 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
Apr 04, 2025Thermal analysis is crucial in three-dimensional integrated circuit (3D-IC) design due to increased power density and complex heat dissipation paths. Although operator learning frameworks such as DeepOHeat have demonstrated promising preliminary results in accelerating thermal simulation, they face critical limitations in prediction capability for multi-scale thermal patterns, training efficiency, and trustworthiness of results during design optimization. This paper presents DeepOHeat-v1, an enhanced physics-informed operator learning framework that addresses these challenges through three key innovations. First, we integrate Kolmogorov-Arnold Networks with learnable activation functions as trunk networks, enabling an adaptive representation of multi-scale thermal patterns. This approach achieves a $1.25\times$ and $6.29\times$ reduction in error in two representative test cases. Second, we introduce a separable training method that decomposes the basis function along the coordinate axes, achieving $62\times$ training speedup and $31\times$ GPU memory reduction in our baseline case, and enabling thermal analysis at resolutions previously infeasible due to GPU memory constraints. Third, we propose a confidence score to evaluate the trustworthiness of the predicted results, and further develop a hybrid optimization workflow that combines operator learning with finite difference (FD) using Generalized Minimal Residual (GMRES) method for incremental solution refinement, enabling efficient and trustworthy thermal optimization. Experimental results demonstrate that DeepOHeat-v1 achieves accuracy comparable to optimization using high-fidelity finite difference solvers, while speeding up the entire optimization process by $70.6\times$ in our test cases, effectively minimizing the peak temperature through optimal placement of heat-generating components.
Scalable Back-Propagation-Free Training of Optical Physics-Informed Neural Networks
Feb 17, 2025Physics-informed neural networks (PINNs) have shown promise in solving partial differential equations (PDEs), with growing interest in their energy-efficient, real-time training on edge devices. Photonic computing offers a potential solution to achieve this goal because of its ultra-high operation speed. However, the lack of photonic memory and the large device sizes prevent training real-size PINNs on photonic chips. This paper proposes a completely back-propagation-free (BP-free) and highly salable framework for training real-size PINNs on silicon photonic platforms. Our approach involves three key innovations: (1) a sparse-grid Stein derivative estimator to avoid the BP in the loss evaluation of a PINN, (2) a dimension-reduced zeroth-order optimization via tensor-train decomposition to achieve better scalability and convergence in BP-free training, and (3) a scalable on-chip photonic PINN training accelerator design using photonic tensor cores. We validate our numerical methods on both low- and high-dimensional PDE benchmarks. Through circuit simulation based on real device parameters, we further demonstrate the significant performance benefit (e.g., real-time training, huge chip area reduction) of our photonic accelerator.
Experimental Demonstration of an Optical Neural PDE Solver via On-Chip PINN Training
Jan 01, 2025


Partial differential equation (PDE) is an important math tool in science and engineering. This paper experimentally demonstrates an optical neural PDE solver by leveraging the back-propagation-free on-photonic-chip training of physics-informed neural networks.
Separable Operator Networks
Jul 15, 2024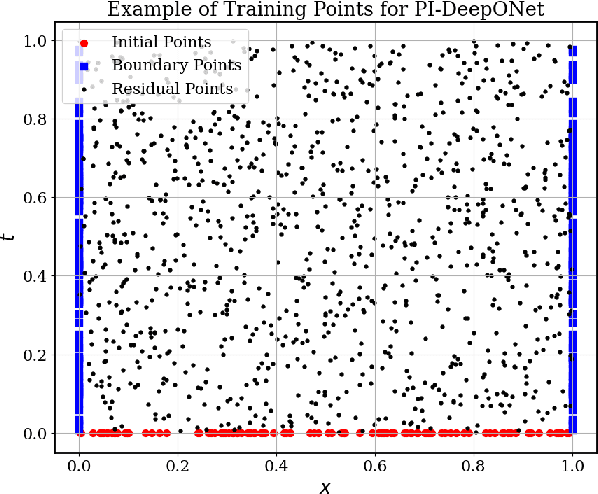



Operator learning has become a powerful tool in machine learning for modeling complex physical systems. Although Deep Operator Networks (DeepONet) show promise, they require extensive data acquisition. Physics-informed DeepONets (PI-DeepONet) mitigate data scarcity but suffer from inefficient training processes. We introduce Separable Operator Networks (SepONet), a novel framework that significantly enhances the efficiency of physics-informed operator learning. SepONet uses independent trunk networks to learn basis functions separately for different coordinate axes, enabling faster and more memory-efficient training via forward-mode automatic differentiation. We provide theoretical guarantees for SepONet using the universal approximation theorem and validate its performance through comprehensive benchmarking against PI-DeepONet. Our results demonstrate that for the 1D time-dependent advection equation, when targeting a mean relative $\ell_{2}$ error of less than 6% on 100 unseen variable coefficients, SepONet provides up to $112 \times$ training speed-up and $82 \times$ GPU memory usage reduction compared to PI-DeepONet. Similar computational advantages are observed across various partial differential equations, with SepONet's efficiency gains scaling favorably as problem complexity increases. This work paves the way for extreme-scale learning of continuous mappings between infinite-dimensional function spaces.
