 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Parallel Corpora Collection Effort for Indian Languages
Paper and Code
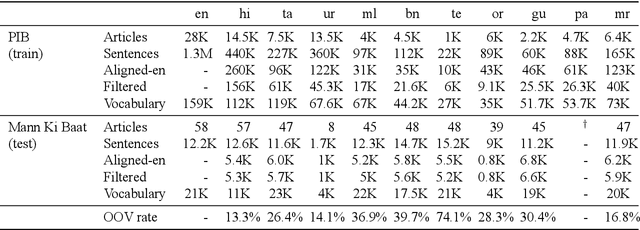
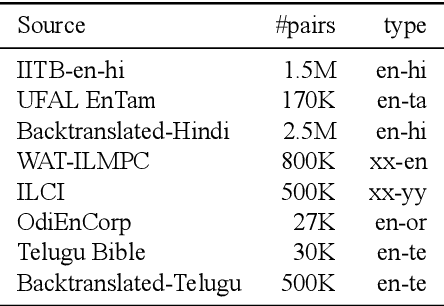


We present sentence aligned parallel corpora across 10 Indian Languages - Hindi, Telugu, Tamil, Malayalam, Gujarati, Urdu, Bengali, Oriya, Marathi, Punjabi, and English - many of which are categorized as low resource. The corpora are compiled from online sources which have content shared across languages. The corpora presented significantly extends present resources that are either not large enough or are restricted to a specific domain (such as health). We also provide a separate test corpus compiled from an independent online source that can be independently used for validating the performance in 10 Indian languages. Alongside, we report on the methods of constructing such corpora using tools enabled by recent advances in machine translation and cross-lingual retrieval using deep neural network based methods.