 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexTok: Resampling Images into 1D Token Sequences of Flexible Length
Feb 19, 2025Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image's inherent complexity. We introduce FlexTok, a tokenizer that projects 2D images into variable-length, ordered 1D token sequences. For example, a 256x256 image can be resampled into anywhere from 1 to 256 discrete tokens, hierarchically and semantically compressing its information. By training a rectified flow model as the decoder and using nested dropout, FlexTok produces plausible reconstructions regardless of the chosen token sequence length. We evaluate our approach in an autoregressive generation setting using a simple GPT-style Transformer. On ImageNet, this approach achieves an FID<2 across 8 to 128 tokens, outperforming TiTok and matching state-of-the-art methods with far fewer tokens. We further extend the model to support to text-conditioned image generation and examine how FlexTok relates to traditional 2D tokenization. A key finding is that FlexTok enables next-token prediction to describe images in a coarse-to-fine "visual vocabulary", and that the number of tokens to generate depends on the complexity of the generation task.
Understanding Alignment in Multimodal LLMs: A Comprehensive Study
Jul 02, 2024



Preference alignment has become a crucial component in enhancing the performance of Large Language Models (LLMs), yet its impact in Multimodal Large Language Models (MLLMs) remains comparatively underexplored. Similar to language models, MLLMs for image understanding tasks encounter challenges like hallucination. In MLLMs, hallucination can occur not only by stating incorrect facts but also by producing responses that are inconsistent with the image content. A primary objective of alignment for MLLMs is to encourage these models to align responses more closely with image information. Recently, multiple works have introduced preference datasets for MLLMs and examined different alignment methods, including Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). However, due to variations in datasets, base model types, and alignment methods, it remains unclear which specific elements contribute most significantly to the reported improvements in these works. In this paper, we independently analyze each aspect of preference alignment in MLLMs. We start by categorizing the alignment algorithms into two groups, offline (such as DPO), and online (such as online-DPO), and show that combining offline and online methods can improve the performance of the model in certain scenarios. We review a variety of published multimodal preference datasets and discuss how the details of their construction impact model performance. Based on these insights, we introduce a novel way of creating multimodal preference data called Bias-Driven Hallucination Sampling (BDHS) that needs neither additional annotation nor external models, and show that it can achieve competitive performance to previously published alignment work for multimodal models across a range of benchmarks.
LatentFormer: Multi-Agent Transformer-Based Interaction Modeling and Trajectory Prediction
Mar 03, 2022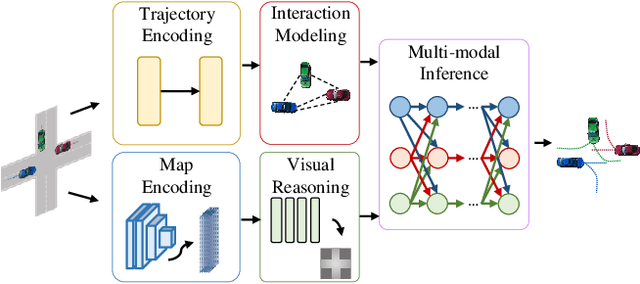
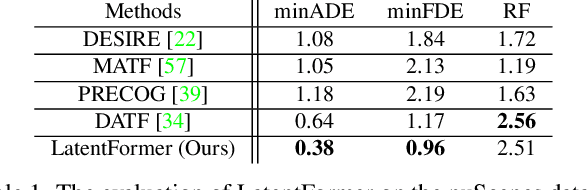
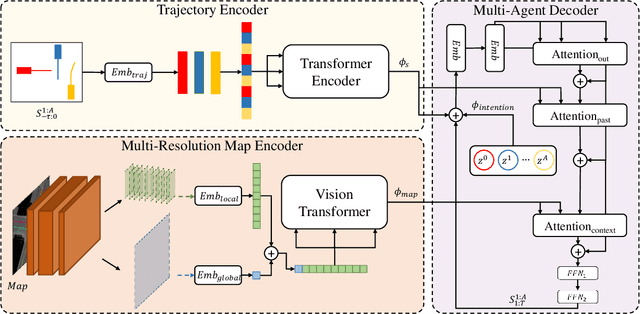

