 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuZO: Quantized Zeroth-Order Fine-Tuning for Large Language Models
Feb 17, 2025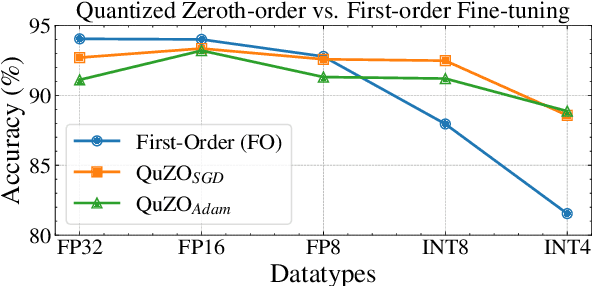
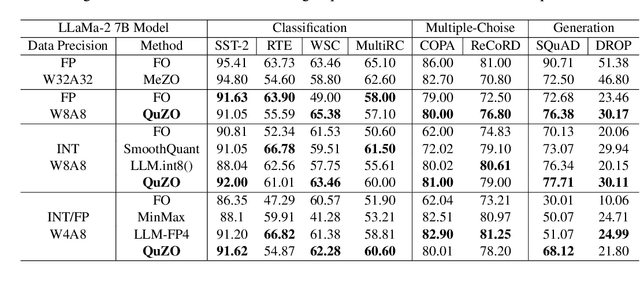

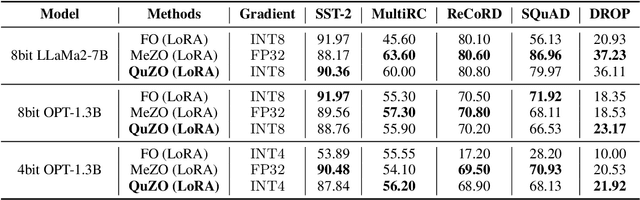
Language Models (LLMs) are often quantized to lower precision to reduce the memory cost and latency in inference. However, quantization often degrades model performance, thus fine-tuning is required for various down-stream tasks. Traditional fine-tuning methods such as stochastic gradient descent and Adam optimization require backpropagation, which are error-prone in the low-precision settings. To overcome these limitations, we propose the Quantized Zeroth-Order (QuZO) framework, specifically designed for fine-tuning LLMs through low-precision (e.g., 4- or 8-bit) forward passes. Our method can avoid the error-prone low-precision straight-through estimator, and utilizes optimized stochastic rounding to mitigate the increased bias. QuZO simplifies the training process, while achieving results comparable to first-order methods in ${\rm FP}8$ and superior accuracy in ${\rm INT}8$ and ${\rm INT}4$ training. Experiments demonstrate that low-bit training QuZO achieves performance comparable to MeZO optimization on GLUE, Multi-Choice, and Generation tasks, while reducing memory cost by $2.94 \times$ in LLaMA2-7B fine-tuning compared to quantized first-order methods.
CALICO: Conversational Agent Localization via Synthetic Data Generation
Dec 06, 2024



We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.
Self-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Mar 01, 2021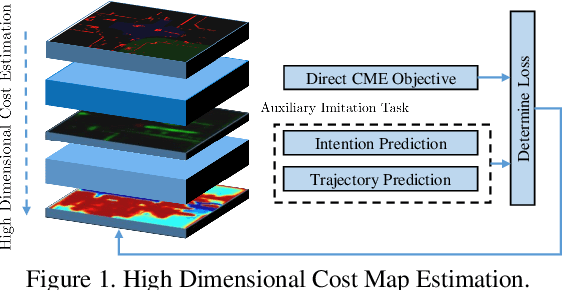
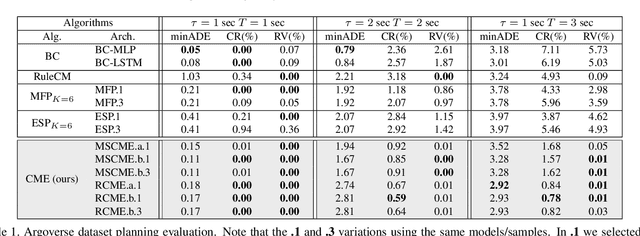
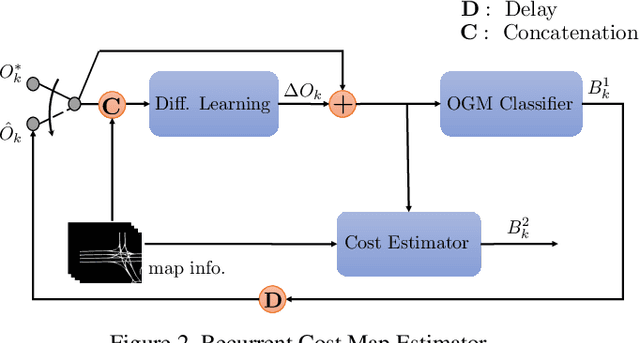
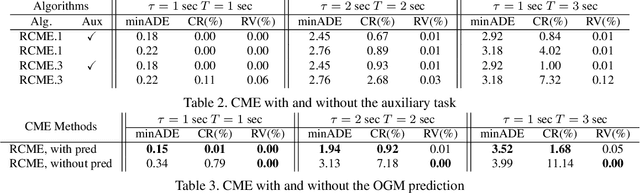
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.
Prediction by Anticipation: An Action-Conditional Prediction Method based on Interaction Learning
Dec 25, 2020

