 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentFormer: Multi-Agent Transformer-Based Interaction Modeling and Trajectory Prediction
Mar 03, 2022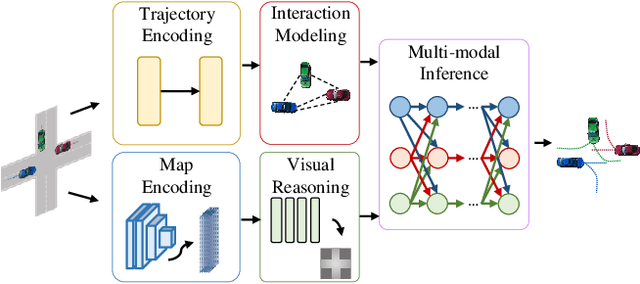
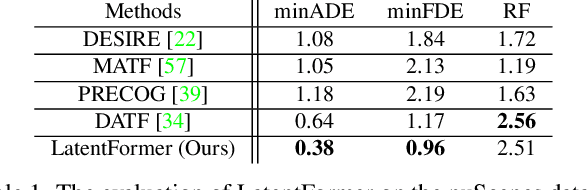
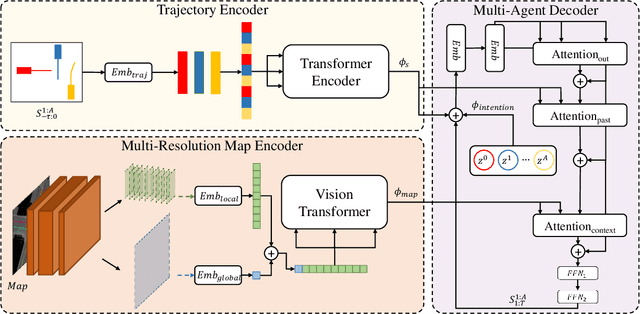

Multi-agent trajectory prediction is a fundamental problem in autonomous driving. The key challenges in prediction are accurately anticipating the behavior of surrounding agents and understanding the scene context. To address these problems, we propose LatentFormer, a transformer-based model for predicting future vehicle trajectories. The proposed method leverages a novel technique for modeling interactions among dynamic objects in the scene. Contrary to many existing approaches which model cross-agent interactions during the observation time, our method additionally exploits the future states of the agents. This is accomplished using a hierarchical attention mechanism where the evolving states of the agents autoregressively control the contributions of past trajectories and scene encodings in the final prediction. Furthermore, we propose a multi-resolution map encoding scheme that relies on a vision transformer module to effectively capture both local and global scene context to guide the generation of more admissible future trajectories. We evaluate the proposed method on the nuScenes benchmark dataset and show that our approach achieves state-of-the-art performance and improves upon trajectory metrics by up to 40%. We further investigate the contributions of various components of the proposed technique via extensive ablation studies.
Self-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Mar 01, 2021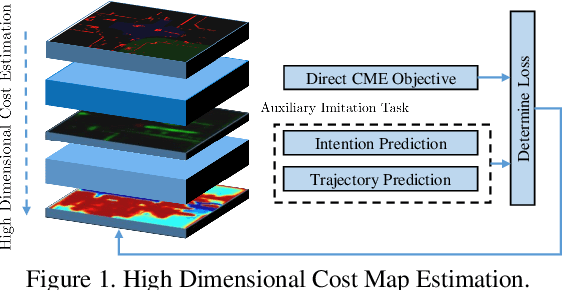
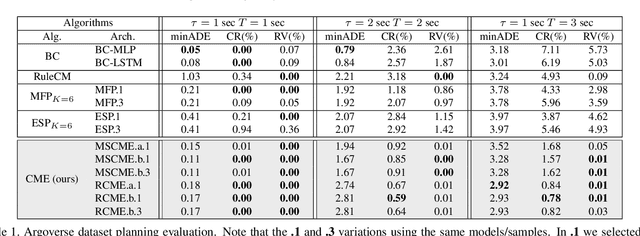
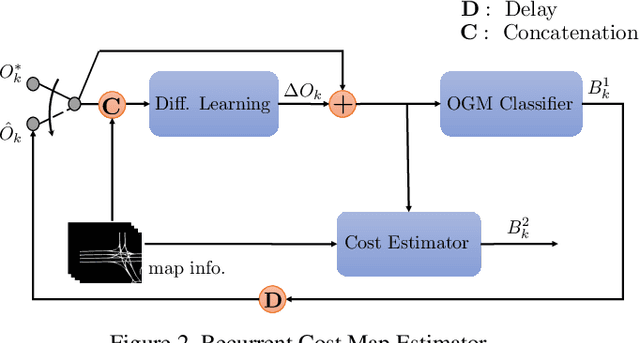
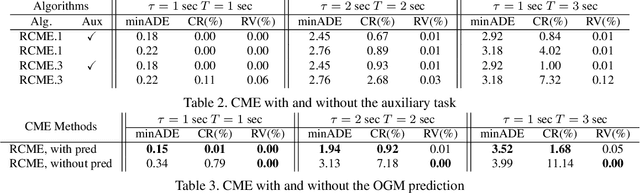
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.
