 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
Tensor-Compressed and Fully-Quantized Training of Neural PDE Solvers
Dec 10, 2025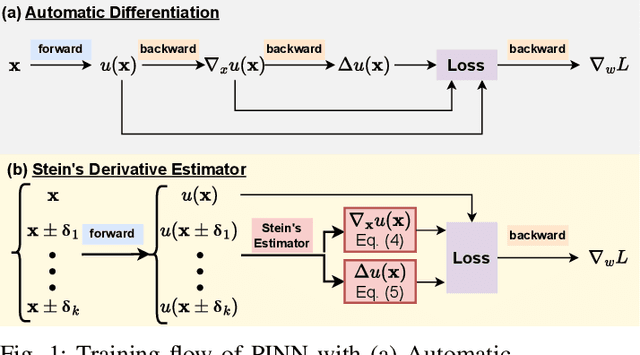
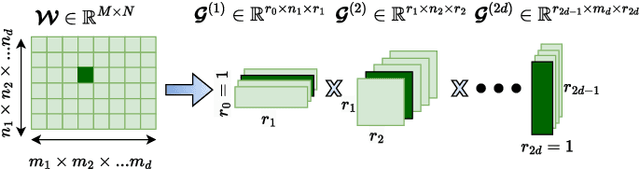
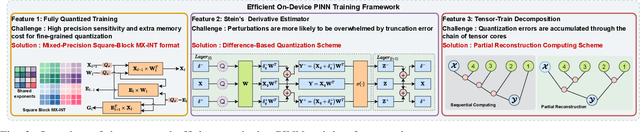
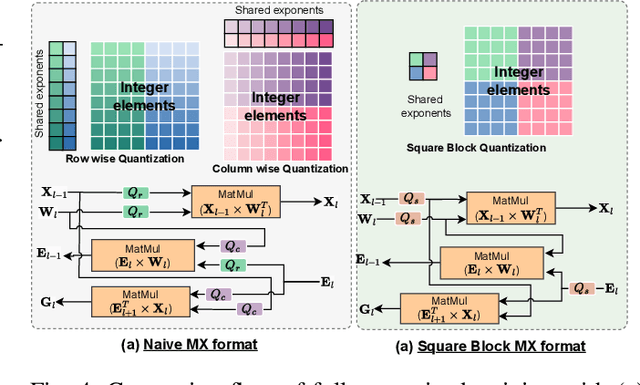
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.
SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025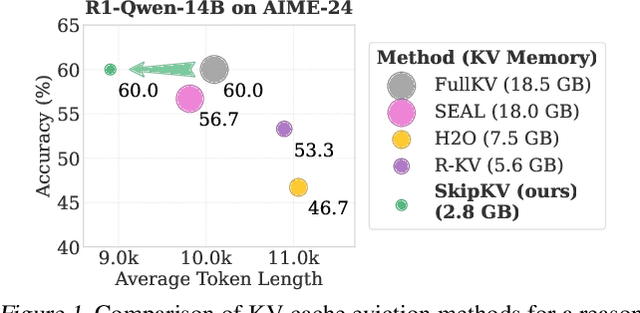
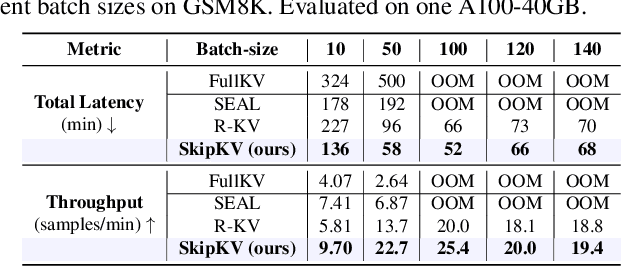
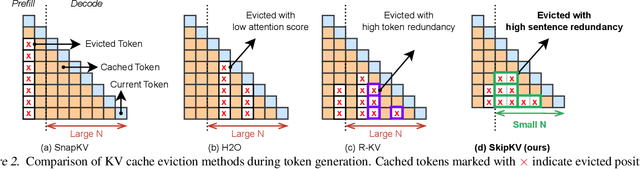
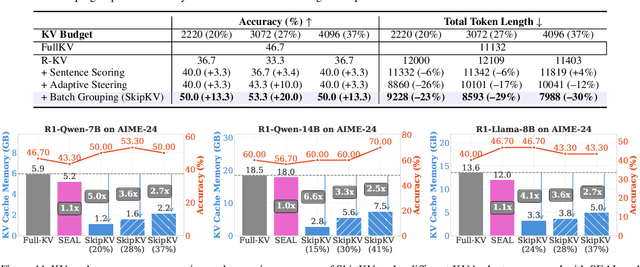
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
Scalable Back-Propagation-Free Training of Optical Physics-Informed Neural Networks
Feb 17, 2025Physics-informed neural networks (PINNs) have shown promise in solving partial differential equations (PDEs), with growing interest in their energy-efficient, real-time training on edge devices. Photonic computing offers a potential solution to achieve this goal because of its ultra-high operation speed. However, the lack of photonic memory and the large device sizes prevent training real-size PINNs on photonic chips. This paper proposes a completely back-propagation-free (BP-free) and highly salable framework for training real-size PINNs on silicon photonic platforms. Our approach involves three key innovations: (1) a sparse-grid Stein derivative estimator to avoid the BP in the loss evaluation of a PINN, (2) a dimension-reduced zeroth-order optimization via tensor-train decomposition to achieve better scalability and convergence in BP-free training, and (3) a scalable on-chip photonic PINN training accelerator design using photonic tensor cores. We validate our numerical methods on both low- and high-dimensional PDE benchmarks. Through circuit simulation based on real device parameters, we further demonstrate the significant performance benefit (e.g., real-time training, huge chip area reduction) of our photonic accelerator.
QuZO: Quantized Zeroth-Order Fine-Tuning for Large Language Models
Feb 17, 2025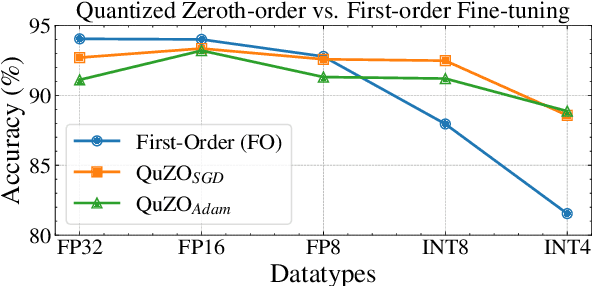
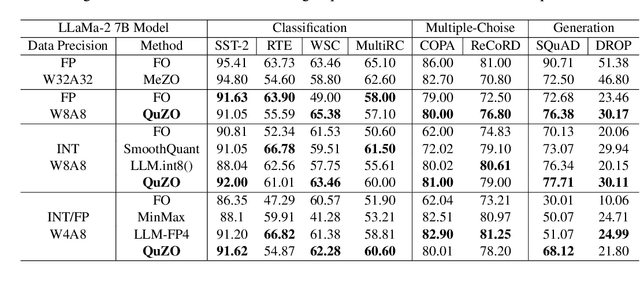

