 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-Free Diffusion Transformers for Low-Complexity MIMO Channel Estimation
Feb 02, 2026Diffusion model-based channel estimators have shown impressive performance but suffer from high computational complexity because they rely on iterative reverse sampling. This paper proposes a sampling-free diffusion transformer (DiT) for low-complexity MIMO channel estimation, termed SF-DiT-CE. Exploiting angular-domain sparsity of MIMO channels, we train a lightweight DiT to directly predict the clean channels from their perturbed observations and noise levels. At inference, the least square (LS) estimate and estimation noise condition the DiT to recover the channel in a single forward pass, eliminating iterative sampling. Numerical results demonstrate that our method achieves superior estimation accuracy and robustness with significantly lower complexity than state-of-the-art baselines.
Coordinate-conditioned Deconvolution for Scalable Spatially Varying High-Throughput Imaging
Feb 01, 2026Wide-field fluorescence microscopy with compact optics often suffers from spatially varying blur due to field-dependent aberrations, vignetting, and sensor truncation, while finite sensor sampling imposes an inherent trade-off between field of view (FOV) and resolution. Computational Miniaturized Mesoscope (CM2) alleviate the sampling limit by multiplexing multiple sub-views onto a single sensor, but introduce view crosstalk and a highly ill-conditioned inverse problem compounded by spatially variant point spread functions (PSFs). Prior learning-based spatially varying (SV) reconstruction methods typically rely on global SV operators with fixed input sizes, resulting in memory and training costs that scale poorly with image dimensions. We propose SV-CoDe (Spatially Varying Coordinate-conditioned Deconvolution), a scalable deep learning framework that achieves uniform, high-resolution reconstruction across a 6.5 mm FOV. Unlike conventional methods, SV-CoDe employs coordinate-conditioned convolutions to locally adapt reconstruction kernels; this enables patch-based training that decouples parameter count from FOV size. SV-CoDe achieves the best image quality in both simulated and experimental measurements while requiring 10x less model size and 10x less training data than prior baselines. Trained purely on physics-based simulations, the network robustly generalizes to bead phantoms, weakly scattering brain slices, and freely moving C. elegans. SV-CoDe offers a scalable, physics-aware solution for correcting SV blur in compact optical systems and is readily extendable to a broad range of biomedical imaging applications.
Latent Sculpting for Zero-Shot Generalization: A Manifold Learning Approach to Out-of-Distribution Anomaly Detection
Dec 19, 2025A fundamental limitation of supervised deep learning in high-dimensional tabular domains is "Generalization Collapse": models learn precise decision boundaries for known distributions but fail catastrophically when facing Out-of-Distribution (OOD) data. We hypothesize that this failure stems from the lack of topological constraints in the latent space, resulting in diffuse manifolds where novel anomalies remain statistically indistinguishable from benign data. To address this, we propose Latent Sculpting, a hierarchical two-stage representation learning framework. Stage 1 utilizes a hybrid 1D-CNN and Transformer Encoder trained with a novel Dual-Centroid Compactness Loss (DCCL) to actively "sculpt" benign traffic into a low-entropy, hyperspherical cluster. Unlike standard contrastive losses that rely on triplet mining, DCCL optimizes global cluster centroids to enforce absolute manifold density. Stage 2 conditions a Masked Autoregressive Flow (MAF) on this pre-structured manifold to learn an exact density estimate. We evaluate this methodology on the rigorous CIC-IDS-2017 benchmark, treating it as a proxy for complex, non-stationary data streams. Empirical results demonstrate that explicit manifold sculpting is a prerequisite for robust zero-shot generalization. While supervised baselines suffered catastrophic performance collapse on unseen distribution shifts (F1 approx 0.30) and the strongest unsupervised baseline achieved only 0.76, our framework achieved an F1-Score of 0.87 on strictly zero-shot anomalies. Notably, we report an 88.89% detection rate on "Infiltration" scenarios--a complex distributional shift where state-of-the-art supervised models achieved 0.00% accuracy. These findings suggest that decoupling structure learning from density estimation provides a scalable path toward generalized anomaly detection.
Scalable Back-Propagation-Free Training of Optical Physics-Informed Neural Networks
Feb 17, 2025Physics-informed neural networks (PINNs) have shown promise in solving partial differential equations (PDEs), with growing interest in their energy-efficient, real-time training on edge devices. Photonic computing offers a potential solution to achieve this goal because of its ultra-high operation speed. However, the lack of photonic memory and the large device sizes prevent training real-size PINNs on photonic chips. This paper proposes a completely back-propagation-free (BP-free) and highly salable framework for training real-size PINNs on silicon photonic platforms. Our approach involves three key innovations: (1) a sparse-grid Stein derivative estimator to avoid the BP in the loss evaluation of a PINN, (2) a dimension-reduced zeroth-order optimization via tensor-train decomposition to achieve better scalability and convergence in BP-free training, and (3) a scalable on-chip photonic PINN training accelerator design using photonic tensor cores. We validate our numerical methods on both low- and high-dimensional PDE benchmarks. Through circuit simulation based on real device parameters, we further demonstrate the significant performance benefit (e.g., real-time training, huge chip area reduction) of our photonic accelerator.
