 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing
Jul 30, 2025



Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch for fashion image generation (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel step-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model's multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple text-sketch pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.
Evaluating Attribute Confusion in Fashion Text-to-Image Generation
Jul 09, 2025Despite the rapid advances in Text-to-Image (T2I) generation models, their evaluation remains challenging in domains like fashion, involving complex compositional generation. Recent automated T2I evaluation methods leverage pre-trained vision-language models to measure cross-modal alignment. However, our preliminary study reveals that they are still limited in assessing rich entity-attribute semantics, facing challenges in attribute confusion, i.e., when attributes are correctly depicted but associated to the wrong entities. To address this, we build on a Visual Question Answering (VQA) localization strategy targeting one single entity at a time across both visual and textual modalities. We propose a localized human evaluation protocol and introduce a novel automatic metric, Localized VQAScore (L-VQAScore), that combines visual localization with VQA probing both correct (reflection) and miss-localized (leakage) attribute generation. On a newly curated dataset featuring challenging compositional alignment scenarios, L-VQAScore outperforms state-of-the-art T2I evaluation methods in terms of correlation with human judgments, demonstrating its strength in capturing fine-grained entity-attribute associations. We believe L-VQAScore can be a reliable and scalable alternative to subjective evaluations.
Seeing the Abstract: Translating the Abstract Language for Vision Language Models
May 06, 2025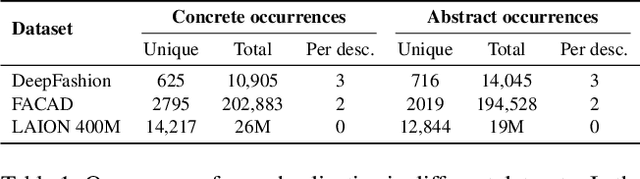


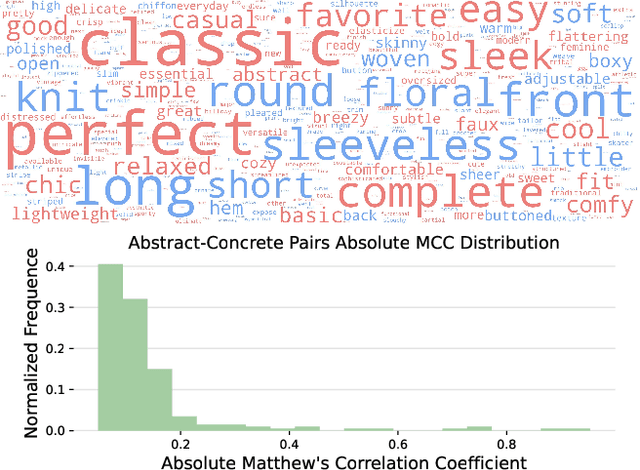
Natural language goes beyond dryly describing visual content. It contains rich abstract concepts to express feeling, creativity and properties that cannot be directly perceived. Yet, current research in Vision Language Models (VLMs) has not shed light on abstract-oriented language. Our research breaks new ground by uncovering its wide presence and under-estimated value, with extensive analysis. Particularly, we focus our investigation on the fashion domain, a highly-representative field with abstract expressions. By analyzing recent large-scale multimodal fashion datasets, we find that abstract terms have a dominant presence, rivaling the concrete ones, providing novel information, and being useful in the retrieval task. However, a critical challenge emerges: current general-purpose or fashion-specific VLMs are pre-trained with databases that lack sufficient abstract words in their text corpora, thus hindering their ability to effectively represent abstract-oriented language. We propose a training-free and model-agnostic method, Abstract-to-Concrete Translator (ACT), to shift abstract representations towards well-represented concrete ones in the VLM latent space, using pre-trained models and existing multimodal databases. On the text-to-image retrieval task, despite being training-free, ACT outperforms the fine-tuned VLMs in both same- and cross-dataset settings, exhibiting its effectiveness with a strong generalization capability. Moreover, the improvement introduced by ACT is consistent with various VLMs, making it a plug-and-play solution.
Training-Free Personalization via Retrieval and Reasoning on Fingerprints
Mar 24, 2025



Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation but heavily rely on training procedures, that can be either costly or unpleasant to individual users. We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain-of-thought-reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level: in case of a discrepancy between the scores, R2P refines the concept association via pairwise multimodal matching, where the retrieved fingerprints and their images are directly compared with the query. We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.
One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question Answering
Nov 04, 2024



Vision-Language Models (VLMs) have shown significant promise in Visual Question Answering (VQA) tasks by leveraging web-scale multimodal datasets. However, these models often struggle with continual learning due to catastrophic forgetting when adapting to new tasks. As an effective remedy to mitigate catastrophic forgetting, rehearsal strategy uses the data of past tasks upon learning new task. However, such strategy incurs the need of storing past data, which might not be feasible due to hardware constraints or privacy concerns. In this work, we propose the first data-free method that leverages the language generation capability of a VLM, instead of relying on external models, to produce pseudo-rehearsal data for addressing continual VQA. Our proposal, named as GaB, generates pseudo-rehearsal data by posing previous task questions on new task data. Yet, despite being effective, the distribution of generated questions skews towards the most frequently posed questions due to the limited and task-specific training data. To mitigate this issue, we introduce a pseudo-rehearsal balancing module that aligns the generated data towards the ground-truth data distribution using either the question meta-statistics or an unsupervised clustering method. We evaluate our proposed method on two recent benchmarks, \ie VQACL-VQAv2 and CLOVE-function benchmarks. GaB outperforms all the data-free baselines with substantial improvement in maintaining VQA performance across evolving tasks, while being on-par with methods with access to the past data.
Uncertainty-guided Open-Set Source-Free Unsupervised Domain Adaptation with Target-private Class Segregation
Apr 16, 2024Standard Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target but usually requires simultaneous access to both source and target data. Moreover, UDA approaches commonly assume that source and target domains share the same labels space. Yet, these two assumptions are hardly satisfied in real-world scenarios. This paper considers the more challenging Source-Free Open-set Domain Adaptation (SF-OSDA) setting, where both assumptions are dropped. We propose a novel approach for SF-OSDA that exploits the granularity of target-private categories by segregating their samples into multiple unknown classes. Starting from an initial clustering-based assignment, our method progressively improves the segregation of target-private samples by refining their pseudo-labels with the guide of an uncertainty-based sample selection module. Additionally, we propose a novel contrastive loss, named NL-InfoNCELoss, that, integrating negative learning into self-supervised contrastive learning, enhances the model robustness to noisy pseudo-labels. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed method over existing approaches, establishing new state-of-the-art performance. Notably, additional analyses show that our method is able to learn the underlying semantics of novel classes, opening the possibility to perform novel class discovery.
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
Key Design Choices in Source-Free Unsupervised Domain Adaptation: An In-depth Empirical Analysis
Feb 25, 2024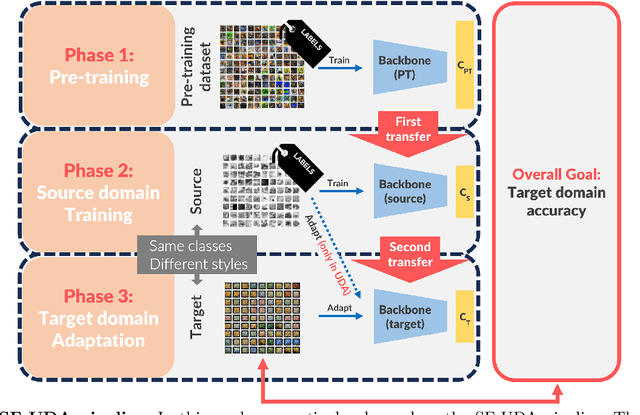
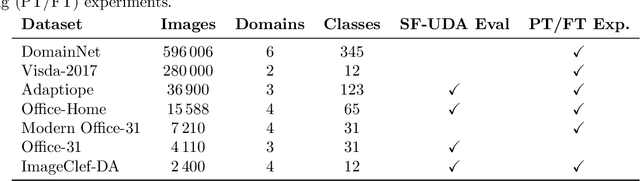


