 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuon$^2$: Boosting Muon via Adaptive Second-Moment Preconditioning
Apr 11, 2026Muon has emerged as a promising optimizer for large-scale foundation model pre-training by exploiting the matrix structure of neural network updates through iterative orthogonalization. However, its practical efficiency is limited by the need for multiple Newton--Schulz (NS) iterations per optimization step, which introduces non-trivial computation and communication overhead. We propose Muon$^2$, an extension of Muon that applies Adam-style adaptive second-moment preconditioning before orthogonalization. Our key insight is that the core challenge of polar approximation in Muon lies in the ill-conditioned momentum matrix, of which the spectrum is substantially improved by Muon$^2$, leading to faster convergence toward a practically sufficient orthogonalization. We further characterize the practical orthogonalization quality via directional alignment, under which Muon$^2$ demonstrates dramatic improvement over Muon at each polar step. Across GPT and LLaMA pre-training experiments from 60M to 1.3B parameters, Muon$^2$ consistently outperforms Muon and recent Muon variants while reducing NS iterations by 40\%. We further introduce Muon$^2$-F, a memory-efficient factorized variant that preserves most of the gains of Muon$^2$ with negligible memory overhead.
Muon+: Towards Better Muon via One Additional Normalization Step
Feb 26, 2026The Muon optimizer has demonstrated promising performance in pre-training large language models through gradient (or momentum) orthogonalization. In this work, we propose a simple yet effective enhancement to Muon, namely Muon+, which introduces an additional normalization step after orthogonalization. We demonstrate the effectiveness of Muon+ through extensive pre-training experiments across a wide range of model scales and architectures. Our evaluation includes GPT-style models ranging from 130M to 774M parameters and LLaMA-style models ranging from 60M to 1B parameters. We comprehensively evaluate the effectiveness of Muon+ in the compute-optimal training regime and further extend the token-to-parameter (T2P) ratio to an industrial level of $\approx 200$. Experimental results show that Muon+ provides a consistent boost on training and validation perplexity over Muon. We provide our code here: https://github.com/K1seki221/MuonPlus.
SWE-AGI: Benchmarking Specification-Driven Software Construction with MoonBit in the Era of Autonomous Agents
Feb 11, 2026Although large language models (LLMs) have demonstrated impressive coding capabilities, their ability to autonomously build production-scale software from explicit specifications remains an open question. We introduce SWE-AGI, an open-source benchmark for evaluating end-to-end, specification-driven construction of software systems written in MoonBit. SWE-AGI tasks require LLM-based agents to implement parsers, interpreters, binary decoders, and SAT solvers strictly from authoritative standards and RFCs under a fixed API scaffold. Each task involves implementing 1,000-10,000 lines of core logic, corresponding to weeks or months of engineering effort for an experienced human developer. By leveraging the nascent MoonBit ecosystem, SWE-AGI minimizes data leakage, forcing agents to rely on long-horizon architectural reasoning rather than code retrieval. Across frontier models, gpt-5.3-codex achieves the best overall performance (solving 19/22 tasks, 86.4%), outperforming claude-opus-4.6 (15/22, 68.2%), and kimi-2.5 exhibits the strongest performance among open-source models. Performance degrades sharply with increasing task difficulty, particularly on hard, specification-intensive systems. Behavioral analysis further reveals that as codebases scale, code reading, rather than writing, becomes the dominant bottleneck in AI-assisted development. Overall, while specification-driven autonomous software engineering is increasingly viable, substantial challenges remain before it can reliably support production-scale development.