CyberMentor: AI Powered Learning Tool Platform to Address Diverse Student Needs in Cybersecurity Education
Jan 16, 2025Many non-traditional students in cybersecurity programs often lack access to advice from peers, family members and professors, which can hinder their educational experiences. Additionally, these students may not fully benefit from various LLM-powered AI assistants due to issues like content relevance, locality of advice, minimum expertise, and timing. This paper addresses these challenges by introducing an application designed to provide comprehensive support by answering questions related to knowledge, skills, and career preparation advice tailored to the needs of these students. We developed a learning tool platform, CyberMentor, to address the diverse needs and pain points of students majoring in cybersecurity. Powered by agentic workflow and Generative Large Language Models (LLMs), the platform leverages Retrieval-Augmented Generation (RAG) for accurate and contextually relevant information retrieval to achieve accessibility and personalization. We demonstrated its value in addressing knowledge requirements for cybersecurity education and for career marketability, in tackling skill requirements for analytical and programming assignments, and in delivering real time on demand learning support. Using three use scenarios, we showcased CyberMentor in facilitating knowledge acquisition and career preparation and providing seamless skill-based guidance and support. We also employed the LangChain prompt-based evaluation methodology to evaluate the platform's impact, confirming its strong performance in helpfulness, correctness, and completeness. These results underscore the system's ability to support students in developing practical cybersecurity skills while improving equity and sustainability within higher education. Furthermore, CyberMentor's open-source design allows for adaptation across other disciplines, fostering educational innovation and broadening its potential impact.
Enhancing Computer Programming Education with LLMs: A Study on Effective Prompt Engineering for Python Code Generation
Jul 07, 2024



Large language models (LLMs) and prompt engineering hold significant potential for advancing computer programming education through personalized instruction. This paper explores this potential by investigating three critical research questions: the systematic categorization of prompt engineering strategies tailored to diverse educational needs, the empowerment of LLMs to solve complex problems beyond their inherent capabilities, and the establishment of a robust framework for evaluating and implementing these strategies. Our methodology involves categorizing programming questions based on educational requirements, applying various prompt engineering strategies, and assessing the effectiveness of LLM-generated responses. Experiments with GPT-4, GPT-4o, Llama3-8b, and Mixtral-8x7b models on datasets such as LeetCode and USACO reveal that GPT-4o consistently outperforms others, particularly with the "multi-step" prompt strategy. The results show that tailored prompt strategies significantly enhance LLM performance, with specific strategies recommended for foundational learning, competition preparation, and advanced problem-solving. This study underscores the crucial role of prompt engineering in maximizing the educational benefits of LLMs. By systematically categorizing and testing these strategies, we provide a comprehensive framework for both educators and students to optimize LLM-based learning experiences. Future research should focus on refining these strategies and addressing current LLM limitations to further enhance educational outcomes in computer programming instruction.
Real-Time FJ/MAC PDE Solvers via Tensorized, Back-Propagation-Free Optical PINN Training
Jan 04, 2024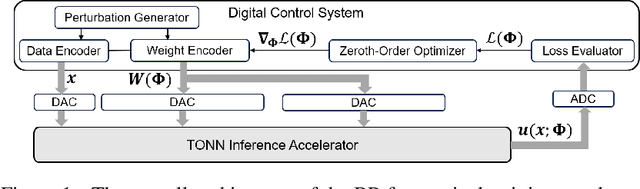

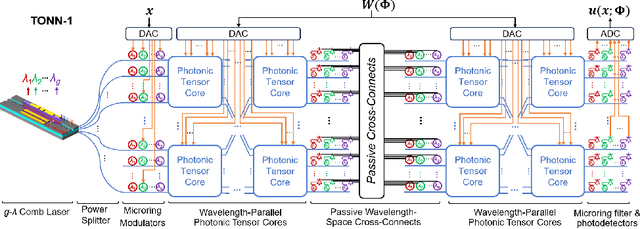

Solving partial differential equations (PDEs) numerically often requires huge computing time, energy cost, and hardware resources in practical applications. This has limited their applications in many scenarios (e.g., autonomous systems, supersonic flows) that have a limited energy budget and require near real-time response. Leveraging optical computing, this paper develops an on-chip training framework for physics-informed neural networks (PINNs), aiming to solve high-dimensional PDEs with fJ/MAC photonic power consumption and ultra-low latency. Despite the ultra-high speed of optical neural networks, training a PINN on an optical chip is hard due to (1) the large size of photonic devices, and (2) the lack of scalable optical memory devices to store the intermediate results of back-propagation (BP). To enable realistic optical PINN training, this paper presents a scalable method to avoid the BP process. We also employ a tensor-compressed approach to improve the convergence and scalability of our optical PINN training. This training framework is designed with tensorized optical neural networks (TONN) for scalable inference acceleration and MZI phase-domain tuning for \textit{in-situ} optimization. Our simulation results of a 20-dim HJB PDE show that our photonic accelerator can reduce the number of MZIs by a factor of $1.17\times 10^3$, with only $1.36$ J and $1.15$ s to solve this equation. This is the first real-size optical PINN training framework that can be applied to solve high-dimensional PDEs.
