 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe geometry of integration in text classification RNNs
Oct 28, 2020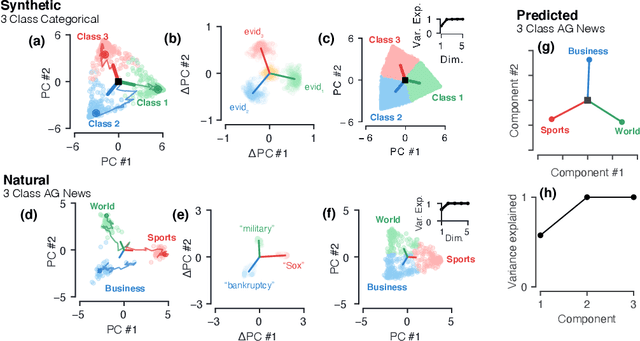
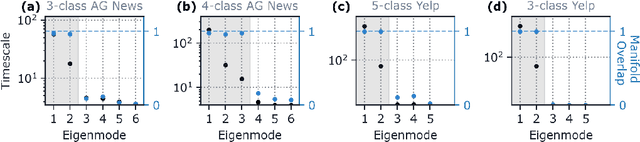
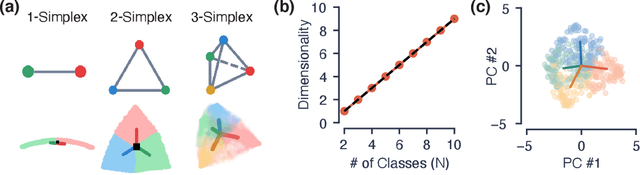
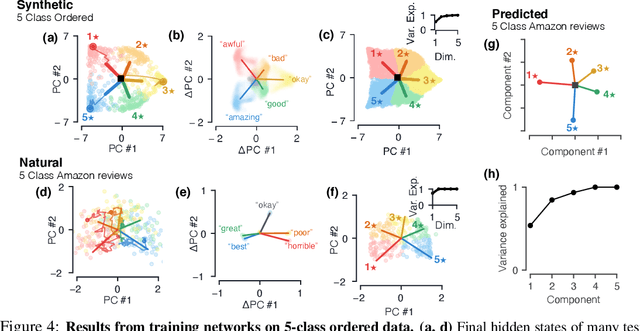
Despite the widespread application of recurrent neural networks (RNNs) across a variety of tasks, a unified understanding of how RNNs solve these tasks remains elusive. In particular, it is unclear what dynamical patterns arise in trained RNNs, and how those patterns depend on the training dataset or task. This work addresses these questions in the context of a specific natural language processing task: text classification. Using tools from dynamical systems analysis, we study recurrent networks trained on a battery of both natural and synthetic text classification tasks. We find the dynamics of these trained RNNs to be both interpretable and low-dimensional. Specifically, across architectures and datasets, RNNs accumulate evidence for each class as they process the text, using a low-dimensional attractor manifold as the underlying mechanism. Moreover, the dimensionality and geometry of the attractor manifold are determined by the structure of the training dataset; in particular, we describe how simple word-count statistics computed on the training dataset can be used to predict these properties. Our observations span multiple architectures and datasets, reflecting a common mechanism RNNs employ to perform text classification. To the degree that integration of evidence towards a decision is a common computational primitive, this work lays the foundation for using dynamical systems techniques to study the inner workings of RNNs.
Anatomy of Catastrophic Forgetting: Hidden Representations and Task Semantics
Jul 14, 2020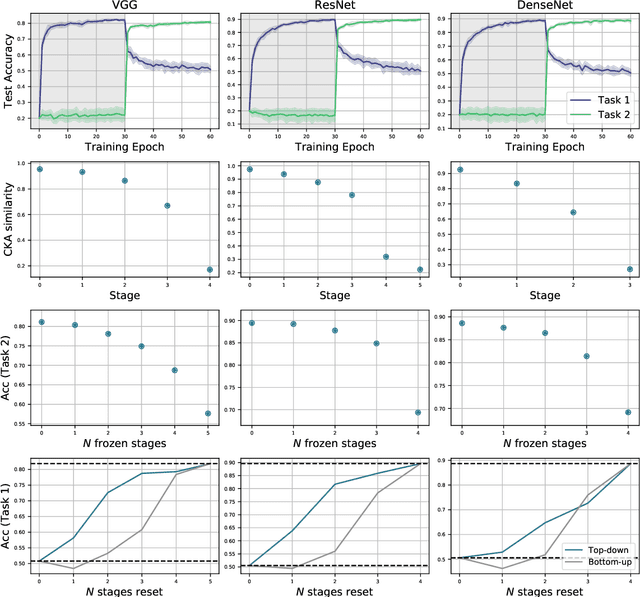
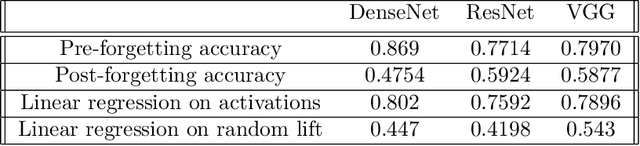
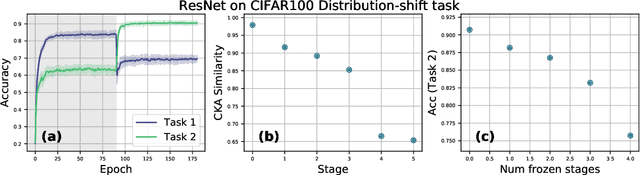

A central challenge in developing versatile machine learning systems is catastrophic forgetting: a model trained on tasks in sequence will suffer significant performance drops on earlier tasks. Despite the ubiquity of catastrophic forgetting, there is limited understanding of the underlying process and its causes. In this paper, we address this important knowledge gap, investigating how forgetting affects representations in neural network models. Through representational analysis techniques, we find that deeper layers are disproportionately the source of forgetting. Supporting this, a study of methods to mitigate forgetting illustrates that they act to stabilize deeper layers. These insights enable the development of an analytic argument and empirical picture relating the degree of forgetting to representational similarity between tasks. Consistent with this picture, we observe maximal forgetting occurs for task sequences with intermediate similarity. We perform empirical studies on the standard split CIFAR-10 setup and also introduce a novel CIFAR-100 based task approximating realistic input distribution shift.