 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Lip-to-Speech Synthesis in-the-Wild
Mar 02, 2024In this paper, we introduce a novel approach to address the task of synthesizing speech from silent videos of any in-the-wild speaker solely based on lip movements. The traditional approach of directly generating speech from lip videos faces the challenge of not being able to learn a robust language model from speech alone, resulting in unsatisfactory outcomes. To overcome this issue, we propose incorporating noisy text supervision using a state-of-the-art lip-to-text network that instills language information into our model. The noisy text is generated using a pre-trained lip-to-text model, enabling our approach to work without text annotations during inference. We design a visual text-to-speech network that utilizes the visual stream to generate accurate speech, which is in-sync with the silent input video. We perform extensive experiments and ablation studies, demonstrating our approach's superiority over the current state-of-the-art methods on various benchmark datasets. Further, we demonstrate an essential practical application of our method in assistive technology by generating speech for an ALS patient who has lost the voice but can make mouth movements. Our demo video, code, and additional details can be found at \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/ms-l2s-itw}.
* 8 pages of content, 1 page of references and 4 figures
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022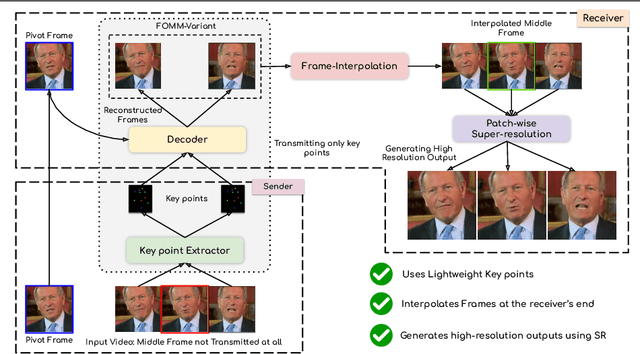
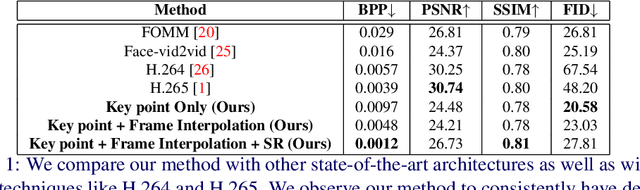
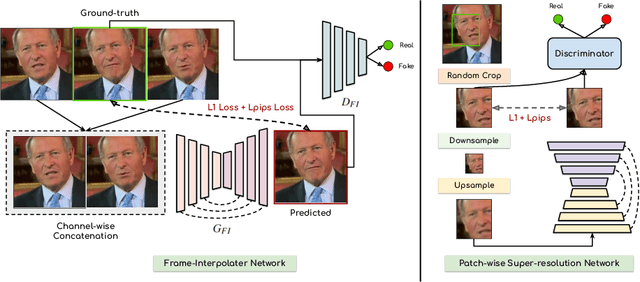
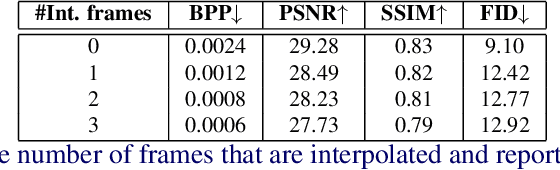
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
Audio-Visual Face Reenactment
Oct 06, 2022
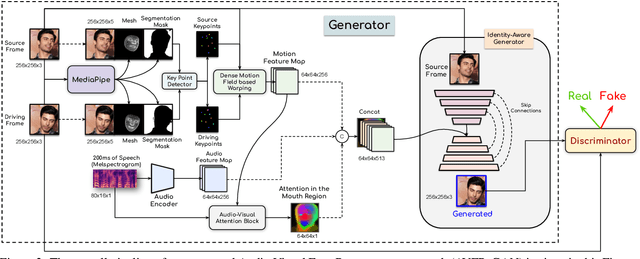