This study provides a comprehensive benchmark framework for Source-Free Unsupervised Domain Adaptation (SF-UDA) in image classification, aiming to achieve a rigorous empirical understanding of the complex relationships between multiple key design factors in SF-UDA methods. The study empirically examines a diverse set of SF-UDA techniques, assessing their consistency across datasets, sensitivity to specific hyperparameters, and applicability across different families of backbone architectures. Moreover, it exhaustively evaluates pre-training datasets and strategies, particularly focusing on both supervised and self-supervised methods, as well as the impact of fine-tuning on the source domain. Our analysis also highlights gaps in existing benchmark practices, guiding SF-UDA research towards more effective and general approaches. It emphasizes the importance of backbone architecture and pre-training dataset selection on SF-UDA performance, serving as an essential reference and providing key insights. Lastly, we release the source code of our experimental framework. This facilitates the construction, training, and testing of SF-UDA methods, enabling systematic large-scale experimental analysis and supporting further research efforts in this field.
Key Design Choices for Double-Transfer in Source-Free Unsupervised Domain Adaptation
Feb 10, 2023Fine-tuning and Domain Adaptation emerged as effective strategies for efficiently transferring deep learning models to new target tasks. However, target domain labels are not accessible in many real-world scenarios. This led to the development of Unsupervised Domain Adaptation (UDA) methods, which only employ unlabeled target samples. Furthermore, efficiency and privacy requirements may also prevent the use of source domain data during the adaptation stage. This challenging setting, known as Source-Free Unsupervised Domain Adaptation (SF-UDA), is gaining interest among researchers and practitioners due to its potential for real-world applications. In this paper, we provide the first in-depth analysis of the main design choices in SF-UDA through a large-scale empirical study across 500 models and 74 domain pairs. We pinpoint the normalization approach, pre-training strategy, and backbone architecture as the most critical factors. Based on our quantitative findings, we propose recipes to best tackle SF-UDA scenarios. Moreover, we show that SF-UDA is competitive also beyond standard benchmarks and backbone architectures, performing on par with UDA at a fraction of the data and computational cost. In the interest of reproducibility, we include the full experimental results and code as supplementary material.
GANzzle: Reframing jigsaw puzzle solving as a retrieval task using a generative mental image
Jul 12, 2022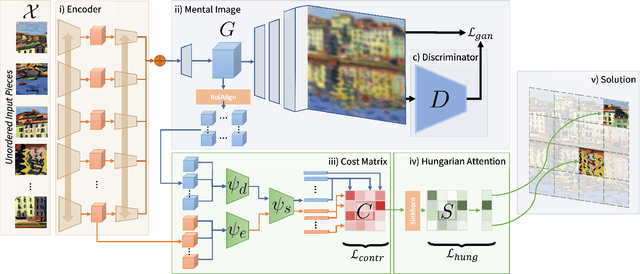
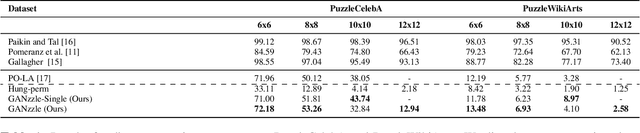


Puzzle solving is a combinatorial challenge due to the difficulty of matching adjacent pieces. Instead, we infer a mental image from all pieces, which a given piece can then be matched against avoiding the combinatorial explosion. Exploiting advancements in Generative Adversarial methods, we learn how to reconstruct the image given a set of unordered pieces, allowing the model to learn a joint embedding space to match an encoding of each piece to the cropped layer of the generator. Therefore we frame the problem as a R@1 retrieval task, and then solve the linear assignment using differentiable Hungarian attention, making the process end-to-end. In doing so our model is puzzle size agnostic, in contrast to prior deep learning methods which are single size. We evaluate on two new large-scale datasets, where our model is on par with deep learning methods, while generalizing to multiple puzzle sizes.