 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Contrastive Spoken Language Understanding
Paper and Code
Oct 04, 2023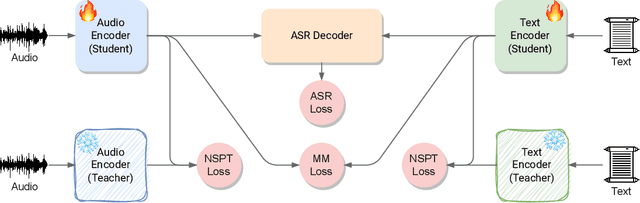
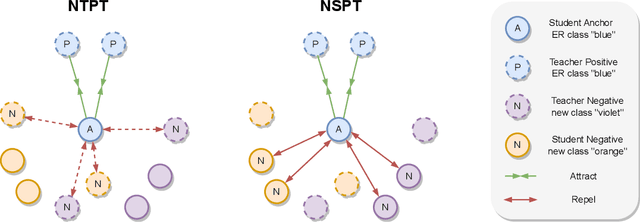


Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.