 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Lip-to-Speech Synthesis in-the-Wild
Mar 02, 2024In this paper, we introduce a novel approach to address the task of synthesizing speech from silent videos of any in-the-wild speaker solely based on lip movements. The traditional approach of directly generating speech from lip videos faces the challenge of not being able to learn a robust language model from speech alone, resulting in unsatisfactory outcomes. To overcome this issue, we propose incorporating noisy text supervision using a state-of-the-art lip-to-text network that instills language information into our model. The noisy text is generated using a pre-trained lip-to-text model, enabling our approach to work without text annotations during inference. We design a visual text-to-speech network that utilizes the visual stream to generate accurate speech, which is in-sync with the silent input video. We perform extensive experiments and ablation studies, demonstrating our approach's superiority over the current state-of-the-art methods on various benchmark datasets. Further, we demonstrate an essential practical application of our method in assistive technology by generating speech for an ALS patient who has lost the voice but can make mouth movements. Our demo video, code, and additional details can be found at \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/ms-l2s-itw}.
* 8 pages of content, 1 page of references and 4 figures
PIG-Net: Inception based Deep Learning Architecture for 3D Point Cloud Segmentation
Jan 28, 2021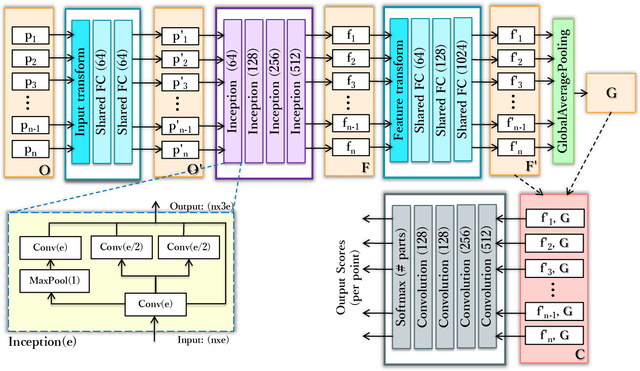



Point clouds, being the simple and compact representation of surface geometry of 3D objects, have gained increasing popularity with the evolution of deep learning networks for classification and segmentation tasks. Unlike human, teaching the machine to analyze the segments of an object is a challenging task and quite essential in various machine vision applications. In this paper, we address the problem of segmentation and labelling of the 3D point clouds by proposing a inception based deep network architecture called PIG-Net, that effectively characterizes the local and global geometric details of the point clouds. In PIG-Net, the local features are extracted from the transformed input points using the proposed inception layers and then aligned by feature transform. These local features are aggregated using the global average pooling layer to obtain the global features. Finally, feed the concatenated local and global features to the convolution layers for segmenting the 3D point clouds. We perform an exhaustive experimental analysis of the PIG-Net architecture on two state-of-the-art datasets, namely, ShapeNet [1] and PartNet [2]. We evaluate the effectiveness of our network by performing ablation study.