 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperintelligence Strategy: Expert Version
Mar 07, 2025Rapid advances in AI are beginning to reshape national security. Destabilizing AI developments could rupture the balance of power and raise the odds of great-power conflict, while widespread proliferation of capable AI hackers and virologists would lower barriers for rogue actors to cause catastrophe. Superintelligence -- AI vastly better than humans at nearly all cognitive tasks -- is now anticipated by AI researchers. Just as nations once developed nuclear strategies to secure their survival, we now need a coherent superintelligence strategy to navigate a new period of transformative change. We introduce the concept of Mutual Assured AI Malfunction (MAIM): a deterrence regime resembling nuclear mutual assured destruction (MAD) where any state's aggressive bid for unilateral AI dominance is met with preventive sabotage by rivals. Given the relative ease of sabotaging a destabilizing AI project -- through interventions ranging from covert cyberattacks to potential kinetic strikes on datacenters -- MAIM already describes the strategic picture AI superpowers find themselves in. Alongside this, states can increase their competitiveness by bolstering their economies and militaries through AI, and they can engage in nonproliferation to rogue actors to keep weaponizable AI capabilities out of their hands. Taken together, the three-part framework of deterrence, nonproliferation, and competitiveness outlines a robust strategy to superintelligence in the years ahead.
A Survey of Deep Learning for Scientific Discovery
Mar 26, 2020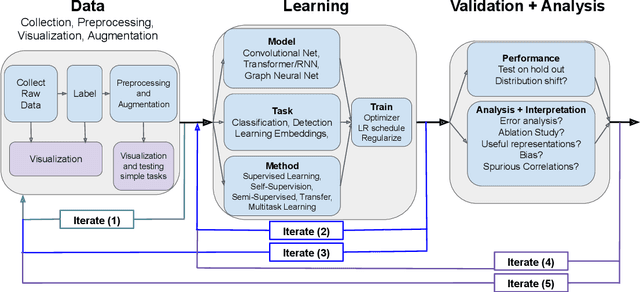
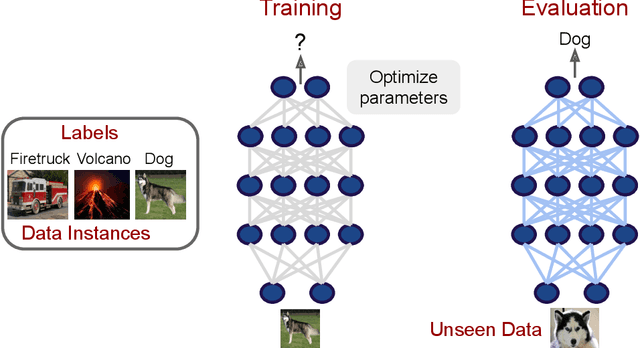
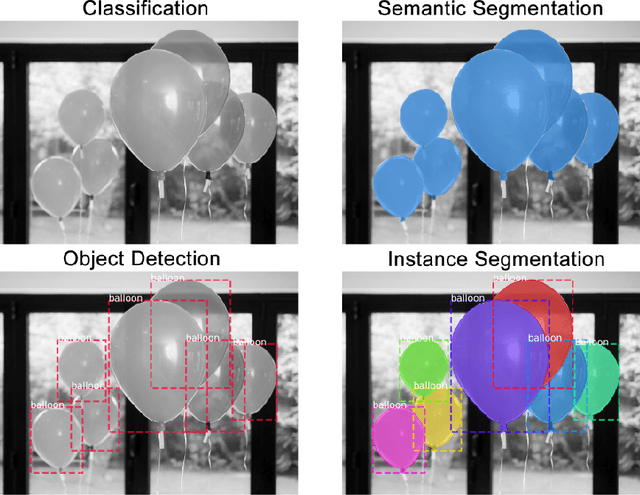

Over the past few years, we have seen fundamental breakthroughs in core problems in machine learning, largely driven by advances in deep neural networks. At the same time, the amount of data collected in a wide array of scientific domains is dramatically increasing in both size and complexity. Taken together, this suggests many exciting opportunities for deep learning applications in scientific settings. But a significant challenge to this is simply knowing where to start. The sheer breadth and diversity of different deep learning techniques makes it difficult to determine what scientific problems might be most amenable to these methods, or which specific combination of methods might offer the most promising first approach. In this survey, we focus on addressing this central issue, providing an overview of many widely used deep learning models, spanning visual, sequential and graph structured data, associated tasks and different training methods, along with techniques to use deep learning with less data and better interpret these complex models --- two central considerations for many scientific use cases. We also include overviews of the full design process, implementation tips, and links to a plethora of tutorials, research summaries and open-sourced deep learning pipelines and pretrained models, developed by the community. We hope that this survey will help accelerate the use of deep learning across different scientific domains.