Multi-agent trajectory prediction is a fundamental problem in autonomous driving. The key challenges in prediction are accurately anticipating the behavior of surrounding agents and understanding the scene context. To address these problems, we propose LatentFormer, a transformer-based model for predicting future vehicle trajectories. The proposed method leverages a novel technique for modeling interactions among dynamic objects in the scene. Contrary to many existing approaches which model cross-agent interactions during the observation time, our method additionally exploits the future states of the agents. This is accomplished using a hierarchical attention mechanism where the evolving states of the agents autoregressively control the contributions of past trajectories and scene encodings in the final prediction. Furthermore, we propose a multi-resolution map encoding scheme that relies on a vision transformer module to effectively capture both local and global scene context to guide the generation of more admissible future trajectories. We evaluate the proposed method on the nuScenes benchmark dataset and show that our approach achieves state-of-the-art performance and improves upon trajectory metrics by up to 40%. We further investigate the contributions of various components of the proposed technique via extensive ablation studies.
Self-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Mar 01, 2021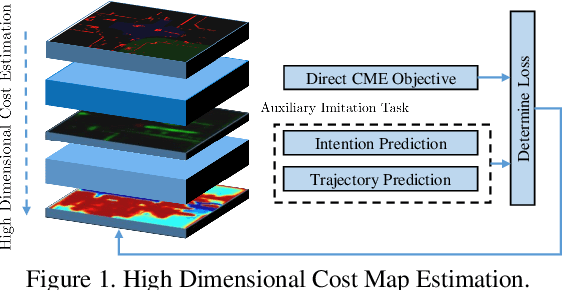
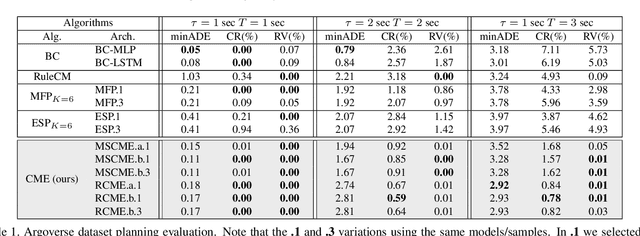
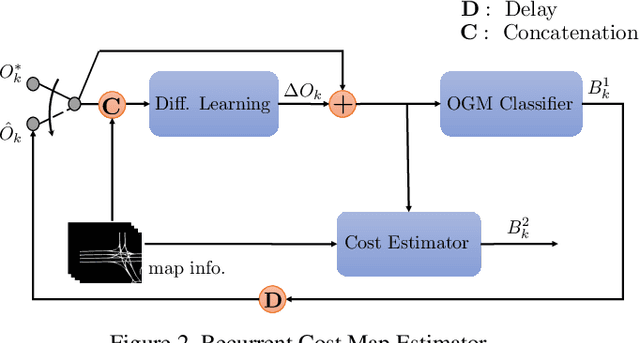
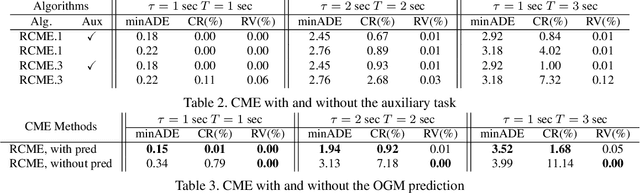
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.
Prediction by Anticipation: An Action-Conditional Prediction Method based on Interaction Learning
Dec 25, 2020

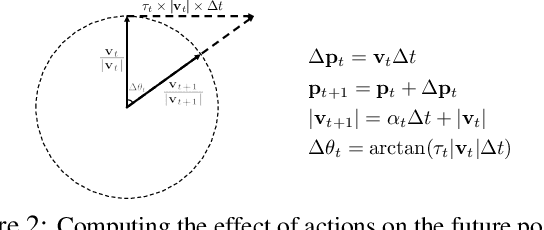

In autonomous driving (AD), accurately predicting changes in the environment can effectively improve safety and comfort. Due to complex interactions among traffic participants, however, it is very hard to achieve accurate prediction for a long horizon. To address this challenge, we propose prediction by anticipation, which views interaction in terms of a latent probabilistic generative process wherein some vehicles move partly in response to the anticipated motion of other vehicles. Under this view, consecutive data frames can be factorized into sequential samples from an action-conditional distribution that effectively generalizes to a wider range of actions and driving situations. Our proposed prediction model, variational Bayesian in nature, is trained to maximize the evidence lower bound (ELBO) of the log-likelihood of this conditional distribution. Evaluations of our approach with prominent AD datasets NGSIM I-80 and Argoverse show significant improvement over current state-of-the-art in both accuracy and generalization.