 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures
May 26, 2022
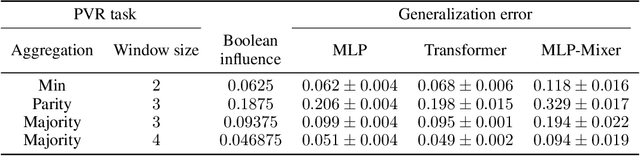
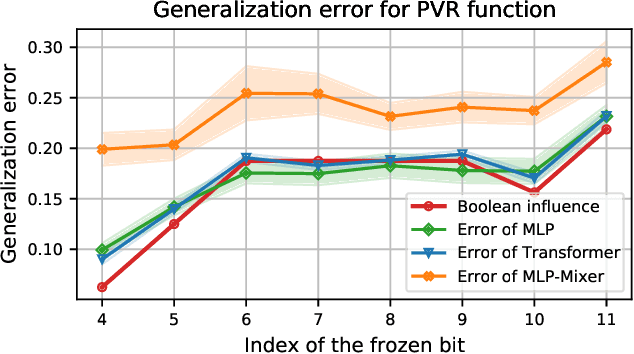
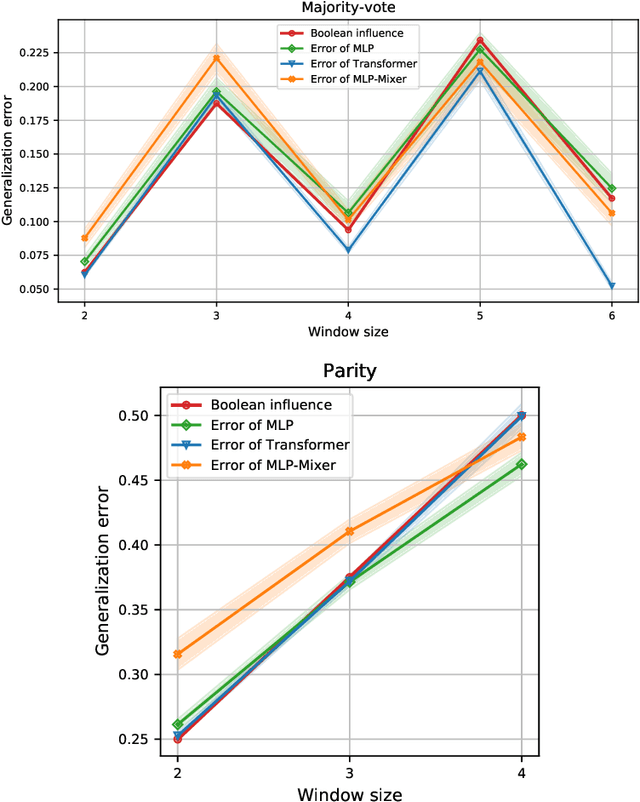
This paper considers the Pointer Value Retrieval (PVR) benchmark introduced in [ZRKB21], where a 'reasoning' function acts on a string of digits to produce the label. More generally, the paper considers the learning of logical functions with gradient descent (GD) on neural networks. It is first shown that in order to learn logical functions with gradient descent on symmetric neural networks, the generalization error can be lower-bounded in terms of the noise-stability of the target function, supporting a conjecture made in [ZRKB21]. It is then shown that in the distribution shift setting, when the data withholding corresponds to freezing a single feature (referred to as canonical holdout), the generalization error of gradient descent admits a tight characterization in terms of the Boolean influence for several relevant architectures. This is shown on linear models and supported experimentally on other models such as MLPs and Transformers. In particular, this puts forward the hypothesis that for such architectures and for learning logical functions such as PVR functions, GD tends to have an implicit bias towards low-degree representations, which in turn gives the Boolean influence for the generalization error under quadratic loss.