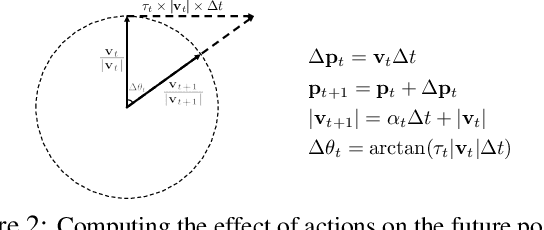

In autonomous driving (AD), accurately predicting changes in the environment can effectively improve safety and comfort. Due to complex interactions among traffic participants, however, it is very hard to achieve accurate prediction for a long horizon. To address this challenge, we propose prediction by anticipation, which views interaction in terms of a latent probabilistic generative process wherein some vehicles move partly in response to the anticipated motion of other vehicles. Under this view, consecutive data frames can be factorized into sequential samples from an action-conditional distribution that effectively generalizes to a wider range of actions and driving situations. Our proposed prediction model, variational Bayesian in nature, is trained to maximize the evidence lower bound (ELBO) of the log-likelihood of this conditional distribution. Evaluations of our approach with prominent AD datasets NGSIM I-80 and Argoverse show significant improvement over current state-of-the-art in both accuracy and generalization.
Deep Variational Sufficient Dimensionality Reduction
Dec 18, 2018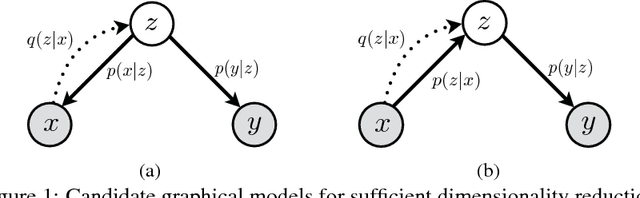



