 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuZO: Quantized Zeroth-Order Fine-Tuning for Large Language Models
Paper and Code
Feb 17, 2025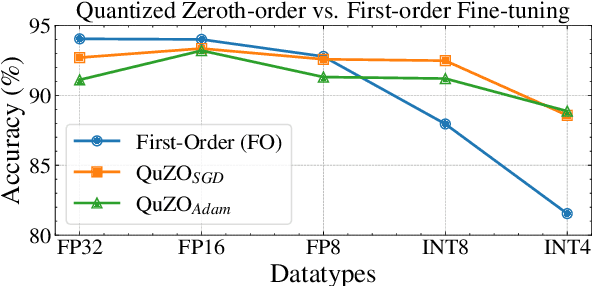
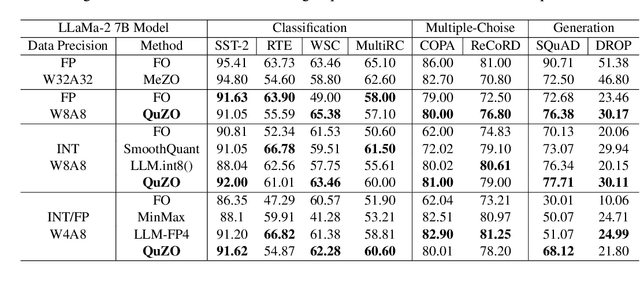

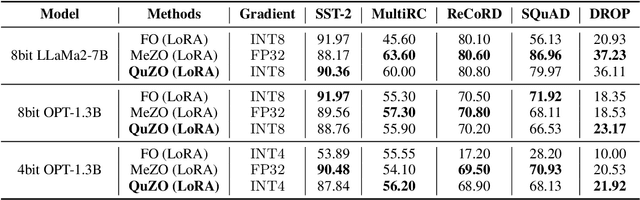
Language Models (LLMs) are often quantized to lower precision to reduce the memory cost and latency in inference. However, quantization often degrades model performance, thus fine-tuning is required for various down-stream tasks. Traditional fine-tuning methods such as stochastic gradient descent and Adam optimization require backpropagation, which are error-prone in the low-precision settings. To overcome these limitations, we propose the Quantized Zeroth-Order (QuZO) framework, specifically designed for fine-tuning LLMs through low-precision (e.g., 4- or 8-bit) forward passes. Our method can avoid the error-prone low-precision straight-through estimator, and utilizes optimized stochastic rounding to mitigate the increased bias. QuZO simplifies the training process, while achieving results comparable to first-order methods in ${\rm FP}8$ and superior accuracy in ${\rm INT}8$ and ${\rm INT}4$ training. Experiments demonstrate that low-bit training QuZO achieves performance comparable to MeZO optimization on GLUE, Multi-Choice, and Generation tasks, while reducing memory cost by $2.94 \times$ in LLaMA2-7B fine-tuning compared to quantized first-order methods.