On the Origins of the Block Structure Phenomenon in Neural Network Representations
Feb 15, 2022
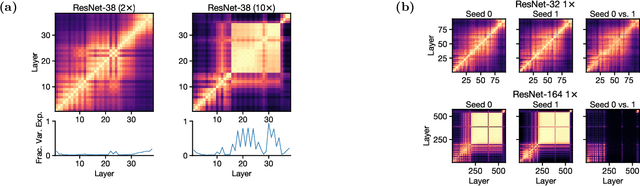


Recent work has uncovered a striking phenomenon in large-capacity neural networks: they contain blocks of contiguous hidden layers with highly similar representations. This block structure has two seemingly contradictory properties: on the one hand, its constituent layers exhibit highly similar dominant first principal components (PCs), but on the other hand, their representations, and their common first PC, are highly dissimilar across different random seeds. Our work seeks to reconcile these discrepant properties by investigating the origin of the block structure in relation to the data and training methods. By analyzing properties of the dominant PCs, we find that the block structure arises from dominant datapoints - a small group of examples that share similar image statistics (e.g. background color). However, the set of dominant datapoints, and the precise shared image statistic, can vary across random seeds. Thus, the block structure reflects meaningful dataset statistics, but is simultaneously unique to each model. Through studying hidden layer activations and creating synthetic datapoints, we demonstrate that these simple image statistics dominate the representational geometry of the layers inside the block structure. We explore how the phenomenon evolves through training, finding that the block structure takes shape early in training, but the underlying representations and the corresponding dominant datapoints continue to change substantially. Finally, we study the interplay between the block structure and different training mechanisms, introducing a targeted intervention to eliminate the block structure, as well as examining the effects of pretraining and Shake-Shake regularization.
Do Vision Transformers See Like Convolutional Neural Networks?
Aug 19, 2021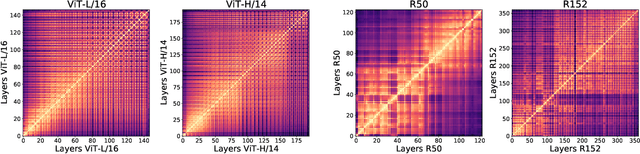
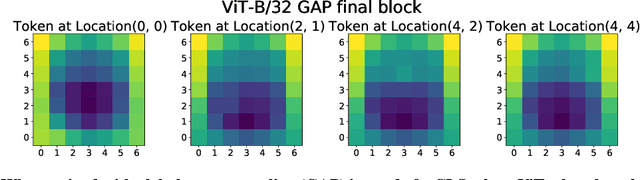
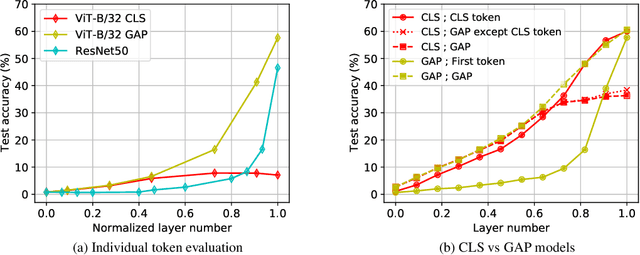
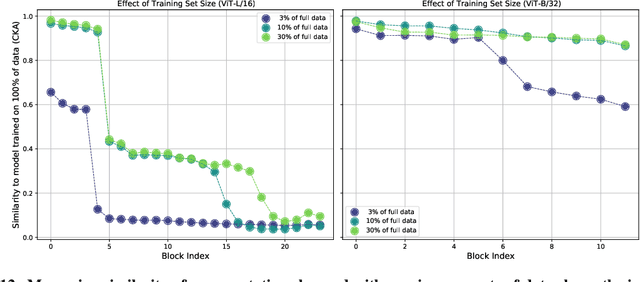
Convolutional neural networks (CNNs) have so far been the de-facto model for visual data. Recent work has shown that (Vision) Transformer models (ViT) can achieve comparable or even superior performance on image classification tasks. This raises a central question: how are Vision Transformers solving these tasks? Are they acting like convolutional networks, or learning entirely different visual representations? Analyzing the internal representation structure of ViTs and CNNs on image classification benchmarks, we find striking differences between the two architectures, such as ViT having more uniform representations across all layers. We explore how these differences arise, finding crucial roles played by self-attention, which enables early aggregation of global information, and ViT residual connections, which strongly propagate features from lower to higher layers. We study the ramifications for spatial localization, demonstrating ViTs successfully preserve input spatial information, with noticeable effects from different classification methods. Finally, we study the effect of (pretraining) dataset scale on intermediate features and transfer learning, and conclude with a discussion on connections to new architectures such as the MLP-Mixer.
