 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambAdapter: Lightweight Mamba-Based Adapters for Parameter-Efficient Transfer Learning in Speech and Audio
Jun 14, 2026Fine-tuning Transformer-based foundation models has become the dominant strategy for domain adaptation in audio and speech processing. To reduce the computational and memory costs of this process, parameter-efficient transfer learning (PETL) methods have been widely explored. Meanwhile, Mamba, a recent state-space model, has emerged as a promising alternative to Transformers for sequence modeling. In this work, we present MambAdapter, a parameter-efficient transfer learning approach that integrates Mamba into low-rank bottleneck adapters. Our design combines parameter sharing across adapters with the injection of a lightweight Mamba module, enabling more effective modeling of audio features. We demonstrate that MambAdapter matches or outperforms strong PETL baselines on four audio classification tasks and five speech recognition languages, even when operating under reduced parameter budgets.
Dr. SHAP-AV: Decoding Relative Modality Contributions via Shapley Attribution in Audio-Visual Speech Recognition
Mar 12, 2026Audio-Visual Speech Recognition (AVSR) leverages both acoustic and visual information for robust recognition under noise. However, how models balance these modalities remains unclear. We present Dr. SHAP-AV, a framework using Shapley values to analyze modality contributions in AVSR. Through experiments on six models across two benchmarks and varying SNR levels, we introduce three analyses: Global SHAP for overall modality balance, Generative SHAP for contribution dynamics during decoding, and Temporal Alignment SHAP for input-output correspondence. Our findings reveal that models shift toward visual reliance under noise yet maintain high audio contributions even under severe degradation. Modality balance evolves during generation, temporal alignment holds under noise, and SNR is the dominant factor driving modality weighting. These findings expose a persistent audio bias, motivating ad-hoc modality-weighting mechanisms and Shapley-based attribution as a standard AVSR diagnostic.
Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
Nov 10, 2025Large language models (LLMs) have recently achieved impressive results in speech recognition across multiple modalities, including Auditory Speech Recognition (ASR), Visual Speech Recognition (VSR), and Audio-Visual Speech Recognition (AVSR). Despite this progress, current LLM-based approaches typically address each task independently, training separate models that raise computational and deployment resource use while missing potential cross-task synergies. They also rely on fixed-rate token compression, which restricts flexibility in balancing accuracy with efficiency. These limitations highlight the need for a unified framework that can support ASR, VSR, and AVSR while enabling elastic inference. To this end, we present Omni-AVSR, a unified audio-visual LLM that combines efficient multi-granularity training with parameter-efficient adaptation. Specifically, we adapt the matryoshka representation learning paradigm to efficiently train across multiple audio and visual granularities, reducing its inherent training resource use. Furthermore, we explore three LoRA-based strategies for adapting the backbone LLM, balancing shared and task-specific specialization. Experiments on LRS2 and LRS3 show that Omni-AVSR achieves comparable or superior accuracy to state-of-the-art baselines while training a single model at substantially lower training and deployment resource use. The model also remains robust under acoustic noise, and we analyze its scaling behavior as LLM size increases, providing insights into the trade-off between performance and efficiency.
Mitigating Attention Sinks and Massive Activations in Audio-Visual Speech Recognition with LLMS
Oct 26, 2025Large language models (LLMs) have recently advanced auditory speech recognition (ASR), visual speech recognition (VSR), and audio-visual speech recognition (AVSR). However, understanding of their internal dynamics under fine-tuning remains limited. In natural language processing, recent work has revealed attention sinks, tokens that attract disproportionately high attention, and associated massive activations in which some features of sink tokens exhibit huge activation in LLMs. In this work, we are the first to study these phenomena in multimodal speech recognition. Through a detailed analysis of audio-visual LLMs, we identify attention sinks and massive activations not only at the BOS token but also at intermediate low-semantic tokens across ASR, VSR, and AVSR. We show that massive activations originate in the MLP layers and correspond to fixed feature indices across all sink tokens. We further show that intermediate sink tokens exhibit high cosine similarity to the BOS token, thereby amplifying attention and activation. Building on these insights, we introduce a simple decorrelation loss that reduces cosine similarity between BOS and other tokens, effectively mitigating intermediate sinks and massive activations. Furthermore, our method improves word error rate (WER) under high audio-visual feature downsampling while remaining stable at lower downsampling rates.
Scaling and Enhancing LLM-based AVSR: A Sparse Mixture of Projectors Approach
May 21, 2025Audio-Visual Speech Recognition (AVSR) enhances robustness in noisy environments by integrating visual cues. While recent advances integrate Large Language Models (LLMs) into AVSR, their high computational cost hinders deployment in resource-constrained settings. To address this, we propose Llama-SMoP, an efficient Multimodal LLM that employs a Sparse Mixture of Projectors (SMoP) module to scale model capacity without increasing inference costs. By incorporating sparsely-gated mixture-of-experts (MoE) projectors, Llama-SMoP enables the use of smaller LLMs while maintaining strong performance. We explore three SMoP configurations and show that Llama-SMoP DEDR (Disjoint-Experts, Disjoint-Routers), which uses modality-specific routers and experts, achieves superior performance on ASR, VSR, and AVSR tasks. Ablation studies confirm its effectiveness in expert activation, scalability, and noise robustness.