Real-Time FJ/MAC PDE Solvers via Tensorized, Back-Propagation-Free Optical PINN Training
Jan 04, 2024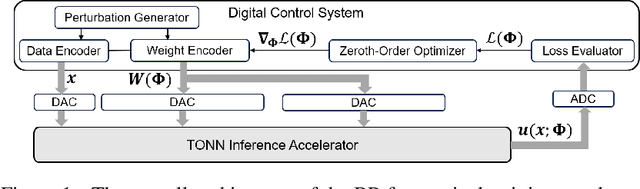

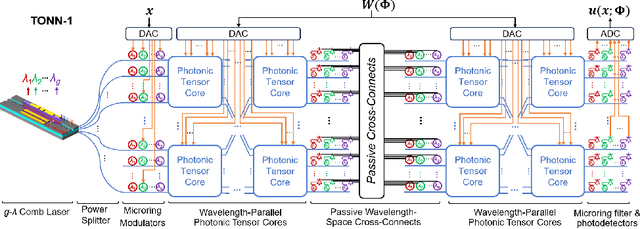

Solving partial differential equations (PDEs) numerically often requires huge computing time, energy cost, and hardware resources in practical applications. This has limited their applications in many scenarios (e.g., autonomous systems, supersonic flows) that have a limited energy budget and require near real-time response. Leveraging optical computing, this paper develops an on-chip training framework for physics-informed neural networks (PINNs), aiming to solve high-dimensional PDEs with fJ/MAC photonic power consumption and ultra-low latency. Despite the ultra-high speed of optical neural networks, training a PINN on an optical chip is hard due to (1) the large size of photonic devices, and (2) the lack of scalable optical memory devices to store the intermediate results of back-propagation (BP). To enable realistic optical PINN training, this paper presents a scalable method to avoid the BP process. We also employ a tensor-compressed approach to improve the convergence and scalability of our optical PINN training. This training framework is designed with tensorized optical neural networks (TONN) for scalable inference acceleration and MZI phase-domain tuning for \textit{in-situ} optimization. Our simulation results of a 20-dim HJB PDE show that our photonic accelerator can reduce the number of MZIs by a factor of $1.17\times 10^3$, with only $1.36$ J and $1.15$ s to solve this equation. This is the first real-size optical PINN training framework that can be applied to solve high-dimensional PDEs.
Tensor-Compressed Back-Propagation-Free Training for (Physics-Informed) Neural Networks
Aug 18, 2023Backward propagation (BP) is widely used to compute the gradients in neural network training. However, it is hard to implement BP on edge devices due to the lack of hardware and software resources to support automatic differentiation. This has tremendously increased the design complexity and time-to-market of on-device training accelerators. This paper presents a completely BP-free framework that only requires forward propagation to train realistic neural networks. Our technical contributions are three-fold. Firstly, we present a tensor-compressed variance reduction approach to greatly improve the scalability of zeroth-order (ZO) optimization, making it feasible to handle a network size that is beyond the capability of previous ZO approaches. Secondly, we present a hybrid gradient evaluation approach to improve the efficiency of ZO training. Finally, we extend our BP-free training framework to physics-informed neural networks (PINNs) by proposing a sparse-grid approach to estimate the derivatives in the loss function without using BP. Our BP-free training only loses little accuracy on the MNIST dataset compared with standard first-order training. We also demonstrate successful results in training a PINN for solving a 20-dim Hamiltonian-Jacobi-Bellman PDE. This memory-efficient and BP-free approach may serve as a foundation for the near-future on-device training on many resource-constraint platforms (e.g., FPGA, ASIC, micro-controllers, and photonic chips).