Prediction by Anticipation: An Action-Conditional Prediction Method based on Interaction Learning
Dec 25, 2020

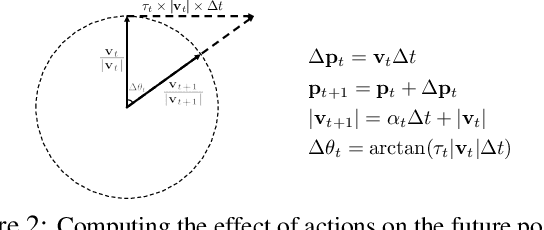

In autonomous driving (AD), accurately predicting changes in the environment can effectively improve safety and comfort. Due to complex interactions among traffic participants, however, it is very hard to achieve accurate prediction for a long horizon. To address this challenge, we propose prediction by anticipation, which views interaction in terms of a latent probabilistic generative process wherein some vehicles move partly in response to the anticipated motion of other vehicles. Under this view, consecutive data frames can be factorized into sequential samples from an action-conditional distribution that effectively generalizes to a wider range of actions and driving situations. Our proposed prediction model, variational Bayesian in nature, is trained to maximize the evidence lower bound (ELBO) of the log-likelihood of this conditional distribution. Evaluations of our approach with prominent AD datasets NGSIM I-80 and Argoverse show significant improvement over current state-of-the-art in both accuracy and generalization.
PePScenes: A Novel Dataset and Baseline for Pedestrian Action Prediction in 3D
Dec 14, 2020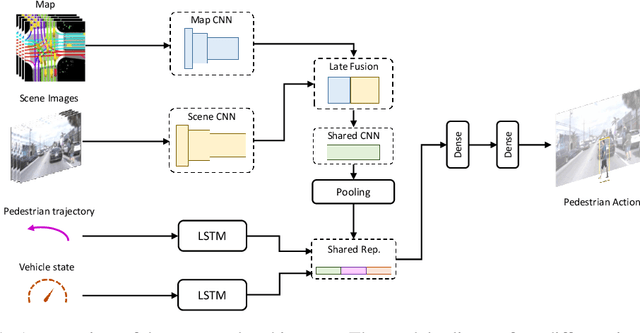
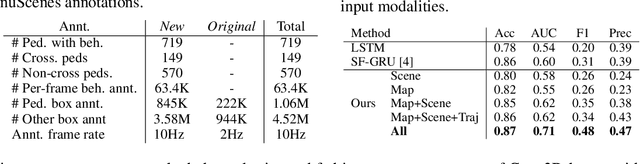
Predicting the behavior of road users, particularly pedestrians, is vital for safe motion planning in the context of autonomous driving systems. Traditionally, pedestrian behavior prediction has been realized in terms of forecasting future trajectories. However, recent evidence suggests that predicting higher-level actions, such as crossing the road, can help improve trajectory forecasting and planning tasks accordingly. There are a number of existing datasets that cater to the development of pedestrian action prediction algorithms, however, they lack certain characteristics, such as bird's eye view semantic map information, 3D locations of objects in the scene, etc., which are crucial in the autonomous driving context. To this end, we propose a new pedestrian action prediction dataset created by adding per-frame 2D/3D bounding box and behavioral annotations to the popular autonomous driving dataset, nuScenes. In addition, we propose a hybrid neural network architecture that incorporates various data modalities for predicting pedestrian crossing action. By evaluating our model on the newly proposed dataset, the contribution of different data modalities to the prediction task is revealed. The dataset is available at https://github.com/huawei-noah/PePScenes.
