 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of removing head movements on audio-visual speech enhancement
Paper and Code
Feb 02, 2022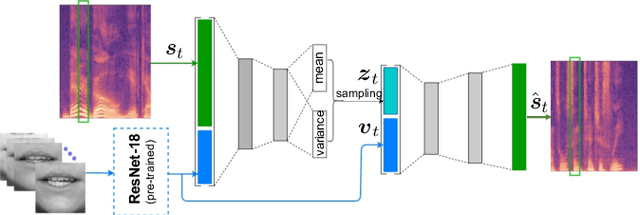
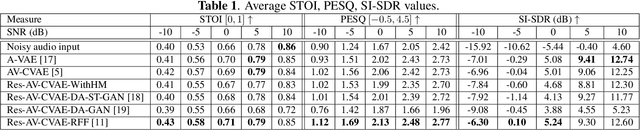
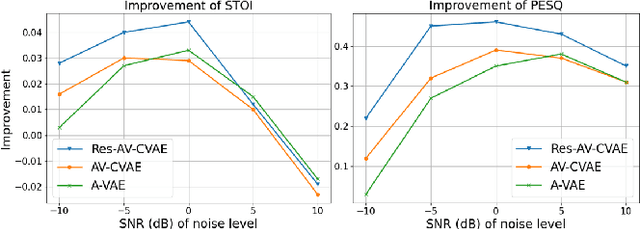
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.