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
BOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
Dec 13, 2025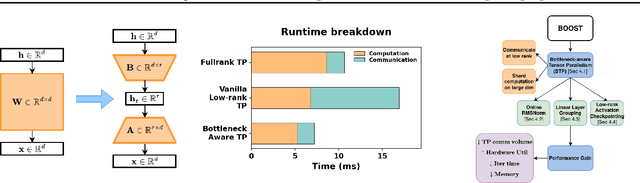

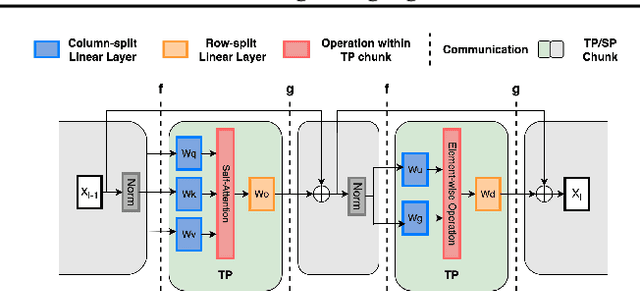
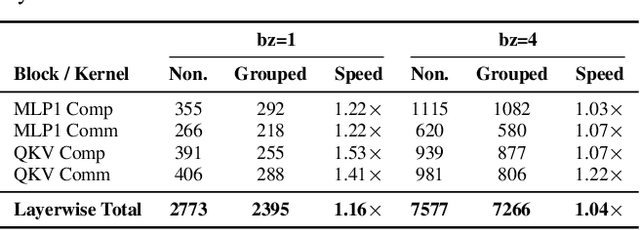
The scale of transformer model pre-training is constrained by the increasing computation and communication cost. Low-rank bottleneck architectures offer a promising solution to significantly reduce the training time and memory footprint with minimum impact on accuracy. Despite algorithmic efficiency, bottleneck architectures scale poorly under standard tensor parallelism. Simply applying 3D parallelism designed for full-rank methods leads to excessive communication and poor GPU utilization. To address this limitation, we propose BOOST, an efficient training framework tailored for large-scale low-rank bottleneck architectures. BOOST introduces a novel Bottleneck-aware Tensor Parallelism, and combines optimizations such as online-RMSNorm, linear layer grouping, and low-rank activation checkpointing to achieve end-to-end training speedup. Evaluations on different low-rank bottleneck architectures demonstrate that BOOST achieves 1.46-1.91$\times$ speedup over full-rank model baselines and 1.87-2.27$\times$ speedup over low-rank model with naively integrated 3D parallelism, with improved GPU utilization and reduced communication overhead.
LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing
Jul 30, 2025



Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch for fashion image generation (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel step-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model's multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple text-sketch pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.
Evaluating Attribute Confusion in Fashion Text-to-Image Generation
Jul 09, 2025Despite the rapid advances in Text-to-Image (T2I) generation models, their evaluation remains challenging in domains like fashion, involving complex compositional generation. Recent automated T2I evaluation methods leverage pre-trained vision-language models to measure cross-modal alignment. However, our preliminary study reveals that they are still limited in assessing rich entity-attribute semantics, facing challenges in attribute confusion, i.e., when attributes are correctly depicted but associated to the wrong entities. To address this, we build on a Visual Question Answering (VQA) localization strategy targeting one single entity at a time across both visual and textual modalities. We propose a localized human evaluation protocol and introduce a novel automatic metric, Localized VQAScore (L-VQAScore), that combines visual localization with VQA probing both correct (reflection) and miss-localized (leakage) attribute generation. On a newly curated dataset featuring challenging compositional alignment scenarios, L-VQAScore outperforms state-of-the-art T2I evaluation methods in terms of correlation with human judgments, demonstrating its strength in capturing fine-grained entity-attribute associations. We believe L-VQAScore can be a reliable and scalable alternative to subjective evaluations.