We consider the problem of sufficient dimensionality reduction (SDR), where the high-dimensional observation is transformed to a low-dimensional sub-space in which the information of the observations regarding the label variable is preserved. We propose DVSDR, a deep variational approach for sufficient dimensionality reduction. The deep structure in our model has a bottleneck that represent the low-dimensional embedding of the data. We explain the SDR problem using graphical models and use the framework of variational autoencoders to maximize the lower bound of the log-likelihood of the joint distribution of the observation and label. We show that such a maximization problem can be interpreted as solving the SDR problem. DVSDR can be easily adopted to semi-supervised learning setting. In our experiment we show that DVSDR performs competitively on classification tasks while being able to generate novel data samples.
Optimizing over a Restricted Policy Class in Markov Decision Processes
Feb 26, 2018
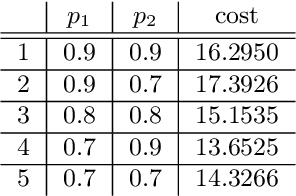
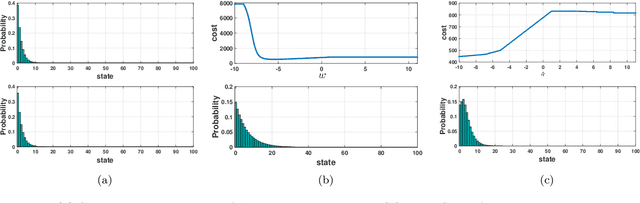
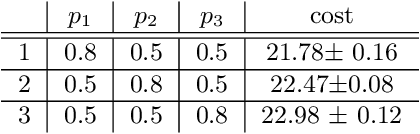
We address the problem of finding an optimal policy in a Markov decision process under a restricted policy class defined by the convex hull of a set of base policies. This problem is of great interest in applications in which a number of reasonably good (or safe) policies are already known and we are only interested in optimizing in their convex hull. We show that this problem is NP-hard to solve exactly as well as to approximate to arbitrary accuracy. However, under a condition that is akin to the occupancy measures of the base policies having large overlap, we show that there exists an efficient algorithm that finds a policy that is almost as good as the best convex combination of the base policies. The running time of the proposed algorithm is linear in the number of states and polynomial in the number of base policies. In practice, we demonstrate an efficient implementation for large state problems. Compared to traditional policy gradient methods, the proposed approach has the advantage that, apart from the computation of occupancy measures of some base policies, the iterative method need not interact with the environment during the optimization process. This is especially important in complex systems where estimating the value of a policy can be a time consuming process.
Robust Locally-Linear Controllable Embedding
Feb 21, 2018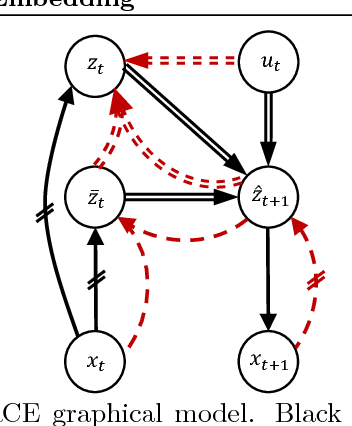
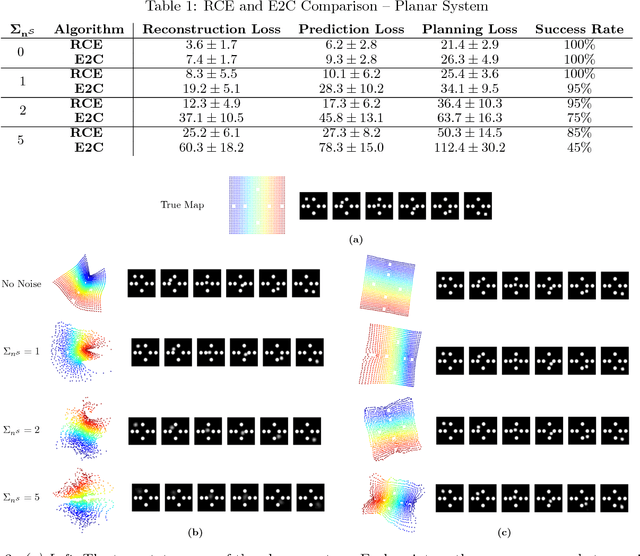
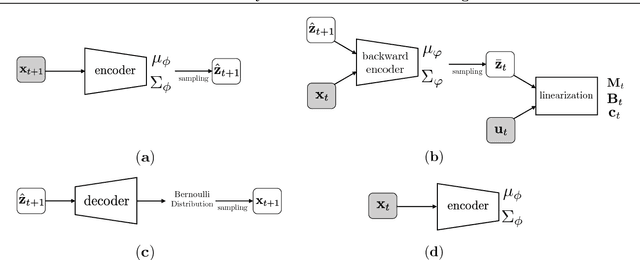
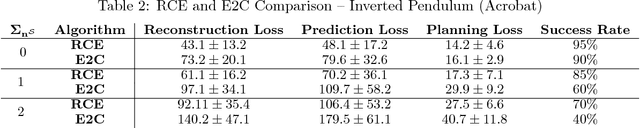
Embed-to-control (E2C) is a model for solving high-dimensional optimal control problems by combining variational auto-encoders with locally-optimal controllers. However, the E2C model suffers from two major drawbacks: 1) its objective function does not correspond to the likelihood of the data sequence and 2) the variational encoder used for embedding typically has large variational approximation error, especially when there is noise in the system dynamics. In this paper, we present a new model for learning robust locally-linear controllable embedding (RCE). Our model directly estimates the predictive conditional density of the future observation given the current one, while introducing the bottleneck between the current and future observations. Although the bottleneck provides a natural embedding candidate for control, our RCE model introduces additional specific structures in the generative graphical model so that the model dynamics can be robustly linearized. We also propose a principled variational approximation of the embedding posterior that takes the future observation into account, and thus, makes the variational approximation more robust against the noise. Experimental results show that RCE outperforms the E2C model, and does so significantly when the underlying dynamics is noisy.
Disentangling Dynamics and Content for Control and Planning
Nov 24, 2017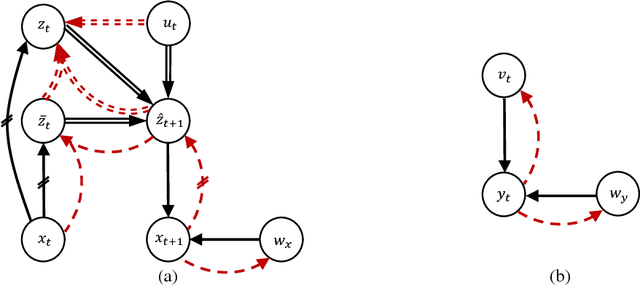
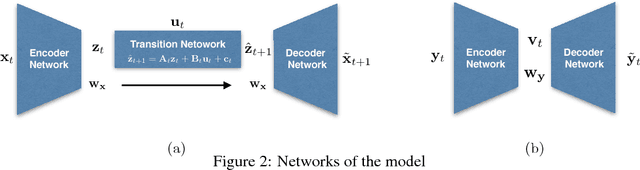
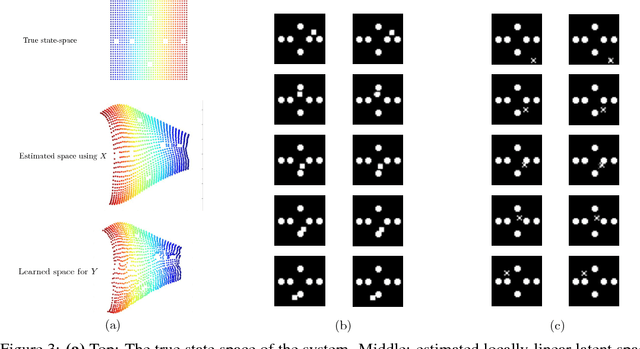
In this paper, We study the problem of learning a controllable representation for high-dimensional observations of dynamical systems. Specifically, we consider a situation where there are multiple sets of observations of dynamical systems with identical underlying dynamics. Only one of these sets has information about the effect of actions on the observation and the rest are just some random observations of the system. Our goal is to utilize the information in that one set and find a representation for the other sets that can be used for planning and ling-term prediction.
JADE: Joint Autoencoders for Dis-Entanglement
Nov 24, 2017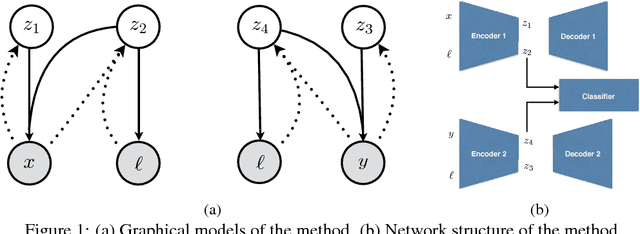