This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sep 01, 2022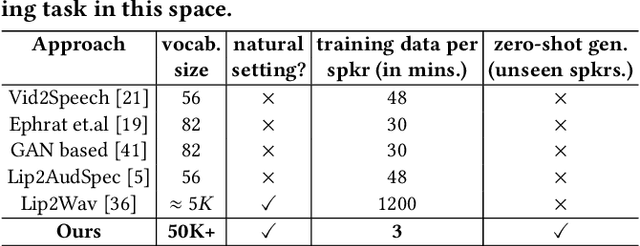
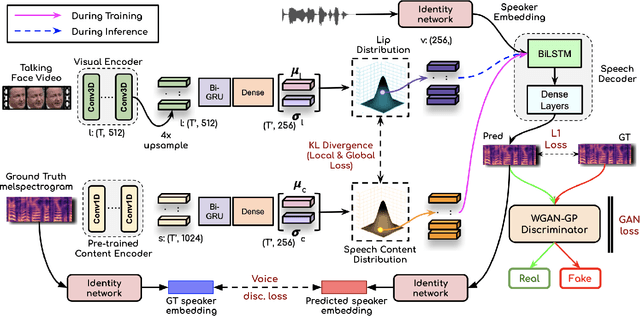
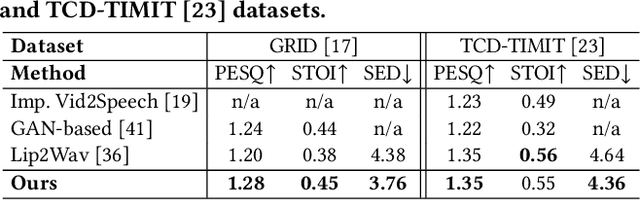
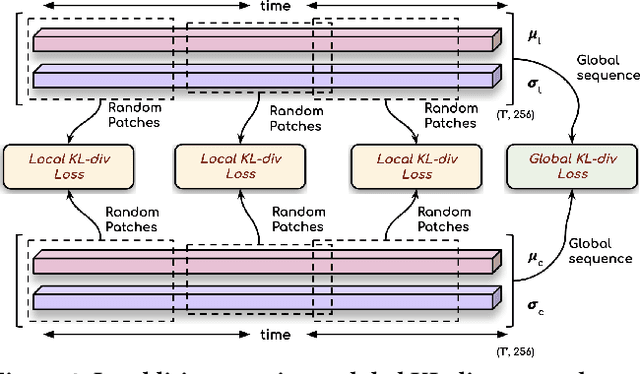
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works, our method (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges, with the key one being that many features of the desired target speech, like voice, pitch and linguistic content, cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baselines by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on $4\times$ more data. We conduct numerous ablation studies to analyze the effect of different modules of our architecture. We also provide a demo video that demonstrates several qualitative results along with the code and trained models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/lip-to-speech-synthesis}}
Towards MOOCs for Lip Reading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Aug 21, 2022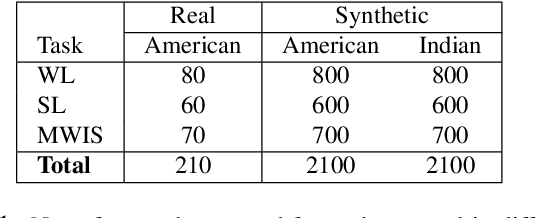
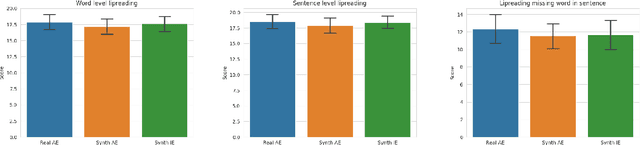
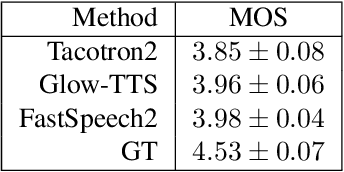

Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in COVID$19$ pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many kinds of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in the vocabulary, supported languages, accents, and speakers, and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can be used to easily incorporate larger vocabularies, variations in accent, and even local languages, and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking heading video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading exercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point towards the potential of our approach for the development of a large-scale lipreading MOOCs platform that can impact millions of people with hearing loss.
FaceOff: A Video-to-Video Face Swapping System
Aug 21, 2022

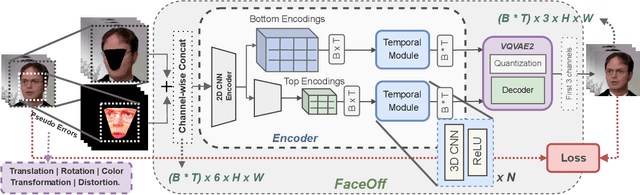
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or in scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods can not preserve the source expressions of the actor important for the scene's context. % essential for the scene. % that are essential in cinemas. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It first reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Aug 17, 2022