DeepOHeat: Operator Learning-based Ultra-fast Thermal Simulation in 3D-IC Design
Feb 25, 2023



Thermal issue is a major concern in 3D integrated circuit (IC) design. Thermal optimization of 3D IC often requires massive expensive PDE simulations. Neural network-based thermal prediction models can perform real-time prediction for many unseen new designs. However, existing works either solve 2D temperature fields only or do not generalize well to new designs with unseen design configurations (e.g., heat sources and boundary conditions). In this paper, for the first time, we propose DeepOHeat, a physics-aware operator learning framework to predict the temperature field of a family of heat equations with multiple parametric or non-parametric design configurations. This framework learns a functional map from the function space of multiple key PDE configurations (e.g., boundary conditions, power maps, heat transfer coefficients) to the function space of the corresponding solution (i.e., temperature fields), enabling fast thermal analysis and optimization by changing key design configurations (rather than just some parameters). We test DeepOHeat on some industrial design cases and compare it against Celsius 3D from Cadence Design Systems. Our results show that, for the unseen testing cases, a well-trained DeepOHeat can produce accurate results with $1000\times$ to $300000\times$ speedup.
PIFON-EPT: MR-Based Electrical Property Tomography Using Physics-Informed Fourier Networks
Feb 24, 2023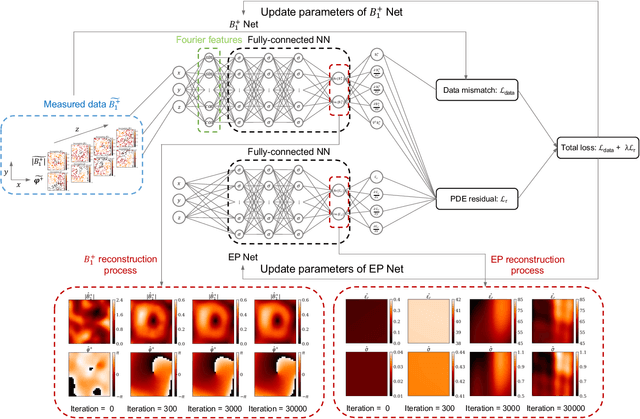
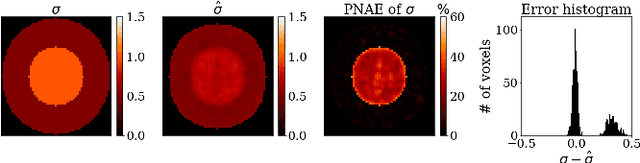
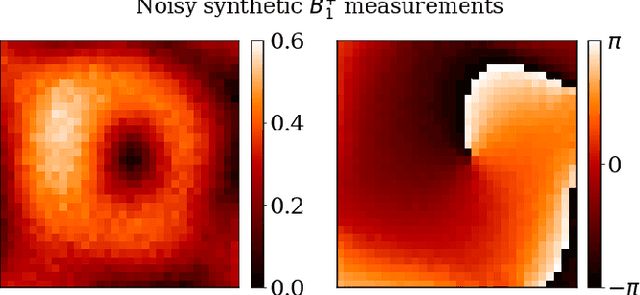
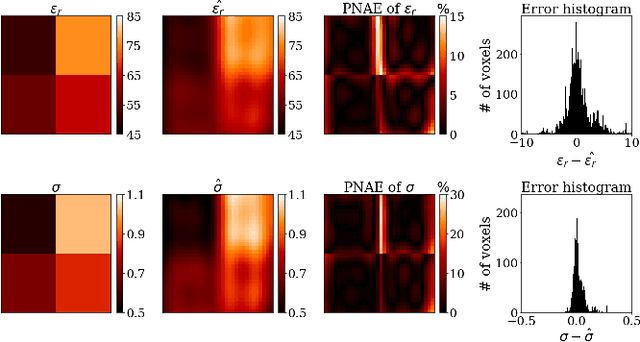
\textit{Objective:} In this paper, we introduce Physics-Informed Fourier Networks (PIFONs) for Electrical Properties (EP) Tomography (EPT). Our novel deep learning-based method is capable of learning EPs globally by solving an inverse scattering problem based on noisy and/or incomplete magnetic resonance (MR) measurements. \textit{Methods:} We use two separate fully-connected neural networks, namely $B_1^{+}$ Net and EP Net, to learn the $B_1^{+}$ field and EPs at any location. A random Fourier features mapping is embedded into $B_1^{+}$ Net, which allows it to learn the $B_1^{+}$ field more efficiently. These two neural networks are trained jointly by minimizing the combination of a physics-informed loss and a data mismatch loss via gradient descent. \textit{Results:} We showed that PIFON-EPT could provide physically consistent reconstructions of EPs and transmit field in the whole domain of interest even when half of the noisy MR measurements of the entire volume was missing. The average error was $2.49\%$, $4.09\%$ and $0.32\%$ for the relative permittivity, conductivity and $B_{1}^{+}$, respectively, over the entire volume of the phantom. In experiments that admitted a zero assumption of $B_z$, PIFON-EPT could yield accurate EP predictions near the