 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Face-to-Face Translation
Paper and Code
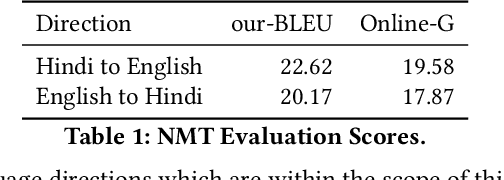
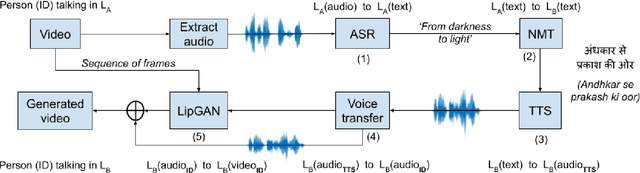

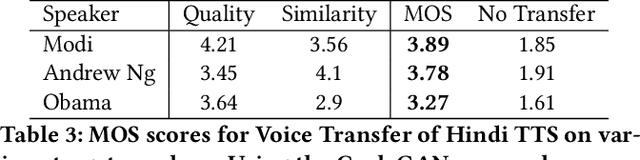
In light of the recent breakthroughs in automatic machine translation systems, we propose a novel approach that we term as "Face-to-Face Translation". As today's digital communication becomes increasingly visual, we argue that there is a need for systems that can automatically translate a video of a person speaking in language A into a target language B with realistic lip synchronization. In this work, we create an automatic pipeline for this problem and demonstrate its impact on multiple real-world applications. First, we build a working speech-to-speech translation system by bringing together multiple existing modules from speech and language. We then move towards "Face-to-Face Translation" by incorporating a novel visual module, LipGAN for generating realistic talking faces from the translated audio. Quantitative evaluation of LipGAN on the standard LRW test set shows that it significantly outperforms existing approaches across all standard metrics. We also subject our Face-to-Face Translation pipeline, to multiple human evaluations and show that it can significantly improve the overall user experience for consuming and interacting with multimodal content across languages. Code, models and demo video are made publicly available. Demo video: https://www.youtube.com/watch?v=aHG6Oei8jF0 Code and models: https://github.com/Rudrabha/LipGAN