 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Low Resource Status of Indian Languages in Machine Translation
Aug 11, 2020
Indian language machine translation performance is hampered due to the lack of large scale multi-lingual sentence aligned corpora and robust benchmarks. Through this paper, we provide and analyse an automated framework to obtain such a corpus for Indian language neural machine translation (NMT) systems. Our pipeline consists of a baseline NMT system, a retrieval module, and an alignment module that is used to work with publicly available websites such as press releases by the government. The main contribution towards this effort is to obtain an incremental method that uses the above pipeline to iteratively improve the size of the corpus as well as improve each of the components of our system. Through our work, we also evaluate the design choices such as the choice of pivoting language and the effect of iterative incremental increase in corpus size. Our work in addition to providing an automated framework also results in generating a relatively larger corpus as compared to existing corpora that are available for Indian languages. This corpus helps us obtain substantially improved results on the publicly available WAT evaluation benchmark and other standard evaluation benchmarks.
A Multilingual Parallel Corpora Collection Effort for Indian Languages
Jul 15, 2020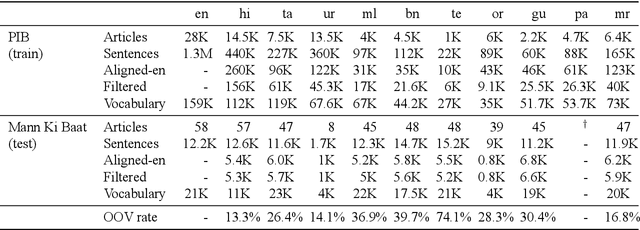
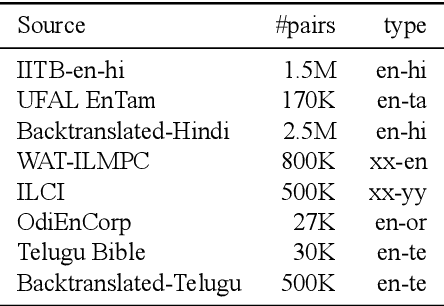


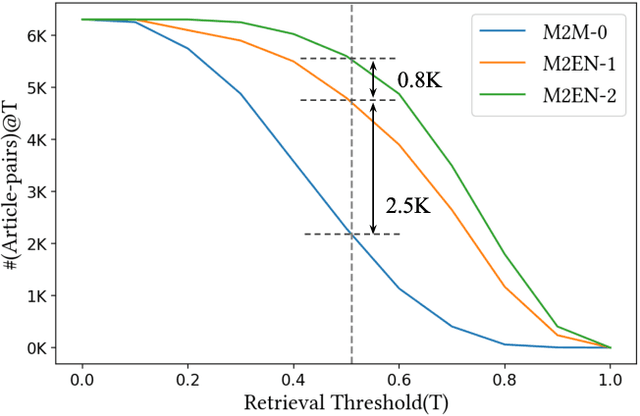
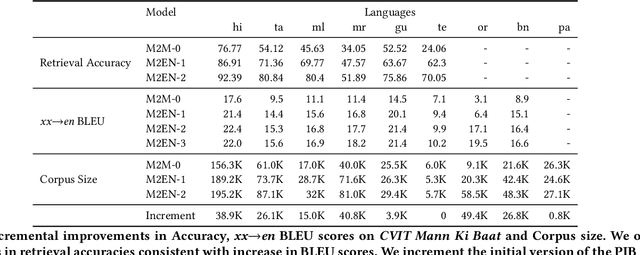
We present sentence aligned parallel corpora across 10 Indian Languages - Hindi, Telugu, Tamil, Malayalam, Gujarati, Urdu, Bengali, Oriya, Marathi, Punjabi, and English - many of which are categorized as low resource. The corpora are compiled from online sources which have content shared across languages. The corpora presented significantly extends present resources that are either not large enough or are restricted to a specific domain (such as health). We also provide a separate test corpus compiled from an independent online source that can be independently used for validating the performance in 10 Indian languages. Alongside, we report on the methods of constructing such corpora using tools enabled by recent advances in machine translation and cross-lingual retrieval using deep neural network based methods.