Pointer Value Retrieval: A new benchmark for understanding the limits of neural network generalization
Jul 27, 2021



The successes of deep learning critically rely on the ability of neural networks to output meaningful predictions on unseen data -- generalization. Yet despite its criticality, there remain fundamental open questions on how neural networks generalize. How much do neural networks rely on memorization -- seeing highly similar training examples -- and how much are they capable of human-intelligence styled reasoning -- identifying abstract rules underlying the data? In this paper we introduce a novel benchmark, Pointer Value Retrieval (PVR) tasks, that explore the limits of neural network generalization. While PVR tasks can consist of visual as well as symbolic inputs, each with varying levels of difficulty, they all have a simple underlying rule. One part of the PVR task input acts as a pointer, giving the location of a different part of the input, which forms the value (and output). We demonstrate that this task structure provides a rich testbed for understanding generalization, with our empirical study showing large variations in neural network performance based on dataset size, task complexity and model architecture. The interaction of position, values and the pointer rule also allow the development of nuanced tests of generalization, by introducing distribution shift and increasing functional complexity. These reveal both subtle failures and surprising successes, suggesting many promising directions of exploration on this benchmark.
Teaching with Commentaries
Nov 05, 2020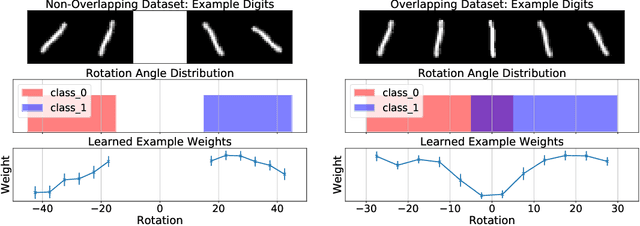

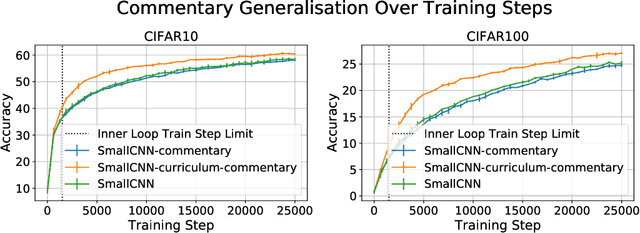
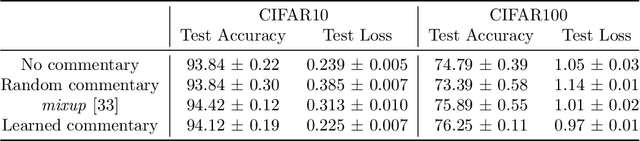
Effective training of deep neural networks can be challenging, and there remain many open questions on how to best learn these models. Recently developed methods to improve neural network training examine teaching: providing learned information during the training process to improve downstream model performance. In this paper, we take steps towards extending the scope of teaching. We propose a flexible teaching framework using commentaries, meta-learned information helpful for training on a particular task or dataset. We present an efficient and scalable gradient-based method to learn commentaries, leveraging recent work on implicit differentiation. We explore diverse applications of commentaries, from learning weights for individual training examples, to parameterizing label-dependent data augmentation policies, to representing attention masks that highlight salient image regions. In these settings, we find that commentaries can improve training speed and/or performance and also provide fundamental insights about the dataset and training process.
Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth
Oct 29, 2020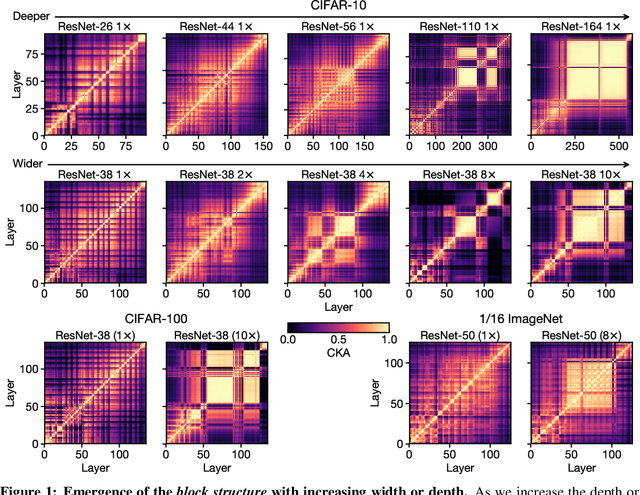

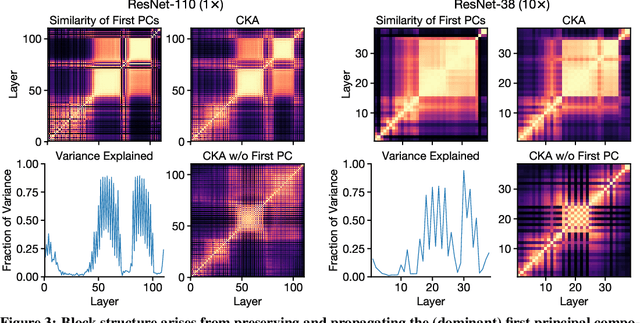
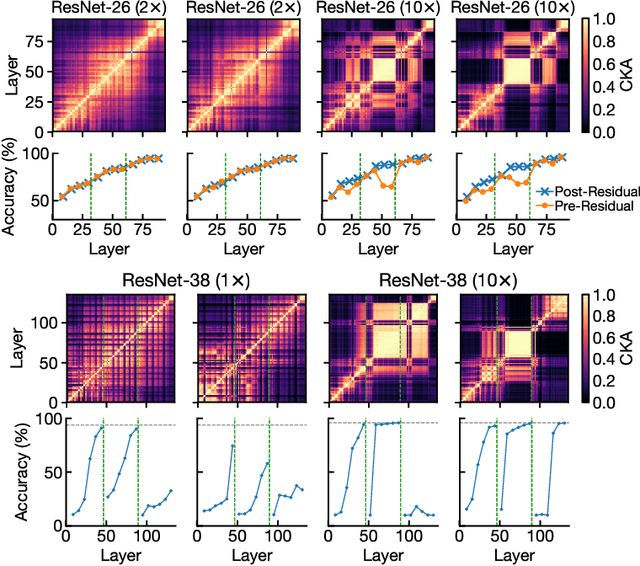
A key factor in the success of deep neural networks is the ability to scale models to improve performance by varying the architecture depth and width. This simple property of neural network design has resulted in highly effective architectures for a variety of tasks. Nevertheless, there is limited understanding of effects of depth and width on the learned representations. In this paper, we study this fundamental question. We begin by investigating how varying depth and width affects model hidden representations, finding a characteristic block structure in the hidden representations of larger capacity (wider or deeper) models. We demonstrate that this block structure arises when model capacity is large relative to the size of the training set, and is indicative of the underlying layers preserving and propagating the dominant principal component of their representations. This discovery has important ramifications for features learned by different models, namely, representations outside the block structure are often similar across architectures with varying widths and depths, but the block structure is unique to each model. We analyze the output predictions of different model architectures, finding that even when the overall accuracy is similar, wide and deep models exhibit distinctive error patterns and variations across classes.
Anatomy of Catastrophic Forgetting: Hidden Representations and Task Semantics
Jul 14, 2020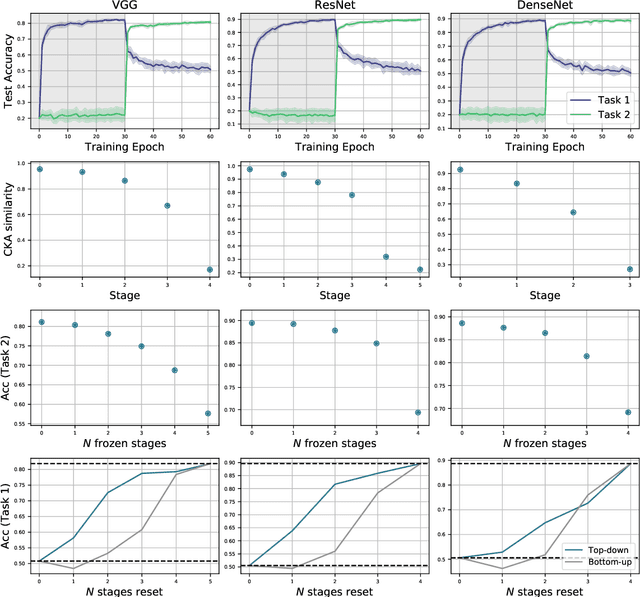
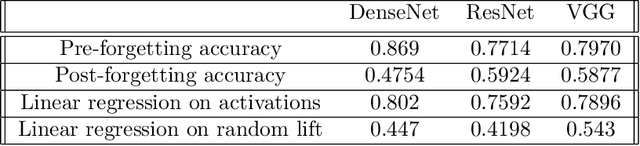
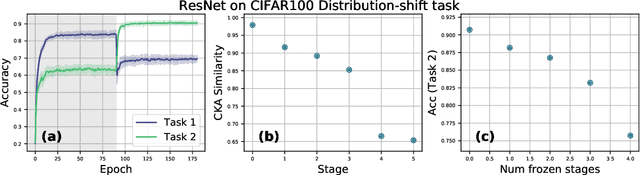

A central challenge in developing versatile machine learning systems is catastrophic forgetting: a model trained on tasks in sequence will suffer significant performance drops on earlier tasks. Despite the ubiquity of catastrophic forgetting, there is limited understanding of the underlying process and its causes. In this paper, we address this important knowledge gap, investigating how forgetting affects representations in neural network models. Through representational analysis techniques, we find that deeper layers are disproportionately the source of forgetting. Supporting this, a study of methods to mitigate forgetting illustrates that they act to stabilize deeper layers. These insights enable the development of an analytic argument and empirical picture relating the degree of forgetting to representational similarity between tasks. Consistent with this picture, we observe maximal forgetting occurs for task sequences with intermediate similarity. We perform empirical studies on the standard split CIFAR-10 setup and also introduce a novel CIFAR-100 based task approximating realistic input distribution shift.