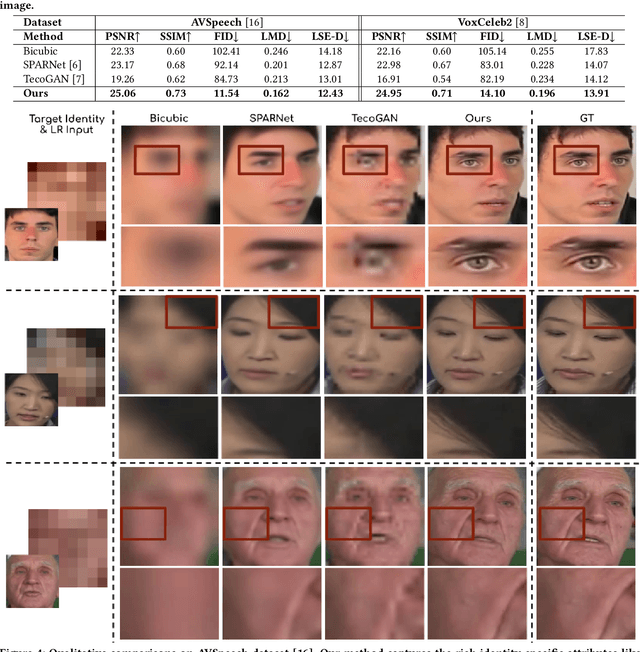
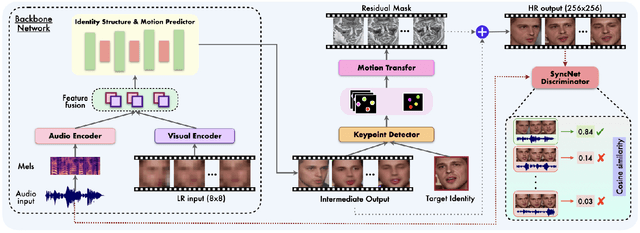
In this paper, we explore an interesting question of what can be obtained from an $8\times8$ pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video. We achieve this $32\times$ scaling of an extremely low-resolution input using our novel audio-visual upsampling network. The audio prior helps to recover the elemental facial details and precise lip shapes and a single high-resolution target identity image prior provides us with rich appearance details. Our approach is an end-to-end multi-stage framework. The first stage produces a coarse intermediate output video that can be then used to animate single target identity image and generate realistic, accurate and high-quality outputs. Our approach is simple and performs exceedingly well (an $8\times$ improvement in FID score) compared to previous super-resolution methods. We also extend our model to talking-face video compression, and show that we obtain a $3.5\times$ improvement in terms of bits/pixel over the previous state-of-the-art. The results from our network are thoroughly analyzed through extensive ablation experiments (in the paper and supplementary material). We also provide the demo video along with code and models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/talking-face-video-upsampling}.
Personalized One-Shot Lipreading for an ALS Patient
Nov 02, 2021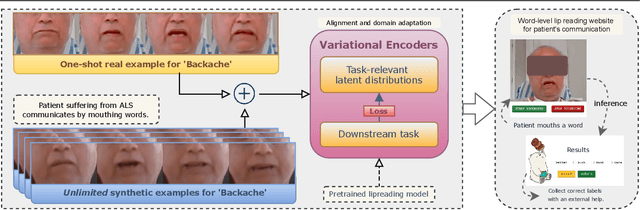