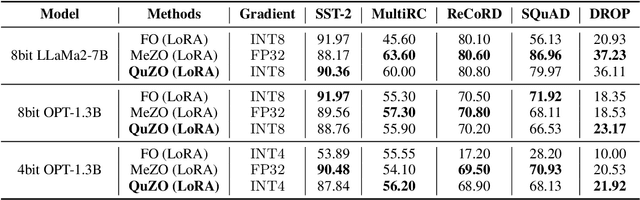
Language Models (LLMs) are often quantized to lower precision to reduce the memory cost and latency in inference. However, quantization often degrades model performance, thus fine-tuning is required for various down-stream tasks. Traditional fine-tuning methods such as stochastic gradient descent and Adam optimization require backpropagation, which are error-prone in the low-precision settings. To overcome these limitations, we propose the Quantized Zeroth-Order (QuZO) framework, specifically designed for fine-tuning LLMs through low-precision (e.g., 4- or 8-bit) forward passes. Our method can avoid the error-prone low-precision straight-through estimator, and utilizes optimized stochastic rounding to mitigate the increased bias. QuZO simplifies the training process, while achieving results comparable to first-order methods in ${\rm FP}8$ and superior accuracy in ${\rm INT}8$ and ${\rm INT}4$ training. Experiments demonstrate that low-bit training QuZO achieves performance comparable to MeZO optimization on GLUE, Multi-Choice, and Generation tasks, while reducing memory cost by $2.94 \times$ in LLaMA2-7B fine-tuning compared to quantized first-order methods.
Experimental Demonstration of an Optical Neural PDE Solver via On-Chip PINN Training
Jan 01, 2025


Partial differential equation (PDE) is an important math tool in science and engineering. This paper experimentally demonstrates an optical neural PDE solver by leveraging the back-propagation-free on-photonic-chip training of physics-informed neural networks.
Poor Man's Training on MCUs: A Memory-Efficient Quantized Back-Propagation-Free Approach
Nov 07, 2024



Back propagation (BP) is the default solution for gradient computation in neural network training. However, implementing BP-based training on various edge devices such as FPGA, microcontrollers (MCUs), and analog computing platforms face multiple major challenges, such as the lack of hardware resources, long time-to-market, and dramatic errors in a low-precision setting. This paper presents a simple BP-free training scheme on an MCU, which makes edge training hardware design as easy as inference hardware design. We adopt a quantized zeroth-order method to estimate the gradients of quantized model parameters, which can overcome the error of a straight-through estimator in a low-precision BP scheme. We further employ a few dimension reduction methods (e.g., node perturbation, sparse training) to improve the convergence of zeroth-order training. Experiment results show that our BP-free training achieves comparable performance as BP-based training on adapting a pre-trained image classifier to various corrupted data on resource-constrained edge devices (e.g., an MCU with 1024-KB SRAM for dense full-model training, or an MCU with 256-KB SRAM for sparse training). This method is most suitable for application scenarios where memory cost and time-to-market are the major concerns, but longer latency can be tolerated.
Separable Operator Networks
Jul 15, 2024