Tensor-Compressed Back-Propagation-Free Training for (Physics-Informed) Neural Networks
Aug 18, 2023Backward propagation (BP) is widely used to compute the gradients in neural network training. However, it is hard to implement BP on edge devices due to the lack of hardware and software resources to support automatic differentiation. This has tremendously increased the design complexity and time-to-market of on-device training accelerators. This paper presents a completely BP-free framework that only requires forward propagation to train realistic neural networks. Our technical contributions are three-fold. Firstly, we present a tensor-compressed variance reduction approach to greatly improve the scalability of zeroth-order (ZO) optimization, making it feasible to handle a network size that is beyond the capability of previous ZO approaches. Secondly, we present a hybrid gradient evaluation approach to improve the efficiency of ZO training. Finally, we extend our BP-free training framework to physics-informed neural networks (PINNs) by proposing a sparse-grid approach to estimate the derivatives in the loss function without using BP. Our BP-free training only loses little accuracy on the MNIST dataset compared with standard first-order training. We also demonstrate successful results in training a PINN for solving a 20-dim Hamiltonian-Jacobi-Bellman PDE. This memory-efficient and BP-free approach may serve as a foundation for the near-future on-device training on many resource-constraint platforms (e.g., FPGA, ASIC, micro-controllers, and photonic chips).
Knowledge-aided Federated Learning for Energy-limited Wireless Networks
Sep 25, 2022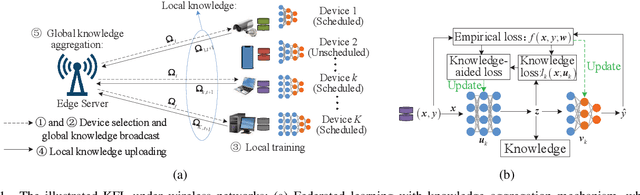
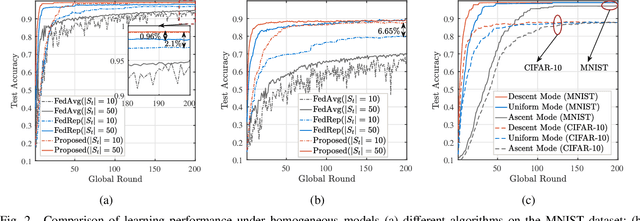
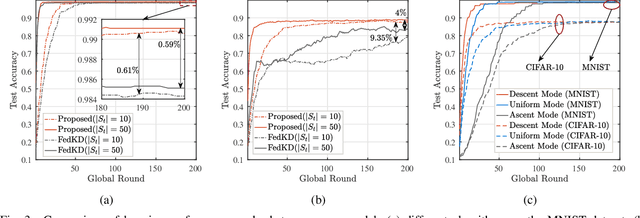
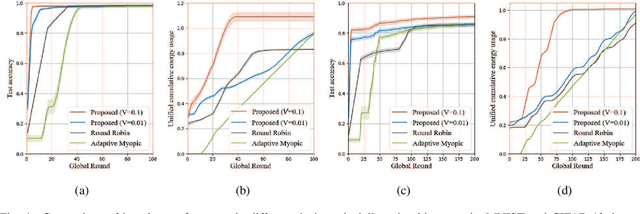
The conventional model aggregation-based federated learning (FL) approaches require all local models to have the same architecture and fail to support practical scenarios with heterogeneous local models. Moreover, the frequent model exchange is costly for resource-limited wireless networks since modern deep neural networks usually have over-million parameters. To tackle these challenges, we first propose a novel knowledge-aided FL (KFL) framework, which aggregates light high-level data features, namely knowledge, in the per-round learning process. This framework allows devices to design their machine learning models independently, and the KFL also reduces the communication overhead in the training process. We then theoretically analyze the convergence bound of the proposed framework under a non-convex loss function setting, revealing that large data volumes should be scheduled in the early rounds if the total data volumes during the entire learning course are fixed. Inspired by this, we define a new objective function, i.e., the weighted scheduled data sample volume, to transform the inexplicit global loss minimization problem into a tractable one for device scheduling, bandwidth allocation and power control. To deal with the unknown time-varying wireless channels, we transform the problem into a deterministic problem with the assistance of the Lyapunov optimization framework. Then, we also develop an efficient online device scheduling algorithm to achieve an energy-learning trade-off in the learning process. Experimental results on two typical datasets (i.e., MNIST and CIFAR-10) under highly heterogeneous local data distribution show that the proposed KFL is capable of reducing over 99% communication overhead while achieving better learning performance than the conventional model aggregation-based algorithms.