Adaptive Audio-Visual Speech Recognition via Matryoshka-Based Multimodal LLMs
Mar 09, 2025Audio-Visual Speech Recognition (AVSR) leverages both audio and visual modalities to enhance speech recognition robustness, particularly in noisy environments. Recent advancements in Large Language Models (LLMs) have demonstrated their effectiveness in speech recognition, including AVSR. However, due to the significant length of speech representations, direct integration with LLMs imposes substantial computational costs. Prior approaches address this by compressing speech representations before feeding them into LLMs. However, higher compression ratios often lead to performance degradation, necessitating a trade-off between computational efficiency and recognition accuracy. To address this challenge, we propose Llama-MTSK, the first Matryoshka-based Multimodal LLM for AVSR, which enables flexible adaptation of the audio-visual token allocation based on specific computational constraints while preserving high performance. Our approach, inspired by Matryoshka Representation Learning, encodes audio-visual representations at multiple granularities within a single model, eliminating the need to train separate models for different compression levels. Moreover, to efficiently fine-tune the LLM, we introduce three LoRA-based Matryoshka strategies using global and scale-specific LoRA modules. Extensive evaluations on the two largest AVSR datasets demonstrate that Llama-MTSK achieves state-of-the-art results, matching or surpassing models trained independently at fixed compression levels.
Evaluating and Improving Continual Learning in Spoken Language Understanding
Feb 16, 2024Continual learning has emerged as an increasingly important challenge across various tasks, including Spoken Language Understanding (SLU). In SLU, its objective is to effectively handle the emergence of new concepts and evolving environments. The evaluation of continual learning algorithms typically involves assessing the model's stability, plasticity, and generalizability as fundamental aspects of standards. However, existing continual learning metrics primarily focus on only one or two of the properties. They neglect the overall performance across all tasks, and do not adequately disentangle the plasticity versus stability/generalizability trade-offs within the model. In this work, we propose an evaluation methodology that provides a unified evaluation on stability, plasticity, and generalizability in continual learning. By employing the proposed metric, we demonstrate how introducing various knowledge distillations can improve different aspects of these three properties of the SLU model. We further show that our proposed metric is more sensitive in capturing the impact of task ordering in continual learning, making it better suited for practical use-case scenarios.
Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters
Feb 01, 2024Mixture of Experts (MoE) architectures have recently started burgeoning due to their ability to scale model's capacity while maintaining the computational cost affordable. Furthermore, they can be applied to both Transformers and State Space Models, the current state-of-the-art models in numerous fields. While MoE has been mostly investigated for the pre-training stage, its use in parameter-efficient transfer learning settings is under-explored. To narrow this gap, this paper attempts to demystify the use of MoE for parameter-efficient fine-tuning of Audio Spectrogram Transformers to audio and speech downstream tasks. Specifically, we propose Soft Mixture of Adapters (Soft-MoA). It exploits adapters as the experts and, leveraging the recent Soft MoE method, it relies on a soft assignment between the input tokens and experts to keep the computational time limited. Extensive experiments across 4 benchmarks demonstrate that Soft-MoA outperforms the single adapter method and performs on par with the dense MoA counterpart. We finally present ablation studies on key elements of Soft-MoA, showing for example that Soft-MoA achieves better scaling with more experts, as well as ensuring that all experts contribute to the computation of the output tokens, thus dispensing with the expert imbalance issue.
Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers
Dec 07, 2023The common modus operandi of fine-tuning large pre-trained Transformer models entails the adaptation of all their parameters (i.e., full fine-tuning). While achieving striking results on multiple tasks, this approach becomes unfeasible as the model size and the number of downstream tasks increase. In natural language processing and computer vision, parameter-efficient approaches like prompt-tuning and adapters have emerged as solid alternatives by fine-tuning only a small number of extra parameters, without sacrificing performance accuracy. Specifically, adapters, due to their flexibility, have recently garnered significant attention, leading to several variants. For audio classification tasks, the Audio Spectrogram Transformer model shows impressive results. However, surprisingly, how to efficiently adapt it to several downstream tasks has not been tackled before. In this paper, we bridge this gap and present a detailed investigation of common parameter-efficient methods, revealing that adapters consistently outperform the other methods across four benchmarks. This trend is also confirmed in few-shot learning settings and when the total number of trainable parameters increases, demonstrating adapters superior scalability. We finally study the best adapter configuration, as well as the role of residual connections in the learning process.
Continual Contrastive Spoken Language Understanding
Oct 04, 2023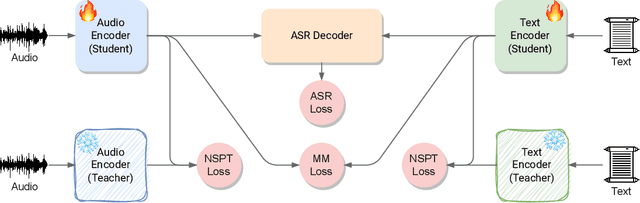
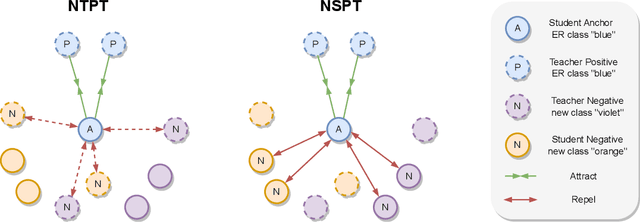


Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.