A Survey of Deep Learning for Scientific Discovery
Mar 26, 2020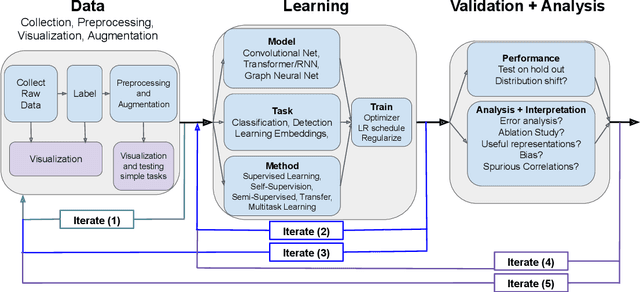
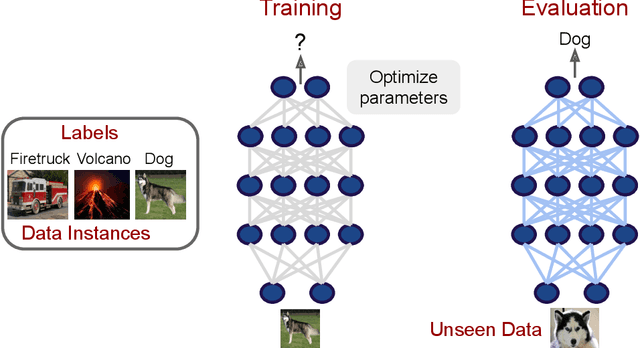
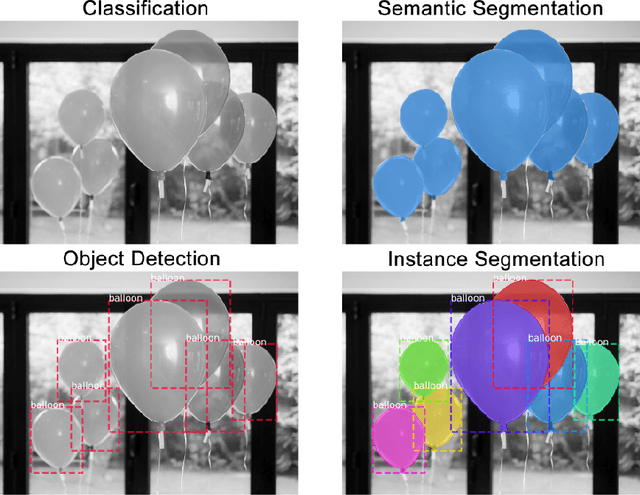

Over the past few years, we have seen fundamental breakthroughs in core problems in machine learning, largely driven by advances in deep neural networks. At the same time, the amount of data collected in a wide array of scientific domains is dramatically increasing in both size and complexity. Taken together, this suggests many exciting opportunities for deep learning applications in scientific settings. But a significant challenge to this is simply knowing where to start. The sheer breadth and diversity of different deep learning techniques makes it difficult to determine what scientific problems might be most amenable to these methods, or which specific combination of methods might offer the most promising first approach. In this survey, we focus on addressing this central issue, providing an overview of many widely used deep learning models, spanning visual, sequential and graph structured data, associated tasks and different training methods, along with techniques to use deep learning with less data and better interpret these complex models --- two central considerations for many scientific use cases. We also include overviews of the full design process, implementation tips, and links to a plethora of tutorials, research summaries and open-sourced deep learning pipelines and pretrained models, developed by the community. We hope that this survey will help accelerate the use of deep learning across different scientific domains.
Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
Sep 19, 2019

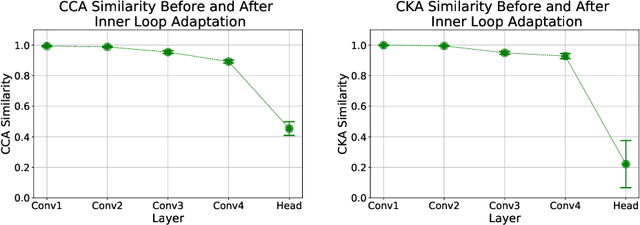

An important research direction in machine learning has centered around developing meta-learning algorithms to tackle few-shot learning. An especially successful algorithm has been Model Agnostic Meta-Learning (MAML), a method that consists of two optimization loops, with the outer loop finding a meta-initialization, from which the inner loop can efficiently learn new tasks. Despite MAML's popularity, a fundamental open question remains -- is the effectiveness of MAML due to the meta-initialization being primed for rapid learning (large, efficient changes in the representations) or due to feature reuse, with the meta initialization already containing high quality features? We investigate this question, via ablation studies and analysis of the latent representations, finding that feature reuse is the dominant factor. This leads to the ANIL (Almost No Inner Loop) algorithm, a simplification of MAML where we remove the inner loop for all but the (task-specific) head of a MAML-trained network. ANIL matches MAML's performance on benchmark few-shot image classification and RL and offers computational improvements over MAML. We further study the precise contributions of the head and body of the network, showing that performance on the test tasks is entirely determined by the quality of the learned features, and we can remove even the head of the network (the NIL algorithm). We conclude with a discussion of the rapid learning vs feature reuse question for meta-learning algorithms more broadly.
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort
Mar 28, 2019
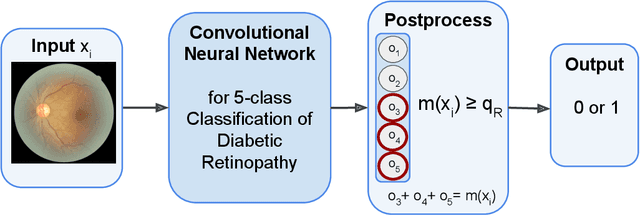
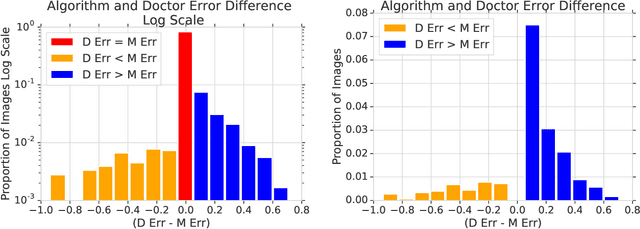
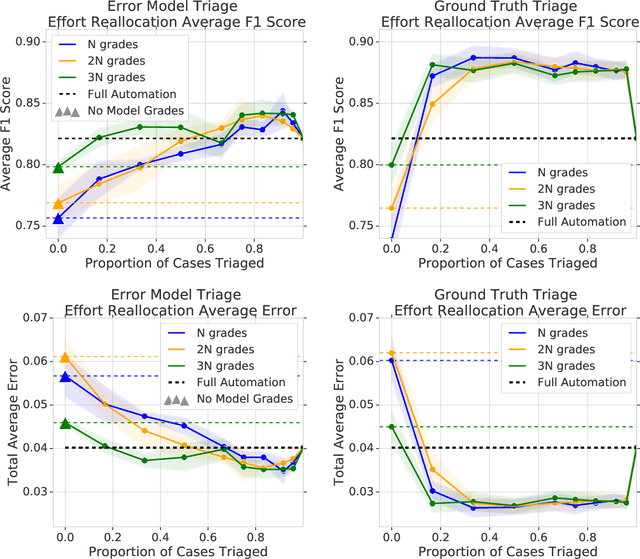
In a wide array of areas, algorithms are matching and surpassing the performance of human experts, leading to consideration of the roles of human judgment and algorithmic prediction in these domains. The discussion around these developments, however, has implicitly equated the specific task of prediction with the general task of automation. We argue here that automation is broader than just a comparison of human versus algorithmic performance on a task; it also involves the decision of which instances of the task to give to the algorithm in the first place. We develop a general framework that poses this latter decision as an optimization problem, and we show how basic heuristics for this optimization problem can lead to performance gains even on heavily-studied applications of AI in medicine. Our framework also serves to highlight how effective automation depends crucially on estimating both algorithmic and human error on an instance-by-instance basis, and our results show how improvements in these error estimation problems can yield significant gains for automation as well.