge of detecting partially manipulated facial deepfakes, which involve subtle alterations to specific facial features while retaining the overall context, posing a greater detection difficulty than fully synthetic faces. We leverage the Contrastive Language-Image Pre-training (CLIP) model, specifically its ViT-L/14 visual encoder, to develop a generalizable detection method that performs robustly across diverse datasets and unknown forgery techniques with minimal modifications to the original model. The proposed approach utilizes parameter-efficient fine-tuning (PEFT) techniques, such as LN-tuning, to adjust a small subset of the model's parameters, preserving CLIP's pre-trained knowledge and reducing overfitting. A tailored preprocessing pipeline optimizes the method for facial images, while regularization strategies, including L2 normalization and metric learning on a hyperspherical manifold, enhance generalization. Trained on the FaceForensics++ dataset and evaluated in a cross-dataset fashion on Celeb-DF-v2, DFDC, FFIW, and others, the proposed method achieves competitive detection accuracy comparable to or outperforming much more complex state-of-the-art techniques. This work highlights the efficacy of CLIP's visual encoder in facial deepfake detection and establishes a simple, powerful baseline for future research, advancing the field of generalizable deepfake detection. The code is available at: https://github.com/yermandy/deepfake-detection
Detection of Synthetic Face Images: Accuracy, Robustness, Generalization
Jun 25, 2024An experimental study on detecting synthetic face images is presented. We collected a dataset, called FF5, of five fake face image generators, including recent diffusion models. We find that a simple model trained on a specific image generator can achieve near-perfect accuracy in separating synthetic and real images. The model handles common image distortions (reduced resolution, compression) by using data augmentation. Moreover, partial manipulations, where synthetic images are blended into real ones by inpainting, are identified and the area of the manipulation is localized by a simple model of YOLO architecture. However, the model turned out to be vulnerable to adversarial attacks and does not generalize to unseen generators. Failure to generalize to detect images produced by a newer generator also occurs for recent state-of-the-art methods, which we tested on Realistic Vision, a fine-tuned version of StabilityAI's Stable Diffusion image generator.
High-Resolution Depth Maps Based on TOF-Stereo Fusion
Jul 30, 2021

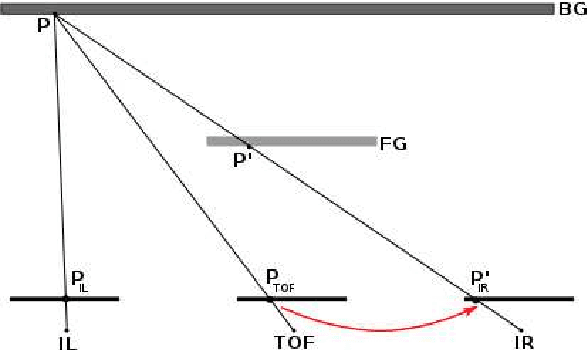

The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial "seeds" are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.
Continuous Action Recognition Based on Sequence Alignment
Jun 02, 2014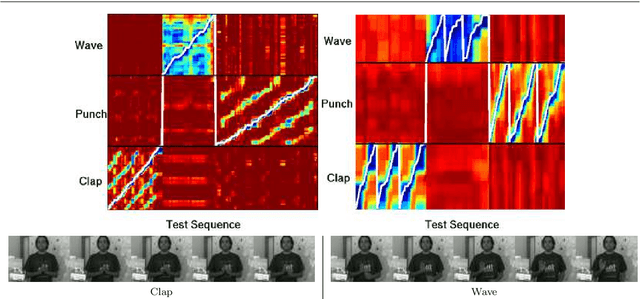
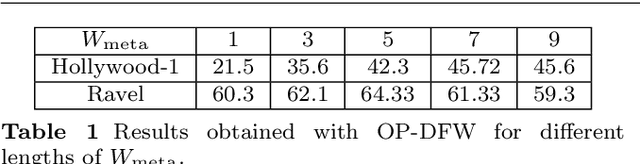

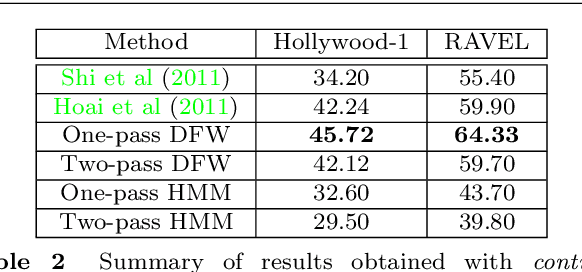
Continuous action recognition is more challenging than isolated recognition because classification and segmentation must be simultaneously carried out. We build on the well known dynamic time warping (DTW) framework and devise a novel visual alignment technique, namely dynamic frame warping (DFW), which performs isolated recognition based on per-frame representation of videos, and on aligning a test sequence with a model sequence. Moreover, we propose two extensions which enable to perform recognition concomitant with segmentation, namely one-pass DFW and two-pass DFW. These two methods have their roots in the domain of continuous recognition of speech and, to the best of our knowledge, their extension to continuous visual action recognition has been overlooked. We test and illustrate the proposed techniques with a recently released dataset (RAVEL) and with two public-domain datasets widely used in action recognition (Hollywood-1 and Hollywood-2). We also compare the performances of the proposed isolated and continuous recognition algorithms with several recently published methods.