Pedestrian Behavior Prediction via Multitask Learning and Categorical Interaction Modeling
Dec 06, 2020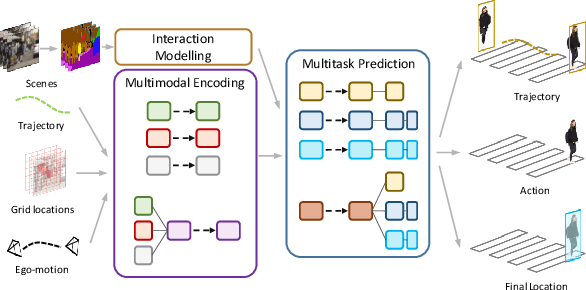
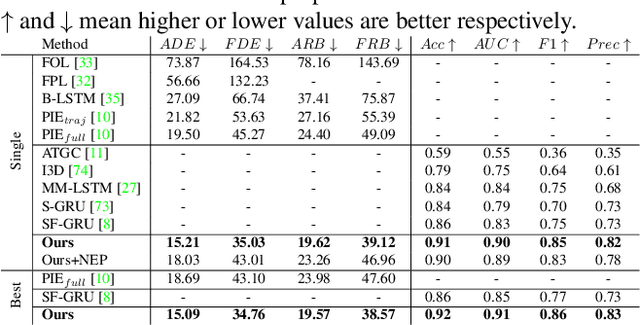
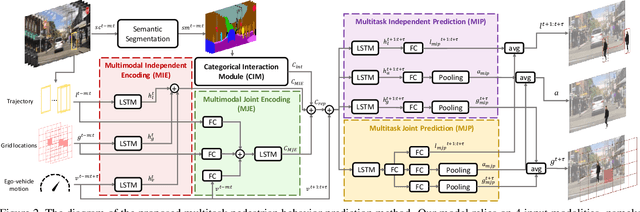
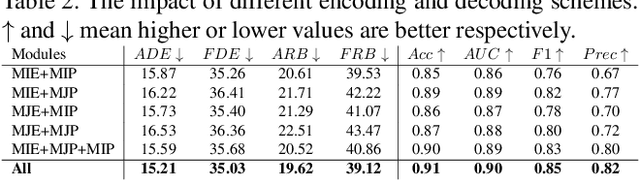
Pedestrian behavior prediction is one of the major challenges for intelligent driving systems. Pedestrians often exhibit complex behaviors influenced by various contextual elements. To address this problem, we propose a multitask learning framework that simultaneously predicts trajectories and actions of pedestrians by relying on multimodal data. Our method benefits from 1) a hybrid mechanism to encode different input modalities independently allowing them to develop their own representations, and jointly to produce a representation for all modalities using shared parameters; 2) a novel interaction modeling technique that relies on categorical semantic parsing of the scenes to capture interactions between target pedestrians and their surroundings; and 3) a dual prediction mechanism that uses both independent and shared decoding of multimodal representations. Using public pedestrian behavior benchmark datasets for driving, PIE and JAAD, we highlight the benefits of multitask learning for behavior prediction and show that our model achieves state-of-the-art performance and improves trajectory and action prediction by up to 22% and 6% respectively. We further investigate the contributions of the proposed processing and interaction modeling techniques via extensive ablation studies.