Fluid Aerial Networks: UAV Rotation for Inter-Cell Interference Mitigation
Jul 02, 2025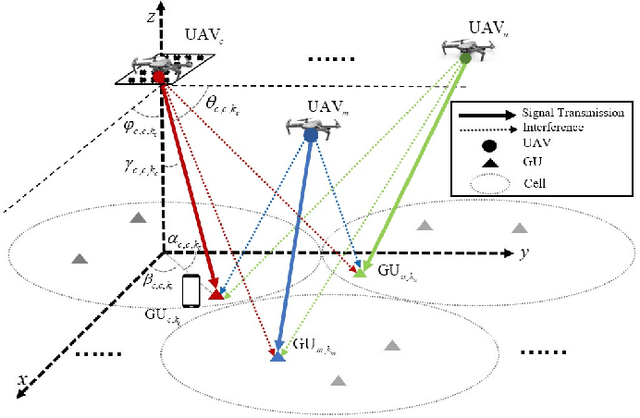
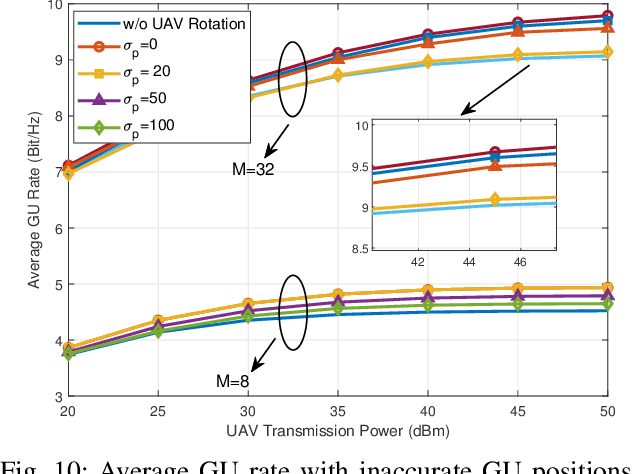
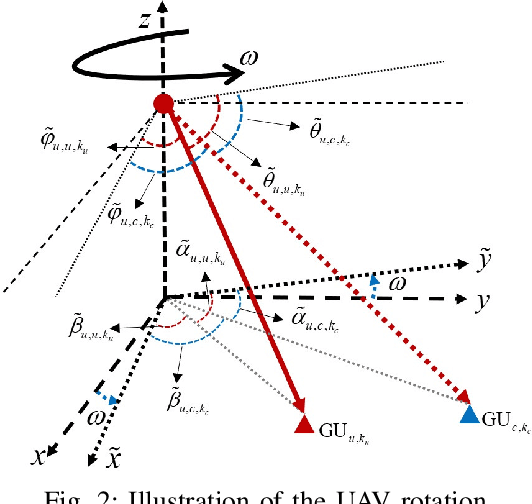
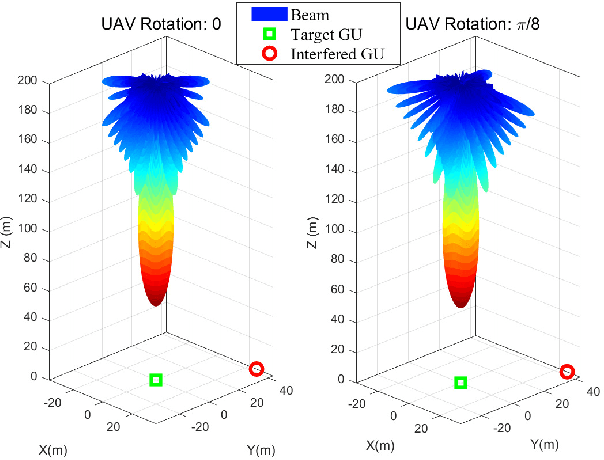
With the rapid development of aerial infrastructure, unmanned aerial vehicles (UAVs) that function as aerial base stations (ABSs) extend terrestrial network services into the sky, enabling on-demand connectivity and enhancing emergency communication capabilities in cellular networks by leveraging the flexibility and mobility of UAVs. In such a UAV-assisted network, this paper investigates position-based beamforming between ABSs and ground users (GUs). To mitigate inter-cell interference, we propose a novel fluid aerial network that leverages ABS rotation to increase multi-cell capacity and overall network efficiency. Specifically, considering the line-of-sight channel model, the spatial beamforming weights are determined by the orientation angles of the GUs. In this direction, we examine the beamforming gain of a two-dimensional multiple-input multiple-output (MIMO) array at various ground positions, revealing that ABS rotation significantly affects multi-user channel correlation and inter-cell interference. Based on these findings, we propose an alternative low-complexity algorithm to design the optimal rotation angle for ABSs, aiming to reduce inter-cell interference and thus maximize the sum rate of multi-cell systems. In simulations, exhaustive search serves as a benchmark to validate the optimization performance of the proposed sequential ABS rotation scheme. Moreover, simulation results demonstrate that, in interference-limited regions, the proposed ABS rotation paradigm can significantly reduce inter-cell interference in terrestrial networks and improve the multi-cell sum rate by approximately 10\% compared to fixed-direction ABSs without rotation.
