 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
Apr 10, 2025



Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)--those trained from the ground up on all modalities--and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
On Large Multimodal Models as Open-World Image Classifiers
Mar 27, 2025



Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
Feb 19, 2025Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image's inherent complexity. We introduce FlexTok, a tokenizer that projects 2D images into variable-length, ordered 1D token sequences. For example, a 256x256 image can be resampled into anywhere from 1 to 256 discrete tokens, hierarchically and semantically compressing its information. By training a rectified flow model as the decoder and using nested dropout, FlexTok produces plausible reconstructions regardless of the chosen token sequence length. We evaluate our approach in an autoregressive generation setting using a simple GPT-style Transformer. On ImageNet, this approach achieves an FID<2 across 8 to 128 tokens, outperforming TiTok and matching state-of-the-art methods with far fewer tokens. We further extend the model to support to text-conditioned image generation and examine how FlexTok relates to traditional 2D tokenization. A key finding is that FlexTok enables next-token prediction to describe images in a coarse-to-fine "visual vocabulary", and that the number of tokens to generate depends on the complexity of the generation task.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Retrieval-enriched zero-shot image classification in low-resource domains
Nov 01, 2024



Low-resource domains, characterized by scarce data and annotations, present significant challenges for language and visual understanding tasks, with the latter much under-explored in the literature. Recent advancements in Vision-Language Models (VLM) have shown promising results in high-resource domains but fall short in low-resource concepts that are under-represented (e.g. only a handful of images per category) in the pre-training set. We tackle the challenging task of zero-shot low-resource image classification from a novel perspective. By leveraging a retrieval-based strategy, we achieve this in a training-free fashion. Specifically, our method, named CoRE (Combination of Retrieval Enrichment), enriches the representation of both query images and class prototypes by retrieving relevant textual information from large web-crawled databases. This retrieval-based enrichment significantly boosts classification performance by incorporating the broader contextual information relevant to the specific class. We validate our method on a newly established benchmark covering diverse low-resource domains, including medical imaging, rare plants, and circuits. Our experiments demonstrate that CORE outperforms existing state-of-the-art methods that rely on synthetic data generation and model fine-tuning.
Visual Scratchpads: Enabling Global Reasoning in Vision
Oct 10, 2024

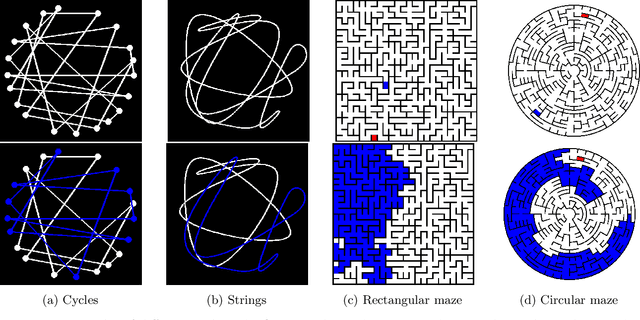

Modern vision models have achieved remarkable success in benchmarks where local features provide critical information about the target. There is now a growing interest in solving tasks that require more global reasoning, where local features offer no significant information. These tasks are reminiscent of the connectivity tasks discussed by Minsky and Papert in 1969, which exposed the limitations of the perceptron model and contributed to the first AI winter. In this paper, we revisit such tasks by introducing four global visual benchmarks involving path findings and mazes. We show that: (1) although today's large vision models largely surpass the expressivity limitations of the early models, they still struggle with the learning efficiency; we put forward the "globality degree" notion to understand this limitation; (2) we then demonstrate that the picture changes and global reasoning becomes feasible with the introduction of "visual scratchpads"; similarly to the text scratchpads and chain-of-thoughts used in language models, visual scratchpads help break down global tasks into simpler ones; (3) we finally show that some scratchpads are better than others, in particular, "inductive scratchpads" that take steps relying on less information afford better out-of-distribution generalization and succeed for smaller model sizes.
Automatic benchmarking of large multimodal models via iterative experiment programming
Jun 18, 2024