Towards Automatic Face-to-Face Translation
Mar 01, 2020
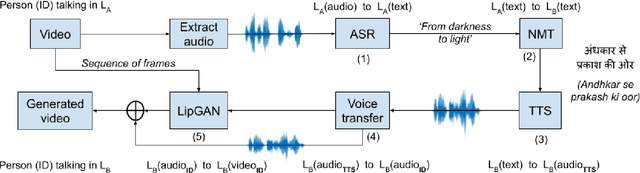

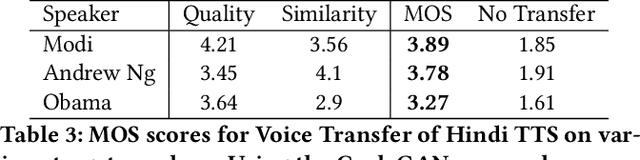
In light of the recent breakthroughs in automatic machine translation systems, we propose a novel approach that we term as "Face-to-Face Translation". As today's digital communication becomes increasingly visual, we argue that there is a need for systems that can automatically translate a video of a person speaking in language A into a target language B with realistic lip synchronization. In this work, we create an automatic pipeline for this problem and demonstrate its impact on multiple real-world applications. First, we build a working speech-to-speech translation system by bringing together multiple existing modules from speech and language. We then move towards "Face-to-Face Translation" by incorporating a novel visual module, LipGAN for generating realistic talking faces from the translated audio. Quantitative evaluation of LipGAN on the standard LRW test set shows that it significantly outperforms existing approaches across all standard metrics. We also subject our Face-to-Face Translation pipeline, to multiple human evaluations and show that it can significantly improve the overall user experience for consuming and interacting with multimodal content across languages. Code, models and demo video are made publicly available. Demo video: https://www.youtube.com/watch?v=aHG6Oei8jF0 Code and models: https://github.com/Rudrabha/LipGAN
* 9 pages (including references), 5 figures, Published in ACM Multimedia, 2019
A Baseline Neural Machine Translation System for Indian Languages
Jul 29, 2019
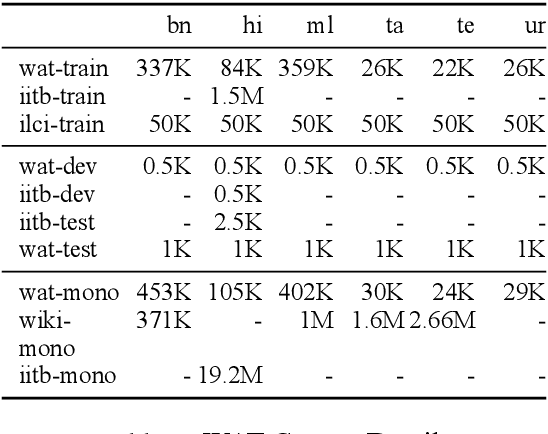


We present a simple, yet effective, Neural Machine Translation system for Indian languages. We demonstrate the feasibility for multiple language pairs, and establish a strong baseline for further research.