LaX: Boosting Low-Rank Training of Foundation Models via Latent Crossing
May 27, 2025Training foundation models such as ViTs and LLMs requires tremendous computing cost. Low-rank matrix or tensor factorization offers a parameter-efficient alternative, but often downgrades performance due to the restricted parameter space. In this work, we introduce {\textbf{Latent Crossing (LaX)}} -- a simple yet effective plug-and-play module that enhances the capacity of low-rank models by enabling information flow across low-rank subspaces. We extensively validate the benefits of LaX on pre-training tasks with ViT-Base/Large and LLaMA-like models ranging from 60M to 1B parameters. LaX boosts low-rank model performance to match or exceed the full-rank baselines while using 2-3\(\times\) fewer parameters. When equipped with low-rank adapters (i.e., LoRA) for fine-tuning LLaMA-7/13B, LaX consistently improves performance on arithmetic and common sense reasoning tasks with negligible cost.
Seeing the Abstract: Translating the Abstract Language for Vision Language Models
May 06, 2025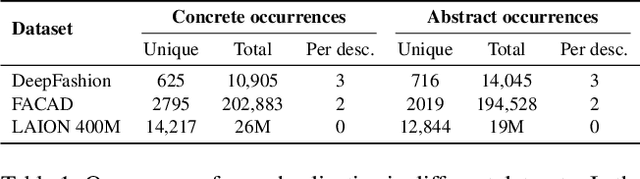


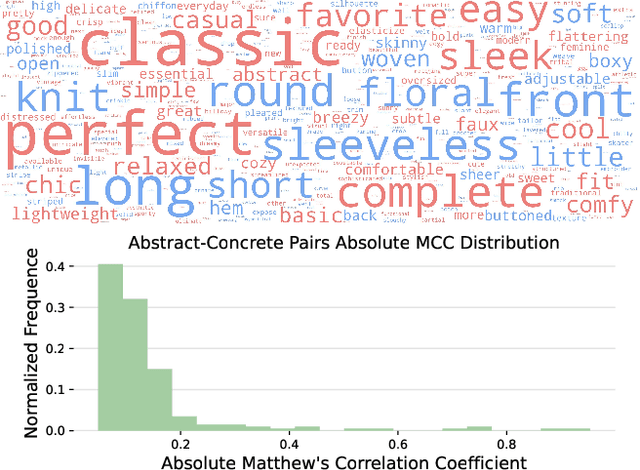
Natural language goes beyond dryly describing visual content. It contains rich abstract concepts to express feeling, creativity and properties that cannot be directly perceived. Yet, current research in Vision Language Models (VLMs) has not shed light on abstract-oriented language. Our research breaks new ground by uncovering its wide presence and under-estimated value, with extensive analysis. Particularly, we focus our investigation on the fashion domain, a highly-representative field with abstract expressions. By analyzing recent large-scale multimodal fashion datasets, we find that abstract terms have a dominant presence, rivaling the concrete ones, providing novel information, and being useful in the retrieval task. However, a critical challenge emerges: current general-purpose or fashion-specific VLMs are pre-trained with databases that lack sufficient abstract words in their text corpora, thus hindering their ability to effectively represent abstract-oriented language. We propose a training-free and model-agnostic method, Abstract-to-Concrete Translator (ACT), to shift abstract representations towards well-represented concrete ones in the VLM latent space, using pre-trained models and existing multimodal databases. On the text-to-image retrieval task, despite being training-free, ACT outperforms the fine-tuned VLMs in both same- and cross-dataset settings, exhibiting its effectiveness with a strong generalization capability. Moreover, the improvement introduced by ACT is consistent with various VLMs, making it a plug-and-play solution.