 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Personalization via Retrieval and Reasoning on Fingerprints
Mar 24, 2025



Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation but heavily rely on training procedures, that can be either costly or unpleasant to individual users. We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain-of-thought-reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level: in case of a discrepancy between the scores, R2P refines the concept association via pairwise multimodal matching, where the retrieved fingerprints and their images are directly compared with the query. We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.
One VLM to Keep it Learning: Generation and Balancing for Data-free Continual Visual Question Answering
Nov 04, 2024



Vision-Language Models (VLMs) have shown significant promise in Visual Question Answering (VQA) tasks by leveraging web-scale multimodal datasets. However, these models often struggle with continual learning due to catastrophic forgetting when adapting to new tasks. As an effective remedy to mitigate catastrophic forgetting, rehearsal strategy uses the data of past tasks upon learning new task. However, such strategy incurs the need of storing past data, which might not be feasible due to hardware constraints or privacy concerns. In this work, we propose the first data-free method that leverages the language generation capability of a VLM, instead of relying on external models, to produce pseudo-rehearsal data for addressing continual VQA. Our proposal, named as GaB, generates pseudo-rehearsal data by posing previous task questions on new task data. Yet, despite being effective, the distribution of generated questions skews towards the most frequently posed questions due to the limited and task-specific training data. To mitigate this issue, we introduce a pseudo-rehearsal balancing module that aligns the generated data towards the ground-truth data distribution using either the question meta-statistics or an unsupervised clustering method. We evaluate our proposed method on two recent benchmarks, \ie VQACL-VQAv2 and CLOVE-function benchmarks. GaB outperforms all the data-free baselines with substantial improvement in maintaining VQA performance across evolving tasks, while being on-par with methods with access to the past data.
Mitigating the Effect of Incidental Correlations on Part-based Learning
Sep 30, 2023



Intelligent systems possess a crucial characteristic of breaking complicated problems into smaller reusable components or parts and adjusting to new tasks using these part representations. However, current part-learners encounter difficulties in dealing with incidental correlations resulting from the limited observations of objects that may appear only in specific arrangements or with specific backgrounds. These incidental correlations may have a detrimental impact on the generalization and interpretability of learned part representations. This study asserts that part-based representations could be more interpretable and generalize better with limited data, employing two innovative regularization methods. The first regularization separates foreground and background information's generative process via a unique mixture-of-parts formulation. Structural constraints are imposed on the parts using a weakly-supervised loss, guaranteeing that the mixture-of-parts for foreground and background entails soft, object-agnostic masks. The second regularization assumes the form of a distillation loss, ensuring the invariance of the learned parts to the incidental background correlations. Furthermore, we incorporate sparse and orthogonal constraints to facilitate learning high-quality part representations. By reducing the impact of incidental background correlations on the learned parts, we exhibit state-of-the-art (SoTA) performance on few-shot learning tasks on benchmark datasets, including MiniImagenet, TieredImageNet, and FC100. We also demonstrate that the part-based representations acquired through our approach generalize better than existing techniques, even under domain shifts of the background and common data corruption on the ImageNet-9 dataset. The implementation is available on GitHub: https://github.com/GauravBh1010tt/DPViT.git
A Cost Efficient Approach to Correct OCR Errors in Large Document Collections
May 28, 2019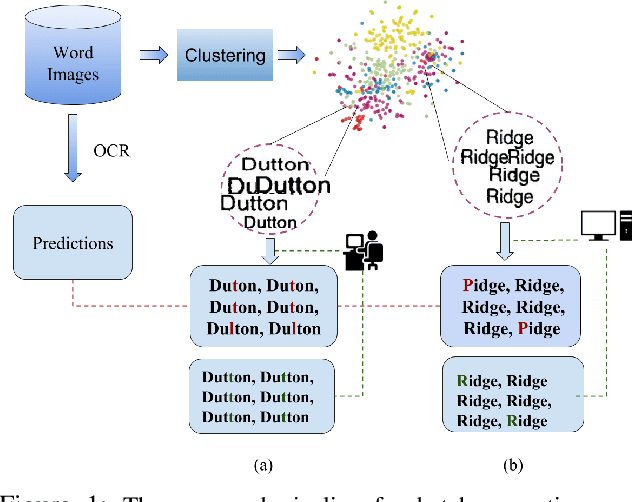


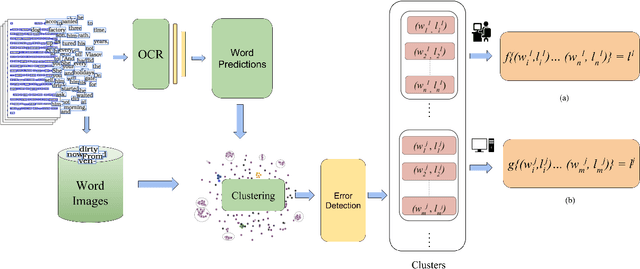
Word error rate of an ocr is often higher than its character error rate. This is especially true when ocrs are designed by recognizing characters. High word accuracies are critical to tasks like the creation of content in digital libraries and text-to-speech applications. In order to detect and correct the misrecognised words, it is common for an ocr module to employ a post-processor to further improve the word accuracy. However, conventional approaches to post-processing like looking up a dictionary or using a statistical language model (slm), are still limited. In many such scenarios, it is often required to remove the outstanding errors manually. We observe that the traditional post-processing schemes look at error words sequentially since ocrs process documents one at a time. We propose a cost-efficient model to address the error words in batches rather than correcting them individually. We exploit the fact that a collection of documents, unlike a single document, has a structure leading to repetition of words. Such words, if efficiently grouped together and corrected as a whole can lead to a significant reduction in the cost. Correction can be fully automatic or with a human in the loop. Towards this, we employ a novel clustering scheme to obtain fairly homogeneous clusters. We compare the performance of our model with various baseline approaches including the case where all the errors are removed by a human. We demonstrate the efficacy of our solution empirically by reporting more than 70% reduction in the human effort with near perfect error correction. We validate our method on Books from multiple languages.