Operator learning has become a powerful tool in machine learning for modeling complex physical systems. Although Deep Operator Networks (DeepONet) show promise, they require extensive data acquisition. Physics-informed DeepONets (PI-DeepONet) mitigate data scarcity but suffer from inefficient training processes. We introduce Separable Operator Networks (SepONet), a novel framework that significantly enhances the efficiency of physics-informed operator learning. SepONet uses independent trunk networks to learn basis functions separately for different coordinate axes, enabling faster and more memory-efficient training via forward-mode automatic differentiation. We provide theoretical guarantees for SepONet using the universal approximation theorem and validate its performance through comprehensive benchmarking against PI-DeepONet. Our results demonstrate that for the 1D time-dependent advection equation, when targeting a mean relative $\ell_{2}$ error of less than 6% on 100 unseen variable coefficients, SepONet provides up to $112 \times$ training speed-up and $82 \times$ GPU memory usage reduction compared to PI-DeepONet. Similar computational advantages are observed across various partial differential equations, with SepONet's efficiency gains scaling favorably as problem complexity increases. This work paves the way for extreme-scale learning of continuous mappings between infinite-dimensional function spaces.
Real-Time FJ/MAC PDE Solvers via Tensorized, Back-Propagation-Free Optical PINN Training
Jan 04, 2024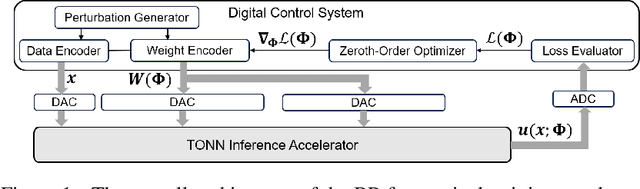

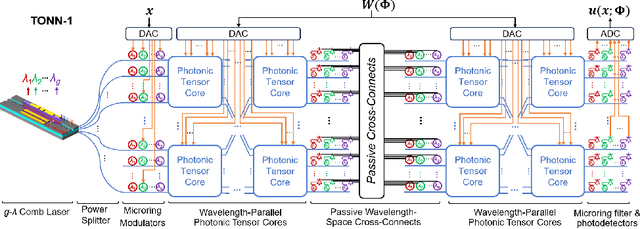

Solving partial differential equations (PDEs) numerically often requires huge computing time, energy cost, and hardware resources in practical applications. This has limited their applications in many scenarios (e.g., autonomous systems, supersonic flows) that have a limited energy budget and require near real-time response. Leveraging optical computing, this paper develops an on-chip training framework for physics-informed neural networks (PINNs), aiming to solve high-dimensional PDEs with fJ/MAC photonic power consumption and ultra-low latency. Despite the ultra-high speed of optical neural networks, training a PINN on an optical chip is hard due to (1) the large size of photonic devices, and (2) the lack of scalable optical memory devices to store the intermediate results of back-propagation (BP). To enable realistic optical PINN training, this paper presents a scalable method to avoid the BP process. We also employ a tensor-compressed approach to improve the convergence and scalability of our optical PINN training. This training framework is designed with tensorized optical neural networks (TONN) for scalable inference acceleration and MZI phase-domain tuning for \textit{in-situ} optimization. Our simulation results of a 20-dim HJB PDE show that our photonic accelerator can reduce the number of MZIs by a factor of $1.17\times 10^3$, with only $1.36$ J and $1.15$ s to solve this equation. This is the first real-size optical PINN training framework that can be applied to solve high-dimensional PDEs.
Tensor-Compressed Back-Propagation-Free Training for (Physics-Informed) Neural Networks
Aug 18, 2023Backward propagation (BP) is widely used to compute the gradients in neural network training. However, it is hard to implement BP on edge devices due to the lack of hardware and software resources to support automatic differentiation. This has tremendously increased the design complexity and time-to-market of on-device training accelerators. This paper presents a completely BP-free framework that only requires forward propagation to train realistic neural networks. Our technical contributions are three-fold. Firstly, we present a tensor-compressed variance reduction approach to greatly improve the scalability of zeroth-order (ZO) optimization, making it feasible to handle a network size that is beyond the capability of previous ZO approaches. Secondly, we present a hybrid gradient evaluation approach to improve the efficiency of ZO training. Finally, we extend our BP-free training framework to physics-informed neural networks (PINNs) by proposing a sparse-grid approach to estimate the derivatives in the loss function without using BP. Our BP-free training only loses little accuracy on the MNIST dataset compared with standard first-order training. We also demonstrate successful results in training a PINN for solving a 20-dim Hamiltonian-Jacobi-Bellman PDE. This memory-efficient and BP-free approach may serve as a foundation for the near-future on-device training on many resource-constraint platforms (e.g., FPGA, ASIC, micro-controllers, and photonic chips).