Graph-SIM: A Graph-based Spatiotemporal Interaction Modelling for Pedestrian Action Prediction
Dec 03, 2020
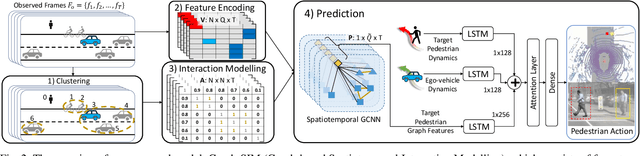
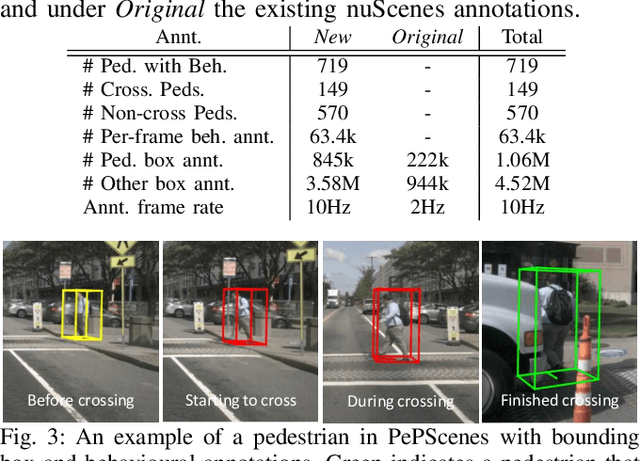
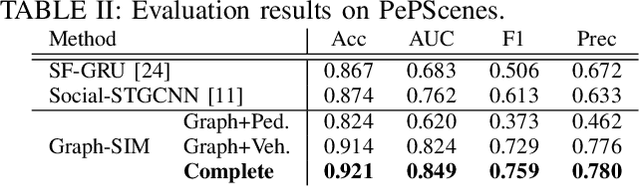
One of the most crucial yet challenging tasks for autonomous vehicles in urban environments is predicting the future behaviour of nearby pedestrians, especially at points of crossing. Predicting behaviour depends on many social and environmental factors, particularly interactions between road users. Capturing such interactions requires a global view of the scene and dynamics of the road users in three-dimensional space. This information, however, is missing from the current pedestrian behaviour benchmark datasets. Motivated by these challenges, we propose 1) a novel graph-based model for predicting pedestrian crossing action. Our method models pedestrians' interactions with nearby road users through clustering and relative importance weighting of interactions using features obtained from the bird's-eye-view. 2) We introduce a new dataset that provides 3D bounding box and pedestrian behavioural annotations for the existing nuScenes dataset. On the new data, our approach achieves state-of-the-art performance by improving on various metrics by more than 10% in comparison to existing methods. Upon publishing of this paper, our dataset will be made publicly available.
Multi-Modal Hybrid Architecture for Pedestrian Action Prediction
Nov 16, 2020
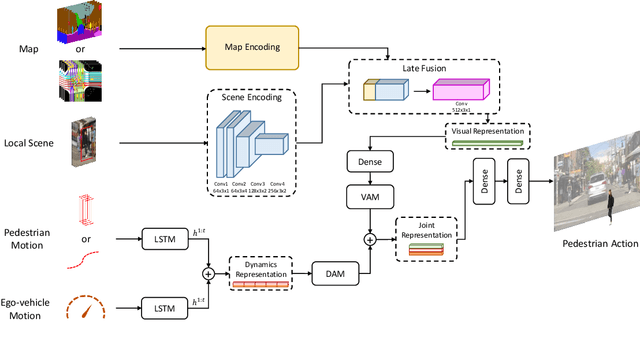


Pedestrian behavior prediction is one of the major challenges for intelligent driving systems in urban environments. Pedestrians often exhibit a wide range of behaviors and adequate interpretations of those depend on various sources of information such as pedestrian appearance, states of other road users, the environment layout, etc. To address this problem, we propose a novel