 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentFormer: Multi-Agent Transformer-Based Interaction Modeling and Trajectory Prediction
Paper and Code
Mar 03, 2022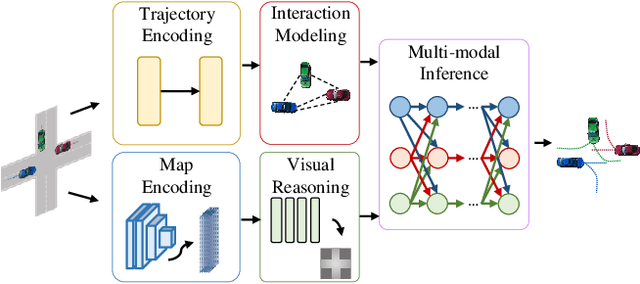
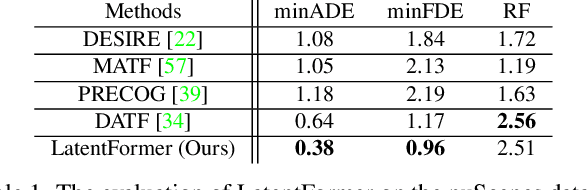
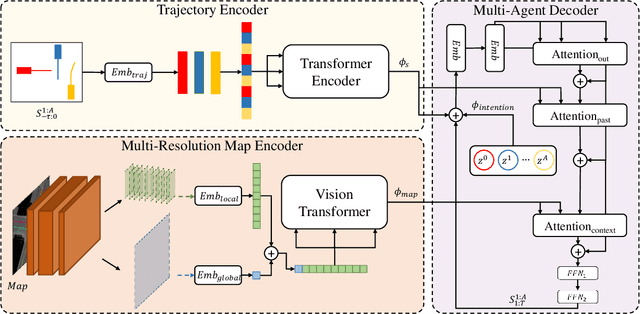

Multi-agent trajectory prediction is a fundamental problem in autonomous driving. The key challenges in prediction are accurately anticipating the behavior of surrounding agents and understanding the scene context. To address these problems, we propose LatentFormer, a transformer-based model for predicting future vehicle trajectories. The proposed method leverages a novel technique for modeling interactions among dynamic objects in the scene. Contrary to many existing approaches which model cross-agent interactions during the observation time, our method additionally exploits the future states of the agents. This is accomplished using a hierarchical attention mechanism where the evolving states of the agents autoregressively control the contributions of past trajectories and scene encodings in the final prediction. Furthermore, we propose a multi-resolution map encoding scheme that relies on a vision transformer module to effectively capture both local and global scene context to guide the generation of more admissible future trajectories. We evaluate the proposed method on the nuScenes benchmark dataset and show that our approach achieves state-of-the-art performance and improves upon trajectory metrics by up to 40%. We further investigate the contributions of various components of the proposed technique via extensive ablation studies.