 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Scratchpads: Enabling Global Reasoning in Vision
Oct 10, 2024

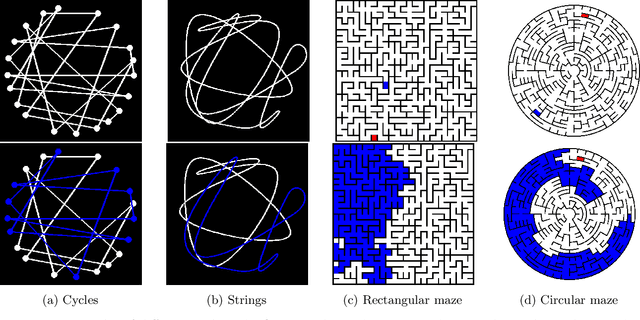

Modern vision models have achieved remarkable success in benchmarks where local features provide critical information about the target. There is now a growing interest in solving tasks that require more global reasoning, where local features offer no significant information. These tasks are reminiscent of the connectivity tasks discussed by Minsky and Papert in 1969, which exposed the limitations of the perceptron model and contributed to the first AI winter. In this paper, we revisit such tasks by introducing four global visual benchmarks involving path findings and mazes. We show that: (1) although today's large vision models largely surpass the expressivity limitations of the early models, they still struggle with the learning efficiency; we put forward the "globality degree" notion to understand this limitation; (2) we then demonstrate that the picture changes and global reasoning becomes feasible with the introduction of "visual scratchpads"; similarly to the text scratchpads and chain-of-thoughts used in language models, visual scratchpads help break down global tasks into simpler ones; (3) we finally show that some scratchpads are better than others, in particular, "inductive scratchpads" that take steps relying on less information afford better out-of-distribution generalization and succeed for smaller model sizes.
How Far Can Transformers Reason? The Locality Barrier and Inductive Scratchpad
Jun 10, 2024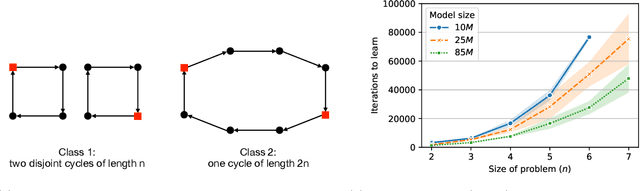
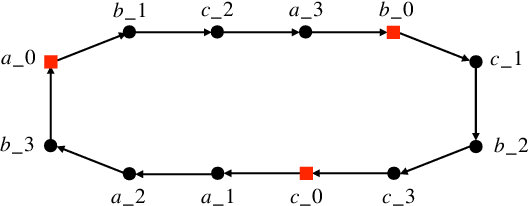
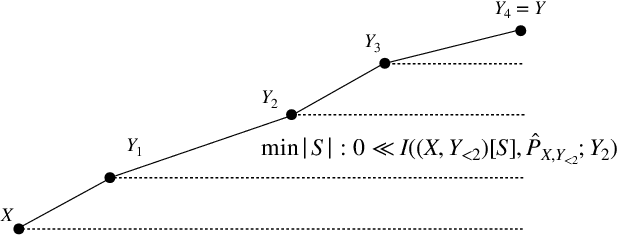
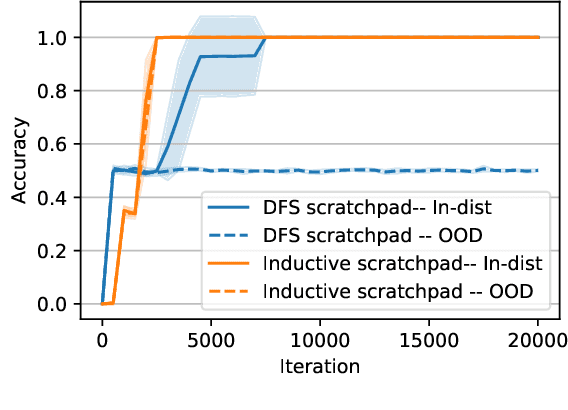
Can Transformers predict new syllogisms by composing established ones? More generally, what type of targets can be learned by such models from scratch? Recent works show that Transformers can be Turing-complete in terms of expressivity, but this does not address the learnability objective. This paper puts forward the notion of 'distribution locality' to capture when weak learning is efficiently achievable by regular Transformers, where the locality measures the least number of tokens required in addition to the tokens histogram to correlate nontrivially with the target. As shown experimentally and theoretically under additional assumptions, distributions with high locality cannot be learned efficiently. In particular, syllogisms cannot be composed on long chains. Furthermore, we show that (i) an agnostic scratchpad cannot help to break the locality barrier, (ii) an educated scratchpad can help if it breaks the locality at each step, (iii) a notion of 'inductive scratchpad' can both break the locality and improve the out-of-distribution generalization, e.g., generalizing to almost double input size for some arithmetic tasks.