Dynamic Task Software Caching-assisted Computation Offloading for Multi-Access Edge Computing
Aug 15, 2022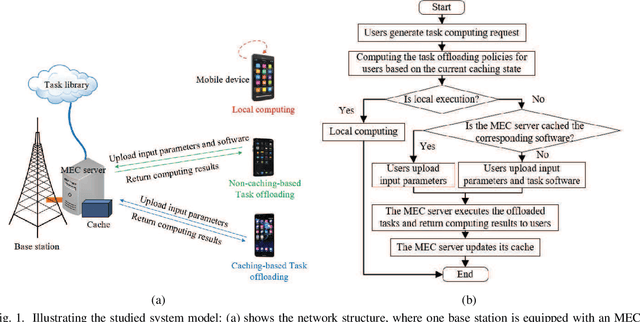
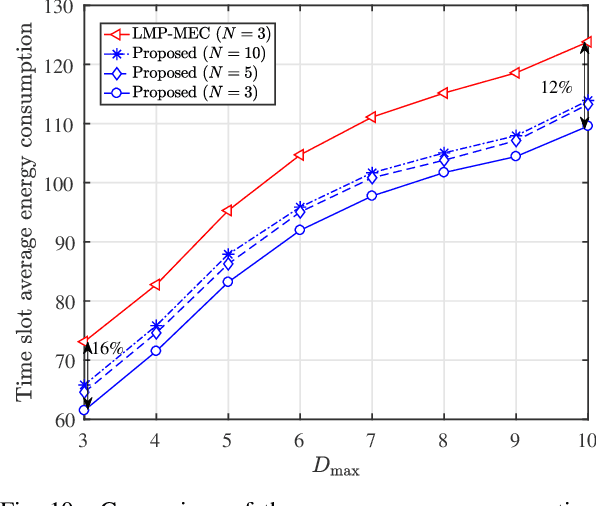
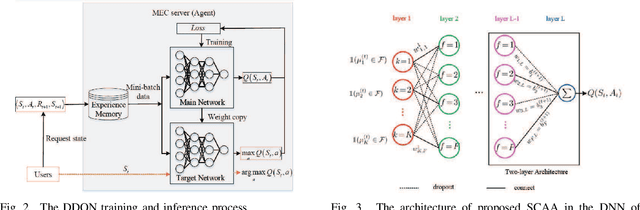

In multi-access edge computing (MEC), most existing task software caching works focus on statically caching data at the network edge, which may hardly preserve high reusability due to the time-varying user requests in practice. To this end, this work considers dynamic task software caching at the MEC server to assist users' task execution. Specifically, we formulate a joint task software caching update (TSCU) and computation offloading (COMO) problem to minimize users' energy consumption while guaranteeing delay constraints, where the limited cache size and computation capability of the MEC server, as well as the time-varying task demand of users are investigated. This problem is proved to be non-deterministic polynomial-time hard, so we transform it into two sub-problems according to their temporal correlations, i.e., the real-time COMO problem and the Markov decision process-based TSCU problem. We first model the COMO problem as a multi-user game and propose a decentralized algorithm to address its Nash equilibrium solution. We then propose a double deep Q-network (DDQN)-based method to solve the TSCU policy. To reduce the computation complexity and convergence time, we provide a new design for the deep neural network (DNN) in DDQN, named state coding and action aggregation (SCAA). In SCAA-DNN, we introduce a dropout mechanism in the input layer to code users' activity states. Additionally, at the output layer, we devise a two-layer architecture to dynamically aggregate caching actions, which is able to solve the huge state-action space problem. Simulation results show that the proposed solution outperforms existing schemes, saving over 12% energy, and converges with fewer training episodes.