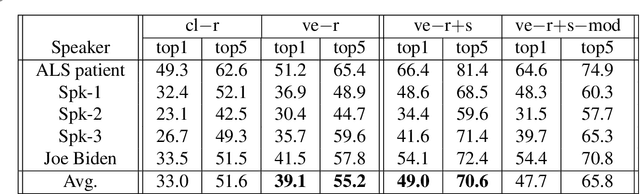
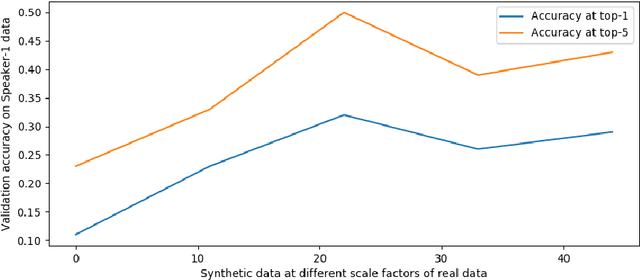
Lipreading or visually recognizing speech from the mouth movements of a speaker is a challenging and mentally taxing task. Unfortunately, multiple medical conditions force people to depend on this skill in their day-to-day lives for essential communication. Patients suffering from Amyotrophic Lateral Sclerosis (ALS) often lose muscle control, consequently their ability to generate speech and communicate via lip movements. Existing large datasets do not focus on medical patients or curate personalized vocabulary relevant to an individual. Collecting a large-scale dataset of a patient, needed to train mod-ern data-hungry deep learning models is, however, extremely challenging. In this work, we propose a personalized network to lipread an ALS patient using only one-shot examples. We depend on synthetically generated lip movements to augment the one-shot scenario. A Variational Encoder based domain adaptation technique is used to bridge the real-synthetic domain gap. Our approach significantly improves and achieves high top-5accuracy with 83.2% accuracy compared to 62.6% achieved by comparable methods for the patient. Apart from evaluating our approach on the ALS patient, we also extend it to people with hearing impairment relying extensively on lip movements to communicate.
Intelligent Video Editing: Incorporating Modern Talking Face Generation Algorithms in a Video Editor
Oct 16, 2021
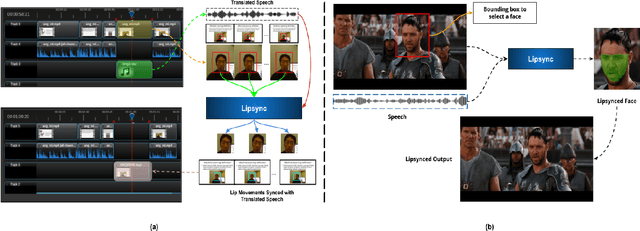

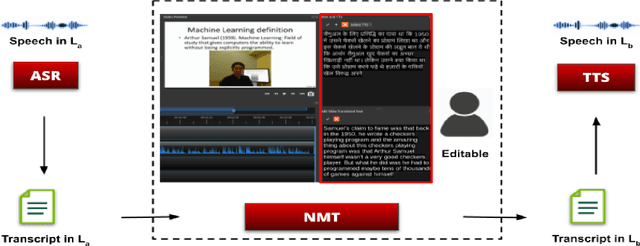
This paper proposes a video editor based on OpenShot with several state-of-the-art facial video editing algorithms as added functionalities. Our editor provides an easy-to-use interface to apply modern lip-syncing algorithms interactively. Apart from lip-syncing, the editor also uses audio and facial re-enactment to generate expressive talking faces. The manual control improves the overall experience of video editing without missing out on the benefits of modern synthetic video generation algorithms. This control enables us to lip-sync complex dubbed movie scenes, interviews, television shows, and other visual content. Furthermore, our editor provides features that automatically translate lectures from spoken content, lip-sync of the professor, and background content like slides. While doing so, we also tackle the critical aspect of synchronizing background content with the translated speech. We qualitatively evaluate the usefulness of the proposed editor by conducting human evaluations. Our evaluations show a clear improvement in the efficiency of using human editors and an improved video generation quality. We attach demo videos with the supplementary material clearly explaining the tool and also showcasing multiple results.
Towards Automatic Speech to Sign Language Generation
Jun 24, 2021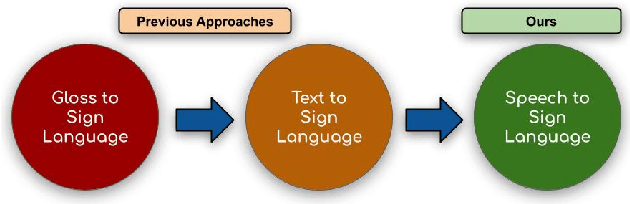
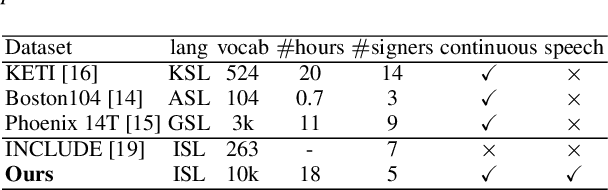

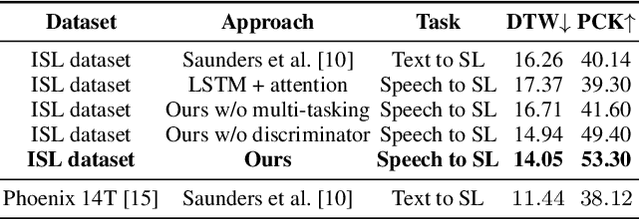
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, we eliminate the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, we collect and release the first Indian sign language dataset comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Next, we propose a multi-tasking transformer network trained to generate signer's poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, our model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of our approach. We also conduct additional ablation studies to analyze the effect of different modules of our network. A demo video containing several results is attached to the supplementary material.