Provable Advantage of Curriculum Learning on Parity Targets with Mixed Inputs
Jun 29, 2023



Experimental results have shown that curriculum learning, i.e., presenting simpler examples before more complex ones, can improve the efficiency of learning. Some recent theoretical results also showed that changing the sampling distribution can help neural networks learn parities, with formal results only for large learning rates and one-step arguments. Here we show a separation result in the number of training steps with standard (bounded) learning rates on a common sample distribution: if the data distribution is a mixture of sparse and dense inputs, there exists a regime in which a 2-layer ReLU neural network trained by a curriculum noisy-GD (or SGD) algorithm that uses sparse examples first, can learn parities of sufficiently large degree, while any fully connected neural network of possibly larger width or depth trained by noisy-GD on the unordered samples cannot learn without additional steps. We also provide experimental results supporting the qualitative separation beyond the specific regime of the theoretical results.
Generalization on the Unseen, Logic Reasoning and Degree Curriculum
Jan 30, 2023



This paper considers the learning of logical (Boolean) functions with focus on the generalization on the unseen (GOTU) setting, a strong case of out-of-distribution generalization. This is motivated by the fact that the rich combinatorial nature of data in certain reasoning tasks (e.g., arithmetic/logic) makes representative data sampling challenging, and learning successfully under GOTU gives a first vignette of an 'extrapolating' or 'reasoning' learner. We then study how different network architectures trained by (S)GD perform under GOTU and provide both theoretical and experimental evidence that for a class of network models including instances of Transformers, random features models, and diagonal linear networks, a min-degree-interpolator (MDI) is learned on the unseen. We also provide evidence that other instances with larger learning rates or mean-field networks reach leaky MDIs. These findings lead to two implications: (1) we provide an explanation to the length generalization problem (e.g., Anil et al. 2022); (2) we introduce a curriculum learning algorithm called Degree-Curriculum that learns monomials more efficiently by incrementing supports.
Learning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures
May 26, 2022
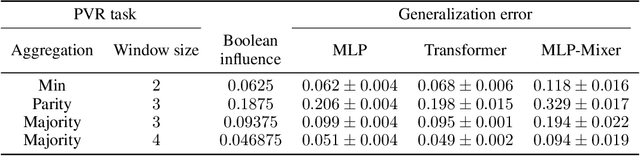
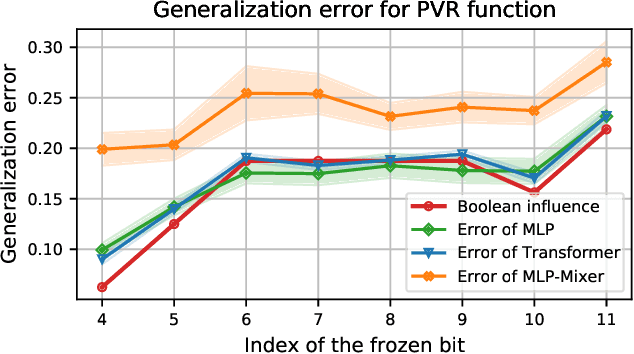
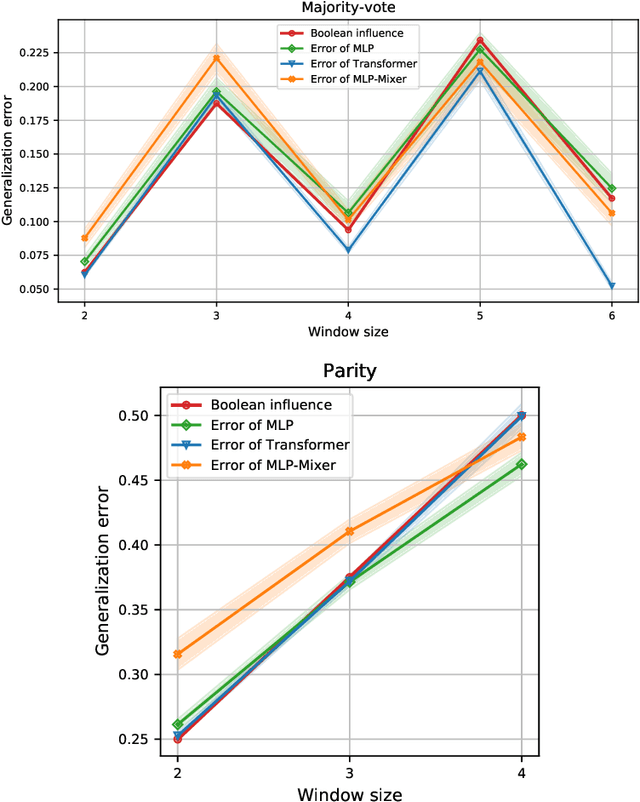