Assessing the capabilities of large multimodal models (LMMs) often requires the creation of ad-hoc evaluations. Currently, building new benchmarks requires tremendous amounts of manual work for each specific analysis. This makes the evaluation process tedious and costly. In this paper, we present APEx, Automatic Programming of Experiments, the first framework for automatic benchmarking of LMMs. Given a research question expressed in natural language, APEx leverages a large language model (LLM) and a library of pre-specified tools to generate a set of experiments for the model at hand, and progressively compile a scientific report. The report drives the testing procedure: based on the current status of the investigation, APEx chooses which experiments to perform and whether the results are sufficient to draw conclusions. Finally, the LLM refines the report, presenting the results to the user in natural language. Thanks to its modularity, our framework is flexible and extensible as new tools become available. Empirically, APEx reproduces the findings of existing studies while allowing for arbitrary analyses and hypothesis testing.
Vocabulary-free Image Classification and Semantic Segmentation
Apr 16, 2024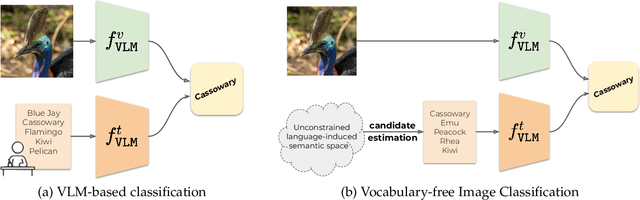
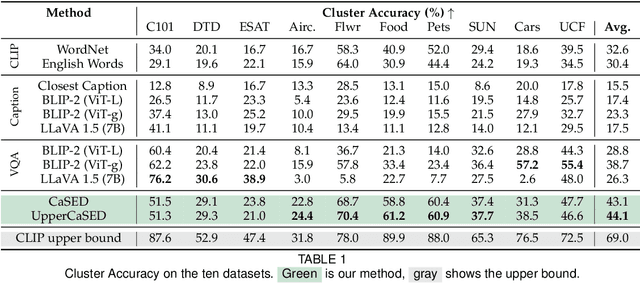
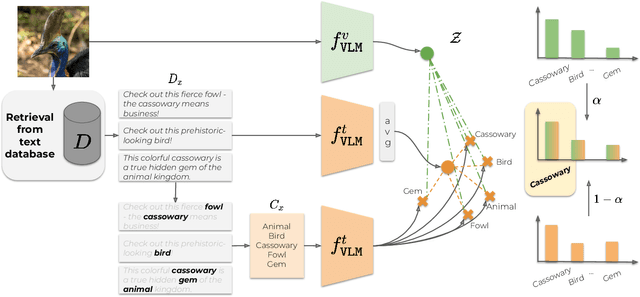
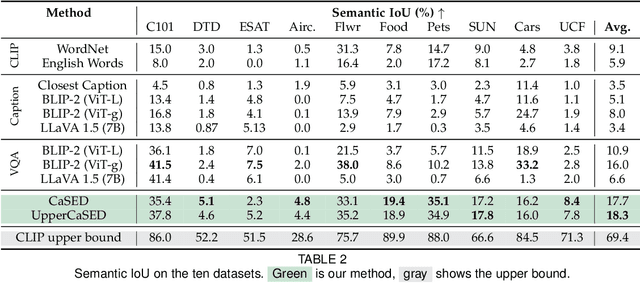
Large vision-language models revolutionized image classification and semantic segmentation paradigms. However, they typically assume a pre-defined set of categories, or vocabulary, at test time for composing textual prompts. This assumption is impractical in scenarios with unknown or evolving semantic context. Here, we address this issue and introduce the Vocabulary-free Image Classification (VIC) task, which aims to assign a class from an unconstrained language-induced semantic space to an input image without needing a known vocabulary. VIC is challenging due to the vastness of the semantic space, which contains millions of concepts, including fine-grained categories. To address VIC, we propose Category Search from External Databases (CaSED), a training-free method that leverages a pre-trained vision-language model and an external database. CaSED first extracts the set of candidate categories from the most semantically similar captions in the database and then assigns the image to the best-matching candidate category according to the same vision-language model. Furthermore, we demonstrate that CaSED can be applied locally to generate a coarse segmentation mask that classifies image regions, introducing the task of Vocabulary-free Semantic Segmentation. CaSED and its variants outperform other more complex vision-language models, on classification and semantic segmentation benchmarks, while using much fewer parameters.
Continual Contrastive Spoken Language Understanding
Oct 04, 2023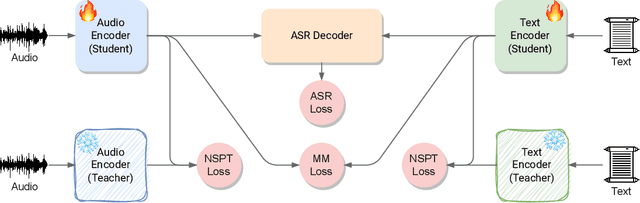
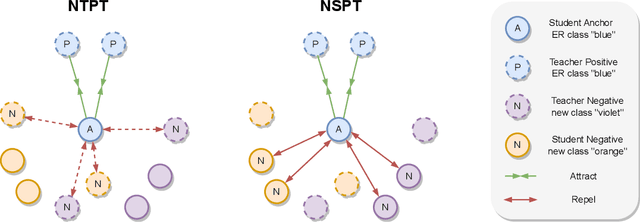


Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.
Semi-supervised learning made simple with self-supervised clustering
Jun 13, 2023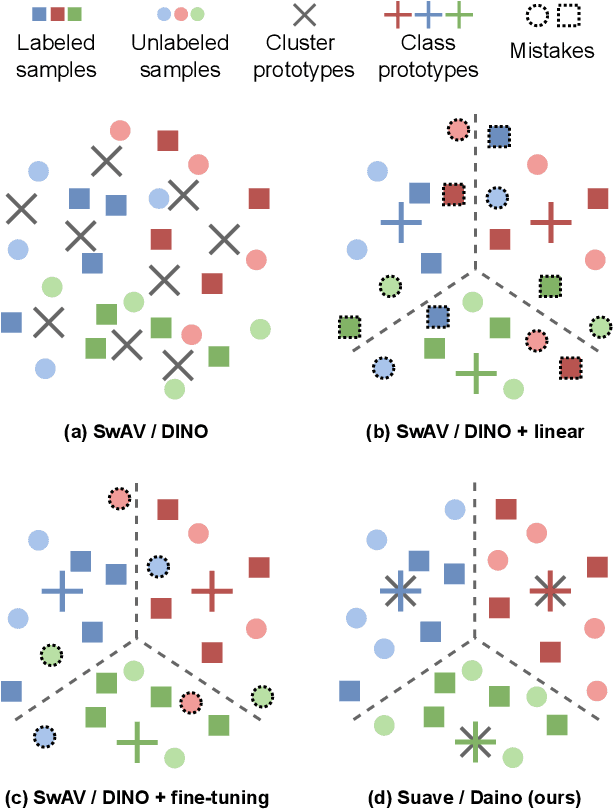
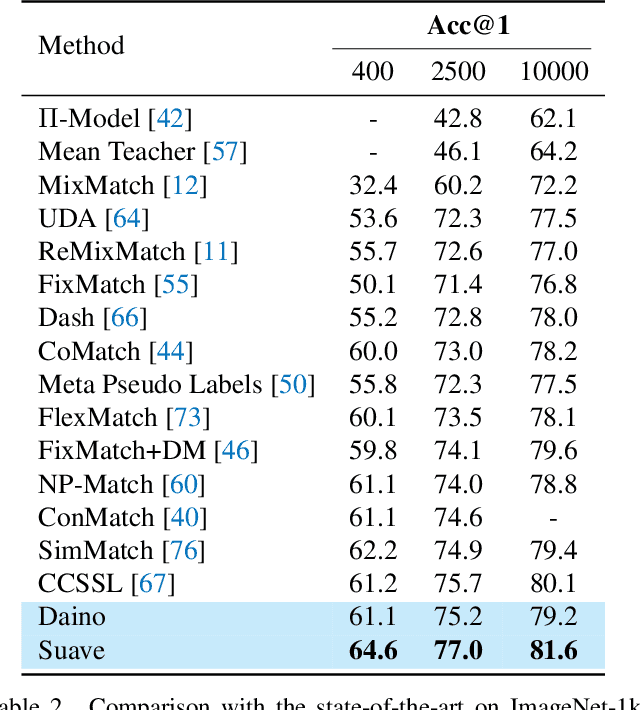
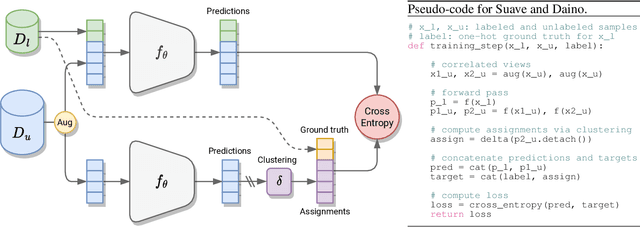
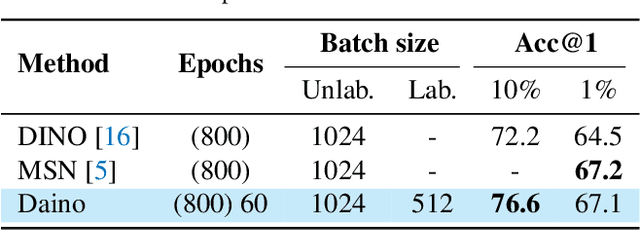
Self-supervised learning models have been shown to learn rich visual representations without requiring human annotations. However, in many real-world scenarios, labels are partially available, motivating a recent line of work on semi-supervised methods inspired by self-supervised principles. In this paper, we propose a conceptually simple yet empirically powerful approach to turn clustering-based self-supervised methods such as SwAV or DINO into semi-supervised learners. More precisely, we introduce a multi-task framework merging a supervised objective using ground-truth labels and a self-supervised objective relying on clustering assignments with a single cross-entropy loss. This approach may be interpreted as imposing the cluster centroids to be class prototypes. Despite its simplicity, we provide empirical evidence that our approach is highly effective and achieves state-of-the-art performance on CIFAR100 and ImageNet.
* CVPR 2023 - Code available at https://github.com/pietroastolfi/suave-daino