interface between regions of different EP values without requiring any boundary conditions. \textit{Conclusion:} This work demonstrated the feasibility of PIFON-EPT, suggesting it could be an accurate and effective method for electrical properties estimation. \textit{Significance:} PIFON-EPT can efficiently de-noise MR measurements, which shows the potential to improve other MR-based EPT techniques. Furthermore, it is the first time that MR-based EPT methods can reconstruct the EPs and $B_{1}^{+}$ field simultaneously from incomplete simulated noisy MR measurements.
MR-Based Electrical Property Reconstruction Using Physics-Informed Neural Networks
Oct 23, 2022Electrical properties (EP), namely permittivity and electric conductivity, dictate the interactions between electromagnetic waves and biological tissue. EP can be potential biomarkers for pathology characterization, such as cancer, and improve therapeutic modalities, such radiofrequency hyperthermia and ablation. MR-based electrical properties tomography (MR-EPT) uses MR measurements to reconstruct the EP maps. Using the homogeneous Helmholtz equation, EP can be directly computed through calculations of second order spatial derivatives of the measured magnetic transmit or receive fields $(B_{1}^{+}, B_{1}^{-})$. However, the numerical approximation of derivatives leads to noise amplifications in the measurements and thus erroneous reconstructions. Recently, a noise-robust supervised learning-based method (DL-EPT) was introduced for EP reconstruction. However, the pattern-matching nature of such network does not allow it to generalize for new samples since the network's training is done on a limited number of simulated data. In this work, we leverage recent developments on physics-informed deep learning to solve the Helmholtz equation for the EP reconstruction. We develop deep neural network (NN) algorithms that are constrained by the Helmholtz equation to effectively de-noise the $B_{1}^{+}$ measurements and reconstruct EP directly at an arbitrarily high spatial resolution without requiring any known $B_{1}^{+}$ and EP distribution pairs.
TT-PINN: A Tensor-Compressed Neural PDE Solver for Edge Computing
Jul 04, 2022
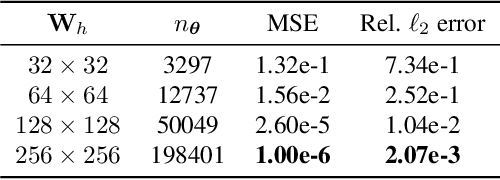


Physics-informed neural networks (PINNs) have been increasingly employed due to their capability of modeling complex physics systems. To achieve better expressiveness, increasingly larger network sizes are required in many problems. This has caused challenges when we need to train PINNs on edge devices with limited memory, computing and energy resources. To enable training PINNs on edge devices, this paper proposes an end-to-end compressed PINN based on Tensor-Train decomposition. In solving a Helmholtz equation, our proposed model significantly outperforms the original PINNs with few parameters and achieves satisfactory prediction with up to 15$\times$ overall parameter reduction.