This paper considers the Pointer Value Retrieval (PVR) benchmark introduced in [ZRKB21], where a 'reasoning' function acts on a string of digits to produce the label. More generally, the paper considers the learning of logical functions with gradient descent (GD) on neural networks. It is first shown that in order to learn logical functions with gradient descent on symmetric neural networks, the generalization error can be lower-bounded in terms of the noise-stability of the target function, supporting a conjecture made in [ZRKB21]. It is then shown that in the distribution shift setting, when the data withholding corresponds to freezing a single feature (referred to as canonical holdout), the generalization error of gradient descent admits a tight characterization in terms of the Boolean influence for several relevant architectures. This is shown on linear models and supported experimentally on other models such as MLPs and Transformers. In particular, this puts forward the hypothesis that for such architectures and for learning logical functions such as PVR functions, GD tends to have an implicit bias towards low-degree representations, which in turn gives the Boolean influence for the generalization error under quadratic loss.
Semi-Supervised Disentanglement of Class-Related and Class-Independent Factors in VAE
Feb 01, 2021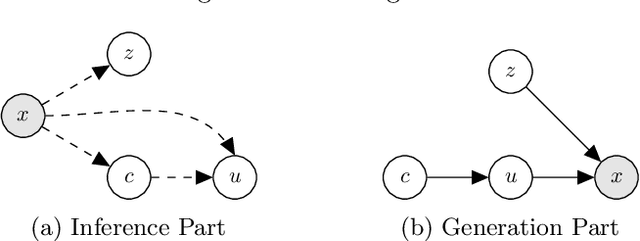
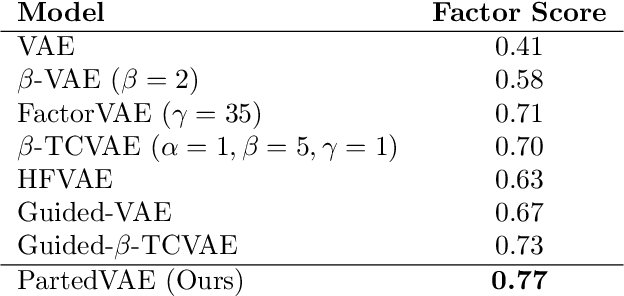
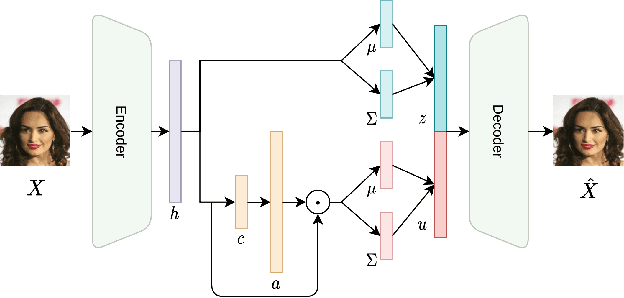
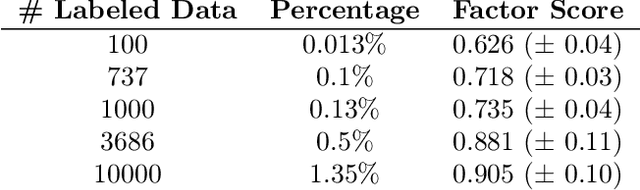
In recent years, extending variational autoencoder's framework to learn disentangled representations has received much attention. We address this problem by proposing a framework capable of disentangling class-related and class-independent factors of variation in data. Our framework employs an attention mechanism in its latent space in order to improve the process of extracting class-related factors from data. We also deal with the multimodality of data distribution by utilizing mixture models as learnable prior distributions, as well as incorporating the Bhattacharyya coefficient in the objective function to prevent highly overlapping mixtures. Our model's encoder is further trained in a semi-supervised manner, with a small fraction of labeled data, to improve representations' interpretability. Experiments show that our framework disentangles class-related and class-independent factors of variation and learns interpretable features. Moreover, we demonstrate our model's performance with quantitative and qualitative results on various datasets.