 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality-Attending Vision Transformer
Mar 05, 2026Vision transformers have demonstrated remarkable success in classification by leveraging global self-attention to capture long-range dependencies. However, this same mechanism can obscure fine-grained spatial details crucial for tasks such as segmentation. In this work, we seek to enhance segmentation performance of vision transformers after standard image-level classification training. More specifically, we present a simple yet effective add-on that improves performance on segmentation tasks while retaining vision transformers' image-level recognition capabilities. In our approach, we modulate the self-attention with a learnable Gaussian kernel that biases the attention toward neighboring patches. We further refine the patch representations to learn better embeddings at patch positions. These modifications encourage tokens to focus on local surroundings and ensure meaningful representations at spatial positions, while still preserving the model's ability to incorporate global information. Experiments demonstrate the effectiveness of our modifications, evidenced by substantial segmentation gains on three benchmarks (e.g., over 6% and 4% on ADE20K for ViT Tiny and Base), without changing the training regime or sacrificing classification performance. The code is available at https://github.com/sinahmr/LocAtViT/.
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Apr 12, 2024Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
A Closer Look at the Few-Shot Adaptation of Large Vision-Language Models
Dec 20, 2023Efficient transfer learning (ETL) is receiving increasing attention to adapt large pre-trained language-vision models on downstream tasks with a few labeled samples. While significant progress has been made, we reveal that state-of-the-art ETL approaches exhibit strong performance only in narrowly-defined experimental setups, and with a careful adjustment of hyperparameters based on a large corpus of labeled samples. In particular, we make two interesting, and surprising empirical observations. First, to outperform a simple Linear Probing baseline, these methods require to optimize their hyper-parameters on each target task. And second, they typically underperform -- sometimes dramatically -- standard zero-shot predictions in the presence of distributional drifts. Motivated by the unrealistic assumptions made in the existing literature, i.e., access to a large validation set and case-specific grid-search for optimal hyperparameters, we propose a novel approach that meets the requirements of real-world scenarios. More concretely, we introduce a CLass-Adaptive linear Probe (CLAP) objective, whose balancing term is optimized via an adaptation of the general Augmented Lagrangian method tailored to this context. We comprehensively evaluate CLAP on a broad span of datasets and scenarios, demonstrating that it consistently outperforms SoTA approaches, while yet being a much more efficient alternative.
A Strong Baseline for Generalized Few-Shot Semantic Segmentation
Nov 25, 2022This paper introduces a generalized few-shot segmentation framework with a straightforward training process and an easy-to-optimize inference phase. In particular, we propose a simple yet effective model based on the well-known InfoMax principle, where the Mutual Information (MI) between the learned feature representations and their corresponding predictions is maximized. In addition, the terms derived from our MI-based formulation are coupled with a knowledge distillation term to retain the knowledge on base classes. With a simple training process, our inference model can be applied on top of any segmentation network trained on base classes. The proposed inference yields substantial improvements on the popular few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$. Particularly, for novel classes, the improvement gains range from 5% to 20% (PASCAL-$5^i$) and from 2.5% to 10.5% (COCO-$20^i$) in the 1-shot and 5-shot scenarios, respectively. Furthermore, we propose a more challenging setting, where performance gaps are further exacerbated. Our code is publicly available at https://github.com/sinahmr/DIaM.
Semi-Supervised Disentanglement of Class-Related and Class-Independent Factors in VAE
Feb 01, 2021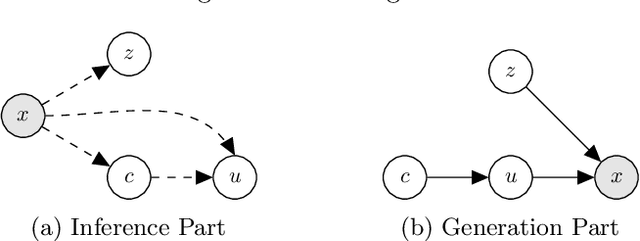
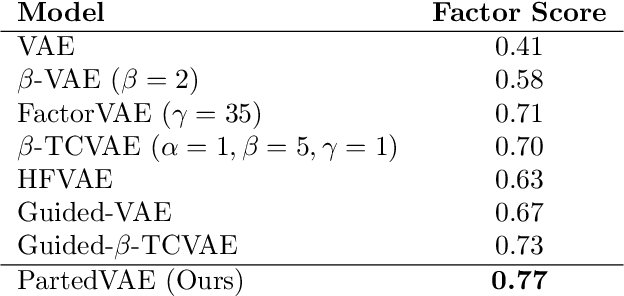
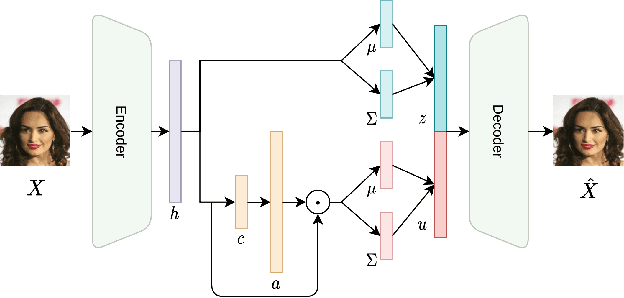
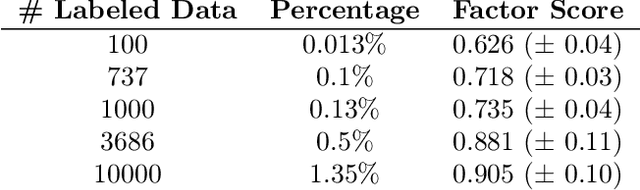
In recent years, extending variational autoencoder's framework to learn disentangled representations has received much attention. We address this problem by proposing a framework capable of disentangling class-related and class-independent factors of variation in data. Our framework employs an attention mechanism in its latent space in order to improve the process of extracting class-related factors from data. We also deal with the multimodality of data distribution by utilizing mixture models as learnable prior distributions, as well as incorporating the Bhattacharyya coefficient in the objective function to prevent highly overlapping mixtures. Our model's encoder is further trained in a semi-supervised manner, with a small fraction of labeled data, to improve representations' interpretability. Experiments show that our framework disentangles class-related and class-independent factors of variation and learns interpretable features. Moreover, we demonstrate our model's performance with quantitative and qualitative results on various datasets.