multi-modal prediction algorithm that incorporates different sources of information captured from the environment to predict future crossing actions of pedestrians. The proposed model benefits from a hybrid learning architecture consisting of feedforward and recurrent networks for analyzing visual features of the environment and dynamics of the scene. Using the existing 2D pedestrian behavior benchmarks and a newly annotated 3D driving dataset, we show that our proposed model achieves state-of-the-art performance in pedestrian crossing prediction.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
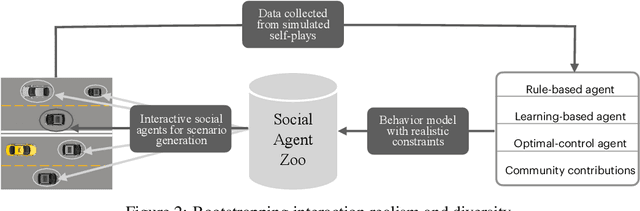
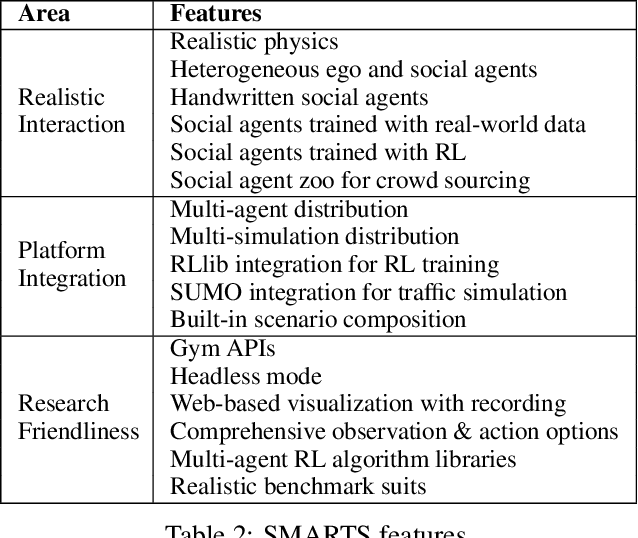
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.
Multi-Step Prediction of Occupancy Grid Maps with Recurrent Neural Networks
Jan 22, 2019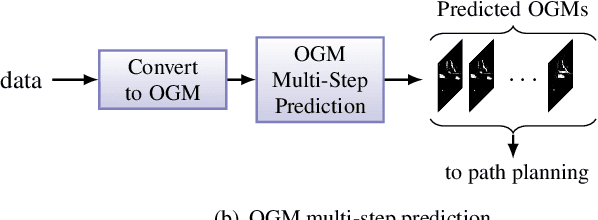
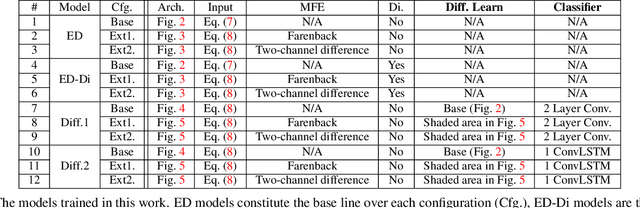
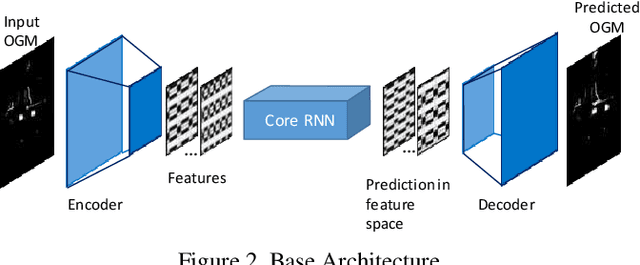

We investigate the multi-step prediction of the drivable space, represented by Occupancy Grid Maps (OGMs), for autonomous vehicles. Our motivation is that accurate multi-step prediction of the drivable space can efficiently improve path planning and navigation resulting in safe, comfortable and optimum paths in autonomous driving. We train a variety of Recurrent Neural Network (RNN) based architectures on the OGM sequences from the KITTI dataset. The results demonstrate significant improvement of the prediction accuracy using our proposed difference learning method, incorporating motion related features, over the state of the art. We remove the egomotion from the OGM sequences by transforming them into a common frame. Although in the transformed sequences the KITTI dataset is heavily biased toward static objects, by learning the difference between subsequent OGMs, our proposed method provides accurate prediction over both the static and moving objects.