 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining dynamic models using early exits for automatic speech recognition on resource-constrained devices
Paper and Code
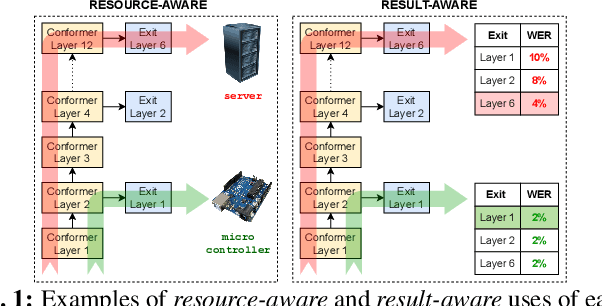
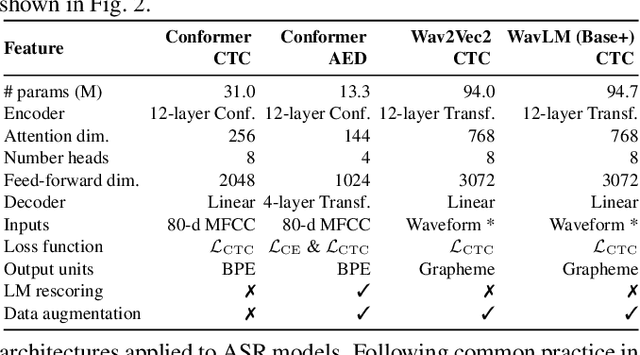
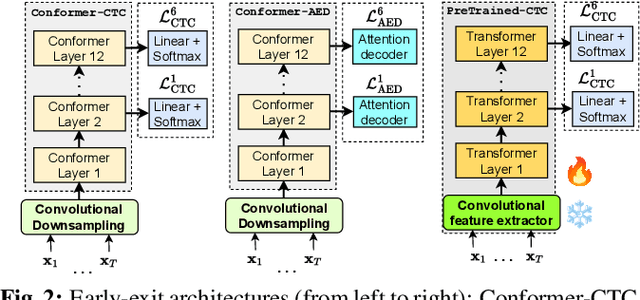
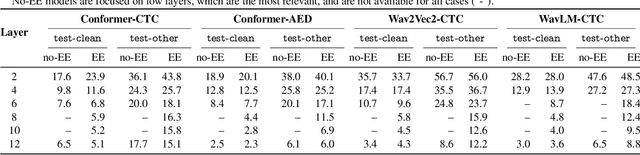
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.