A Cost Efficient Approach to Correct OCR Errors in Large Document Collections
May 28, 2019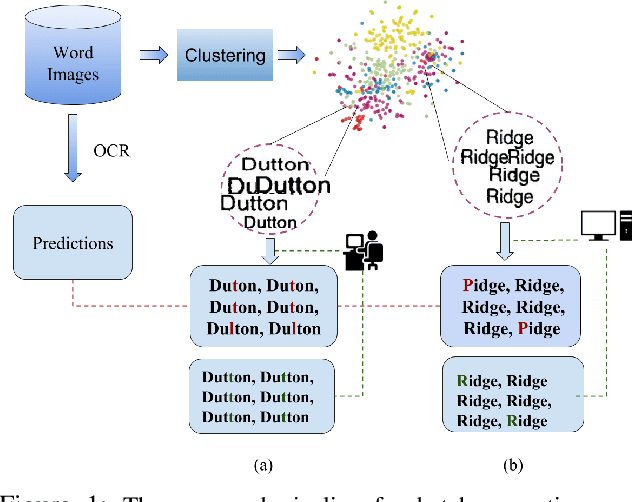


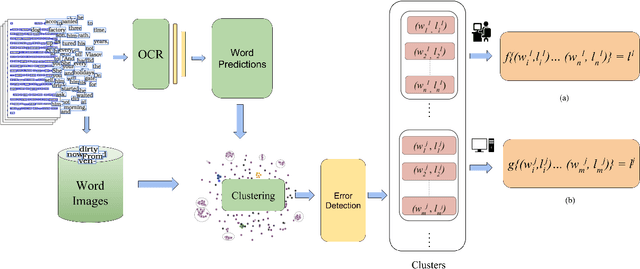
Word error rate of an ocr is often higher than its character error rate. This is especially true when ocrs are designed by recognizing characters. High word accuracies are critical to tasks like the creation of content in digital libraries and text-to-speech applications. In order to detect and correct the misrecognised words, it is common for an ocr module to employ a post-processor to further improve the word accuracy. However, conventional approaches to post-processing like looking up a dictionary or using a statistical language model (slm), are still limited. In many such scenarios, it is often required to remove the outstanding errors manually. We observe that the traditional post-processing schemes look at error words sequentially since ocrs process documents one at a time. We propose a cost-efficient model to address the error words in batches rather than correcting them individually. We exploit the fact that a collection of documents, unlike a single document, has a structure leading to repetition of words. Such words, if efficiently grouped together and corrected as a whole can lead to a significant reduction in the cost. Correction can be fully automatic or with a human in the loop. Towards this, we employ a novel clustering scheme to obtain fairly homogeneous clusters. We compare the performance of our model with various baseline approaches including the case where all the errors are removed by a human. We demonstrate the efficacy of our solution empirically by reporting more than 70% reduction in the human effort with near perfect error correction. We validate our method on Books from multiple languages.
CVIT-MT Systems for WAT-2018
Mar 19, 2019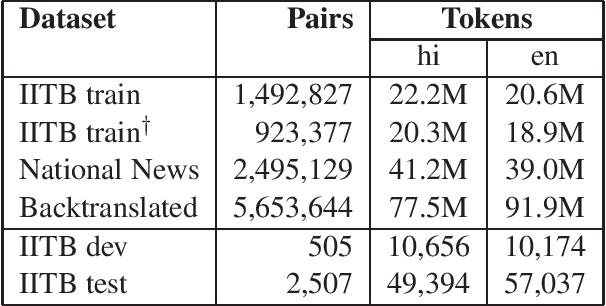
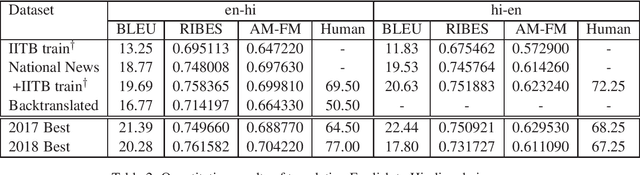
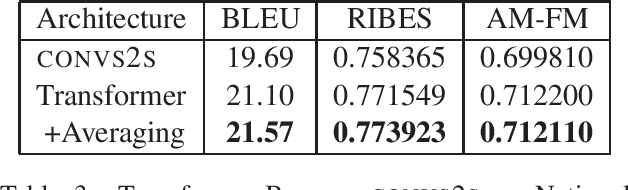
This document describes the machine translation system used in the submissions of IIIT-Hyderabad CVIT-MT for the WAT-2018 English-Hindi translation task. Performance is evaluated on the associated corpus provided by the organizers. We experimented with convolutional sequence to sequence architectures. We also train with additional data obtained through backtranslation.