 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-based Layer Dropping (DLD): Effective End-to-end Framework for Dynamic Speech Networks
Jan 27, 2026Edge devices operate in constrained and varying resource settings, requiring dynamic architectures that can adapt to limitations of the available resources. To meet such demands, layer dropping ($\mathcal{LD}$) approach is typically used to transform static models into dynamic ones by skipping parts of the network along with reducing overall computational complexity. However, existing $\mathcal{LD}$ methods greatly impact the dynamic model's performance for low and high dropping cases, deteriorating the performance-computation trade-off. To this end, we propose a distillation-based layer dropping (DLD) framework that effectively combines the capabilities of knowledge distillation and $\mathcal{LD}$ in an end-to-end fashion, thereby achieving state-of-the-art performance for dynamic speech networks. Comprehensive experimentation utilizing well-known speech recognition methods, including conformer and WavLM, on three public benchmarks demonstrates the effectiveness of our framework, reducing the word error rate by $9.32\%$ and $2.25\%$ for high and no dropping cases with $33.3\%$ reduction in training time.
Input Conditioned Layer Dropping in Speech Foundation Models
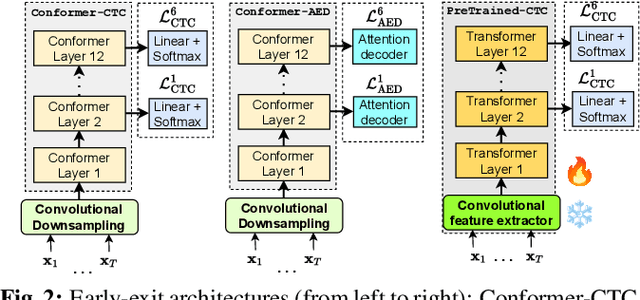
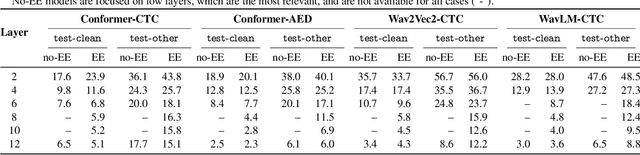
Jul 10, 2025Curating foundation speech models for edge and IoT settings, where computational resources vary over time, requires dynamic architectures featuring adaptable reduction strategies. One emerging approach is layer dropping ($\mathcal{LD}$) which skips fraction of the layers of a backbone network during inference to reduce the computational load. This allows transforming static models into dynamic ones. However, existing approaches exhibit limitations either in the mode of selecting layers or by significantly modifying the neural architecture. To this end, we propose input-driven $\mathcal{LD}$ that employs the network's input features and a lightweight layer selecting network to determine the optimum combination of processing layers. Extensive experimentation on 4 speech and audio public benchmarks, using two different pre-trained foundation models, demonstrates the effectiveness of our approach, thoroughly outperforming random dropping and producing on-par (or better) results to early exit.
Scaling and Enhancing LLM-based AVSR: A Sparse Mixture of Projectors Approach
May 21, 2025Audio-Visual Speech Recognition (AVSR) enhances robustness in noisy environments by integrating visual cues. While recent advances integrate Large Language Models (LLMs) into AVSR, their high computational cost hinders deployment in resource-constrained settings. To address this, we propose Llama-SMoP, an efficient Multimodal LLM that employs a Sparse Mixture of Projectors (SMoP) module to scale model capacity without increasing inference costs. By incorporating sparsely-gated mixture-of-experts (MoE) projectors, Llama-SMoP enables the use of smaller LLMs while maintaining strong performance. We explore three SMoP configurations and show that Llama-SMoP DEDR (Disjoint-Experts, Disjoint-Routers), which uses modality-specific routers and experts, achieves superior performance on ASR, VSR, and AVSR tasks. Ablation studies confirm its effectiveness in expert activation, scalability, and noise robustness.
Federating Dynamic Models using Early-Exit Architectures for Automatic Speech Recognition on Heterogeneous Clients
May 27, 2024Automatic speech recognition models require large amounts of speech recordings for training. However, the collection of such data often is cumbersome and leads to privacy concerns. Federated learning has been widely used as an effective decentralized technique that collaboratively learns a shared prediction model while keeping the data local on different clients. Unfortunately, client devices often feature limited computation and communication resources leading to practical difficulties for large models. In addition, the heterogeneity that characterizes edge devices makes it sub-optimal to generate a single model that fits all of them. Differently from the recent literature, where multiple models with different architectures are used, in this work, we propose using dynamical architectures which, employing early-exit solutions, can adapt their processing (i.e. traversed layers) depending on the input and on the operation conditions. This solution falls in the realm of partial training methods and brings two benefits: a single model is used on a variety of devices; federating the models after local training is straightforward. Experiments on public datasets show that our proposed approach is effective and can be combined with basic federated learning strategies.
Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters
Feb 01, 2024Mixture of Experts (MoE) architectures have recently started burgeoning due to their ability to scale model's capacity while maintaining the computational cost affordable. Furthermore, they can be applied to both Transformers and State Space Models, the current state-of-the-art models in numerous fields. While MoE has been mostly investigated for the pre-training stage, its use in parameter-efficient transfer learning settings is under-explored. To narrow this gap, this paper attempts to demystify the use of MoE for parameter-efficient fine-tuning of Audio Spectrogram Transformers to audio and speech downstream tasks. Specifically, we propose Soft Mixture of Adapters (Soft-MoA). It exploits adapters as the experts and, leveraging the recent Soft MoE method, it relies on a soft assignment between the input tokens and experts to keep the computational time limited. Extensive experiments across 4 benchmarks demonstrate that Soft-MoA outperforms the single adapter method and performs on par with the dense MoA counterpart. We finally present ablation studies on key elements of Soft-MoA, showing for example that Soft-MoA achieves better scaling with more experts, as well as ensuring that all experts contribute to the computation of the output tokens, thus dispensing with the expert imbalance issue.
Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers
Dec 07, 2023The common modus operandi of fine-tuning large pre-trained Transformer models entails the adaptation of all their parameters (i.e., full fine-tuning). While achieving striking results on multiple tasks, this approach becomes unfeasible as the model size and the number of downstream tasks increase. In natural language processing and computer vision, parameter-efficient approaches like prompt-tuning and adapters have emerged as solid alternatives by fine-tuning only a small number of extra parameters, without sacrificing performance accuracy. Specifically, adapters, due to their flexibility, have recently garnered significant attention, leading to several variants. For audio classification tasks, the Audio Spectrogram Transformer model shows impressive results. However, surprisingly, how to efficiently adapt it to several downstream tasks has not been tackled before. In this paper, we bridge this gap and present a detailed investigation of common parameter-efficient methods, revealing that adapters consistently outperform the other methods across four benchmarks. This trend is also confirmed in few-shot learning settings and when the total number of trainable parameters increases, demonstrating adapters superior scalability. We finally study the best adapter configuration, as well as the role of residual connections in the learning process.
Continual Contrastive Spoken Language Understanding
Oct 04, 2023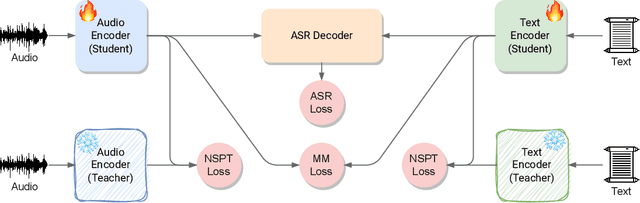
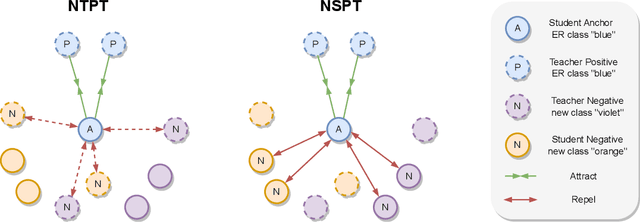


Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.
Training dynamic models using early exits for automatic speech recognition on resource-constrained devices
Sep 18, 2023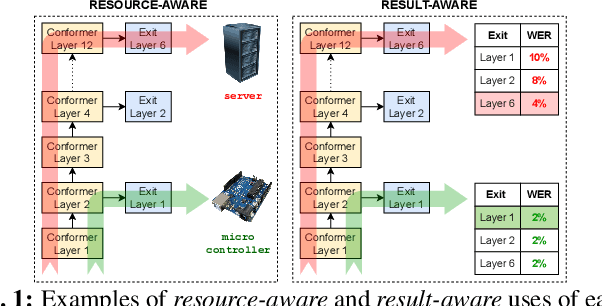
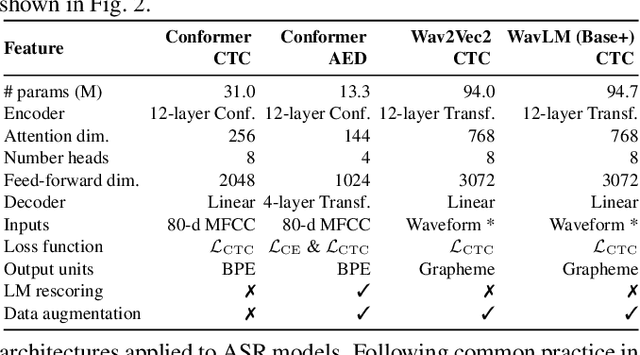
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.
Sequence-Level Knowledge Distillation for Class-Incremental End-to-End Spoken Language Understanding
May 23, 2023The ability to learn new concepts sequentially is a major weakness for modern neural networks, which hinders their use in non-stationary environments. Their propensity to fit the current data distribution to the detriment of the past acquired knowledge leads to the catastrophic forgetting issue. In this work we tackle the problem of Spoken Language Understanding applied to a continual learning setting. We first define a class-incremental scenario for the SLURP dataset. Then, we propose three knowledge distillation (KD) approaches to mitigate forgetting for a sequence-to-sequence transformer model: the first KD method is applied to the encoder output (audio-KD), and the other two work on the decoder output, either directly on the token-level (tok-KD) or on the sequence-level (seq-KD) distributions. We show that the seq-KD substantially improves all the performance metrics, and its combination with the audio-KD further decreases the average WER and enhances the entity prediction metric.
Improving the Intent Classification accuracy in Noisy Environment
Mar 12, 2023Intent classification is a fundamental task in the spoken language understanding field that has recently gained the attention of the scientific community, mainly because of the feasibility of approaching it with end-to-end neural models. In this way, avoiding using intermediate steps, i.e. automatic speech recognition, is possible, thus the propagation of errors due to background noise, spontaneous speech, speaking styles of users, etc. Towards the development of solutions applicable in real scenarios, it is interesting to investigate how environmental noise and related noise reduction techniques to address the intent classification task with end-to-end neural models. In this paper, we experiment with a noisy version of the fluent speech command data set, combining the intent classifier with a time-domain speech enhancement solution based on Wave-U-Net and considering different training strategies. Experimental results reveal that, for this task, the use of speech enhancement greatly improves the classification accuracy in noisy conditions, in particular when the classification model is trained on enhanced signals.