 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMePo: Meta Post-Refinement for Rehearsal-Free General Continual Learnin
Feb 08, 2026To cope with uncertain changes of the external world, intelligent systems must continually learn from complex, evolving environments and respond in real time. This ability, collectively known as general continual learning (GCL), encapsulates practical challenges such as online datastreams and blurry task boundaries. Although leveraging pretrained models (PTMs) has greatly advanced conventional continual learning (CL), these methods remain limited in reconciling the diverse and temporally mixed information along a single pass, resulting in sub-optimal GCL performance. Inspired by meta-plasticity and reconstructive memory in neuroscience, we introduce here an innovative approach named Meta Post-Refinement (MePo) for PTMs-based GCL. This approach constructs pseudo task sequences from pretraining data and develops a bi-level meta-learning paradigm to refine the pretrained backbone, which serves as a prolonged pretraining phase but greatly facilitates rapid adaptation of representation learning to downstream GCL tasks. MePo further initializes a meta covariance matrix as the reference geometry of pretrained representation space, enabling GCL to exploit second-order statistics for robust output alignment. MePo serves as a plug-in strategy that achieves significant performance gains across a variety of GCL benchmarks and pretrained checkpoints in a rehearsal-free manner (e.g., 15.10\%, 13.36\%, and 12.56\% on CIFAR-100, ImageNet-R, and CUB-200 under Sup-21/1K). Our source code is available at \href{https://github.com/SunGL001/MePo}{MePo}
Dynamically Anchored Prompting for Task-Imbalanced Continual Learning
Apr 23, 2024



Existing continual learning literature relies heavily on a strong assumption that tasks arrive with a balanced data stream, which is often unrealistic in real-world applications. In this work, we explore task-imbalanced continual learning (TICL) scenarios where the distribution of task data is non-uniform across the whole learning process. We find that imbalanced tasks significantly challenge the capability of models to control the trade-off between stability and plasticity from the perspective of recent prompt-based continual learning methods. On top of the above finding, we propose Dynamically Anchored Prompting (DAP), a prompt-based method that only maintains a single general prompt to adapt to the shifts within a task stream dynamically. This general prompt is regularized in the prompt space with two specifically designed prompt anchors, called boosting anchor and stabilizing anchor, to balance stability and plasticity in TICL. Remarkably, DAP achieves this balance by only storing a prompt across the data stream, therefore offering a substantial advantage in rehearsal-free CL. Extensive experiments demonstrate that the proposed DAP results in 4.5% to 15% absolute improvements over state-of-the-art methods on benchmarks under task-imbalanced settings. Our code is available at https://github.com/chenxing6666/DAP
A soft nearest-neighbor framework for continual semi-supervised learning
Dec 09, 2022



Despite significant advances, the performance of state-of-the-art continual learning approaches hinges on the unrealistic scenario of fully labeled data. In this paper, we tackle this challenge and propose an approach for continual semi-supervised learning -- a setting where not all the data samples are labeled. An underlying issue in this scenario is the model forgetting representations of unlabeled data and overfitting the labeled ones. We leverage the power of nearest-neighbor classifiers to non-linearly partition the feature space and learn a strong representation for the current task, as well as distill relevant information from previous tasks. We perform a thorough experimental evaluation and show that our method outperforms all the existing approaches by large margins, setting a strong state of the art on the continual semi-supervised learning paradigm. For example, on CIFAR100 we surpass several others even when using at least 30 times less supervision (0.8% vs. 25% of annotations).
Expression-preserving face frontalization improves visually assisted speech processing
Apr 07, 2022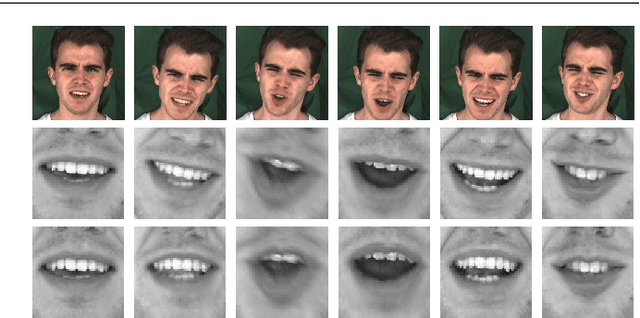

Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a frontalization methodology that preserves non-rigid facial deformations in order to boost the performance of visually assisted speech communication. The method alternates between the estimation of (i)~the rigid transformation (scale, rotation, and translation) and (ii)~the non-rigid deformation between an arbitrarily-viewed face and a face model. The method has two important merits: it can deal with non-Gaussian errors in the data and it incorporates a dynamical face deformation model. For that purpose, we use the generalized Student t-distribution in combination with a linear dynamic system in order to account for both rigid head motions and time-varying facial deformations caused by speech production. We propose to use the zero-mean normalized cross-correlation (ZNCC) score to evaluate the ability of the method to preserve facial expressions. The method is thoroughly evaluated and compared with several state of the art methods, either based on traditional geometric models or on deep learning. Moreover, we show that the method, when incorporated into deep learning pipelines, namely lip reading and speech enhancement, improves word recognition and speech intelligibilty scores by a considerable margin. Supplemental material is accessible at https://team.inria.fr/robotlearn/research/facefrontalization-benchmark/
The impact of removing head movements on audio-visual speech enhancement
Feb 02, 2022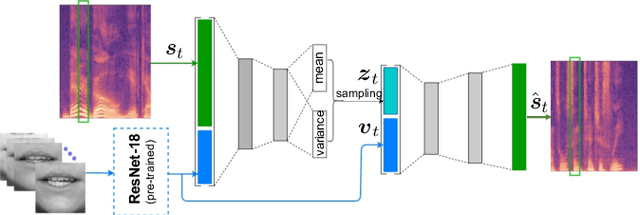
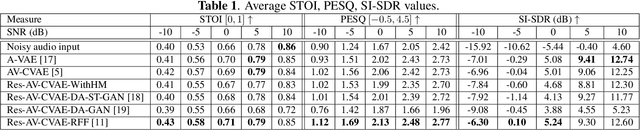
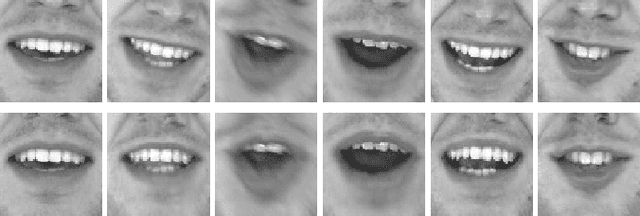
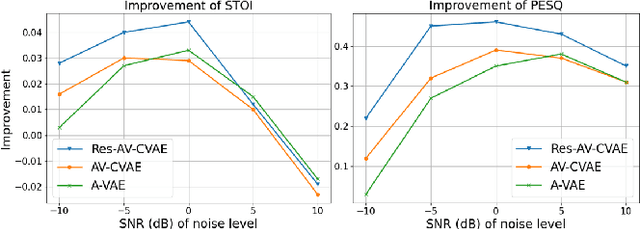
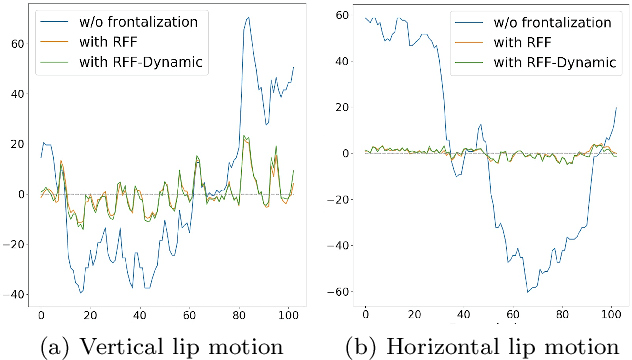
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
Face Frontalization Based on Robustly Fitting a Deformable Shape Model to 3D Landmarks
Oct 26, 2020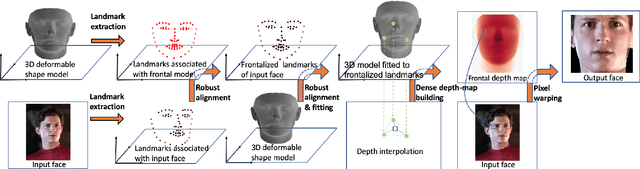



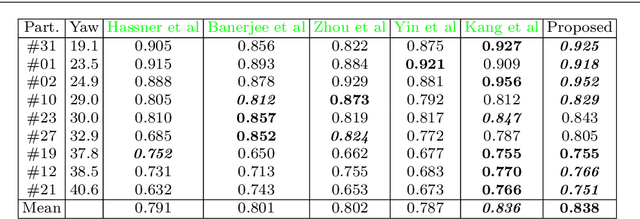
Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a robust face alignment method that enables pixel-to-pixel warping. The method simultaneously estimates the \textit{rigid transformation} (scale, rotation, and translation) and the \textit{non-rigid deformation} between two 3D point sets: a set of 3D landmarks extracted from an arbitrary-viewed face, and a set of 3D landmarks parameterized by a frontally-viewed deformable face model. An important merit of the proposed method is its ability to deal both with noise (small perturbations) and with outliers (large errors). We propose to model inliers and outliers with the generalized Student's t-probability distribution function -- a heavy-tailed distribution that is immune to non-Gaussian errors in the data. We describe in detail the associated expectation-maximization (EM) algorithm that alternates between the estimation of (i)~the rigid parameters, (ii)~the deformation parameters, and (iii)~ the t-distribution parameters. We also propose to use the \textit{zero-mean normalized cross-correlation}, between a frontalized face and the corresponding ground-truth frontally-viewed face, to evaluate the performance of frontalization. To this end, we use a dataset that contains pairs of profile-viewed and frontally-viewed faces. This evaluation, based on direct image-to-image comparison, stands in contrast with indirect evaluation, based on analyzing the effect of frontalization on face recognition.