The problem of feature disentanglement has been explored in the literature, for the purpose of image and video processing and text analysis. State-of-the-art methods for disentangling feature representations rely on the presence of many labeled samples. In this work, we present a novel method for disentangling factors of variation in data-scarce regimes. Specifically, we explore the application of feature disentangling for the problem of supervised classification in a setting where few labeled samples exist, and there are no unlabeled samples for use in unsupervised training. Instead, a similar datasets exists which shares at least one direction of variation with the sample-constrained datasets. We train our model end-to-end using the framework of variational autoencoders and are able to experimentally demonstrate that using an auxiliary dataset with similar variation factors contribute positively to classification performance, yielding competitive results with the state-of-the-art in unsupervised learning.
Fast Spectral Clustering Using Autoencoders and Landmarks
Apr 07, 2017

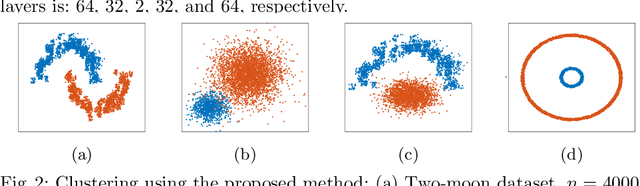
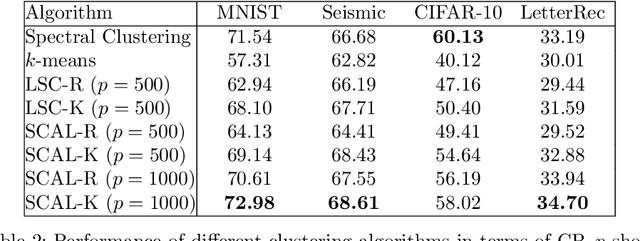
In this paper, we introduce an algorithm for performing spectral clustering efficiently. Spectral clustering is a powerful clustering algorithm that suffers from high computational complexity, due to eigen decomposition. In this work, we first build the adjacency matrix of the corresponding graph of the dataset. To build this matrix, we only consider a limited number of points, called landmarks, and compute the similarity of all data points with the landmarks. Then, we present a definition of the Laplacian matrix of the graph that enable us to perform eigen decomposition efficiently, using a deep autoencoder. The overall complexity of the algorithm for eigen decomposition is $O(np)$, where $n$ is the number of data points and $p$ is the number of landmarks. At last, we evaluate the performance of the algorithm in different experiments.