 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRSD: Multi-Resolution Skill Discovery for HRL Agents
May 27, 2025Hierarchical reinforcement learning (HRL) relies on abstract skills to solve long-horizon tasks efficiently. While existing skill discovery methods learns these skills automatically, they are limited to a single skill per task. In contrast, humans learn and use both fine-grained and coarse motor skills simultaneously. Inspired by human motor control, we propose Multi-Resolution Skill Discovery (MRSD), an HRL framework that learns multiple skill encoders at different temporal resolutions in parallel. A high-level manager dynamically selects among these skills, enabling adaptive control strategies over time. We evaluate MRSD on tasks from the DeepMind Control Suite and show that it outperforms prior state-of-the-art skill discovery and HRL methods, achieving faster convergence and higher final performance. Our findings highlight the benefits of integrating multi-resolution skills in HRL, paving the way for more versatile and efficient agents.
DHP: Discrete Hierarchical Planning for Hierarchical Reinforcement Learning Agents
Feb 04, 2025In this paper, we address the challenge of long-horizon visual planning tasks using Hierarchical Reinforcement Learning (HRL). Our key contribution is a Discrete Hierarchical Planning (DHP) method, an alternative to traditional distance-based approaches. We provide theoretical foundations for the method and demonstrate its effectiveness through extensive empirical evaluations. Our agent recursively predicts subgoals in the context of a long-term goal and receives discrete rewards for constructing plans as compositions of abstract actions. The method introduces a novel advantage estimation strategy for tree trajectories, which inherently encourages shorter plans and enables generalization beyond the maximum tree depth. The learned policy function allows the agent to plan efficiently, requiring only $\log N$ computational steps, making re-planning highly efficient. The agent, based on a soft-actor critic (SAC) framework, is trained using on-policy imagination data. Additionally, we propose a novel exploration strategy that enables the agent to generate relevant training examples for the planning modules. We evaluate our method on long-horizon visual planning tasks in a 25-room environment, where it significantly outperforms previous benchmarks at success rate and average episode length. Furthermore, an ablation study highlights the individual contributions of key modules to the overall performance.
MedFocusCLIP : Improving few shot classification in medical datasets using pixel wise attention
Jan 07, 2025



With the popularity of foundational models, parameter efficient fine tuning has become the defacto approach to leverage pretrained models to perform downstream tasks. Taking inspiration from recent advances in large language models, Visual Prompt Tuning, and similar techniques, learn an additional prompt to efficiently finetune a pretrained vision foundational model. However, we observe that such prompting is insufficient for fine-grained visual classification tasks such as medical image classification, where there is large inter-class variance, and small intra-class variance. Hence, in this paper we propose to leverage advanced segmentation capabilities of Segment Anything Model 2 (SAM2) as a visual prompting cue to help visual encoder in the CLIP (Contrastive Language-Image Pretraining) by guiding the attention in CLIP visual encoder to relevant regions in the image. This helps the model to focus on highly discriminative regions, without getting distracted from visually similar background features, an essential requirement in a fewshot, finegrained classification setting. We evaluate our method on diverse medical datasets including X-rays, CT scans, and MRI images, and report an accuracy of (71%, 81%, 86%, 58%) from the proposed approach on (COVID, lung-disease, brain-tumor, breast-cancer) datasets against (66%, 70%, 68%, 29%) from a pretrained CLIP model after fewshot training. The proposed approach also allows to obtain interpretable explanation for the classification performance through the localization obtained using segmentation.
CLIP Adaptation by Intra-modal Overlap Reduction
Sep 17, 2024Numerous methods have been proposed to adapt a pre-trained foundational CLIP model for few-shot classification. As CLIP is trained on a large corpus, it generalises well through adaptation to few-shot classification. In this work, we analyse the intra-modal overlap in image space in terms of embedding representation. Our analysis shows that, due to contrastive learning, embeddings from CLIP model exhibit high cosine similarity distribution overlap in the image space between paired and unpaired examples affecting the performance of few-shot training-free classification methods which rely on similarity in the image space for their predictions. To tackle intra-modal overlap we propose to train a lightweight adapter on a generic set of samples from the Google Open Images dataset demonstrating that this improves accuracy for few-shot training-free classification. We validate our contribution through extensive empirical analysis and demonstrate that reducing the intra-modal overlap leads to a) improved performance on a number of standard datasets, b) increased robustness to distribution shift and c) higher feature variance rendering the features more discriminative for downstream tasks.
TalkLoRA: Low-Rank Adaptation for Speech-Driven Animation
Aug 25, 2024Speech-driven facial animation is important for many applications including TV, film, video games, telecommunication and AR/VR. Recently, transformers have been shown to be extremely effective for this task. However, we identify two issues with the existing transformer-based models. Firstly, they are difficult to adapt to new personalised speaking styles and secondly, they are slow to run for long sentences due to the quadratic complexity of the transformer. We propose TalkLoRA to address both of these issues. TalkLoRA uses Low-Rank Adaptation to effectively and efficiently adapt to new speaking styles, even with limited data. It does this by training an adaptor with a small number of parameters for each subject. We also utilise a chunking strategy to reduce the complexity of the underlying transformer, allowing for long sentences at inference time. TalkLoRA can be applied to any transformer-based speech-driven animation method. We perform extensive experiments to show that TalkLoRA archives state-of-the-art style adaptation and that it allows for an order-of-complexity reduction in inference times without sacrificing quality. We also investigate and provide insights into the hyperparameter selection for LoRA fine-tuning of speech-driven facial animation models.
Towards Accurate Lip-to-Speech Synthesis in-the-Wild
Mar 02, 2024In this paper, we introduce a novel approach to address the task of synthesizing speech from silent videos of any in-the-wild speaker solely based on lip movements. The traditional approach of directly generating speech from lip videos faces the challenge of not being able to learn a robust language model from speech alone, resulting in unsatisfactory outcomes. To overcome this issue, we propose incorporating noisy text supervision using a state-of-the-art lip-to-text network that instills language information into our model. The noisy text is generated using a pre-trained lip-to-text model, enabling our approach to work without text annotations during inference. We design a visual text-to-speech network that utilizes the visual stream to generate accurate speech, which is in-sync with the silent input video. We perform extensive experiments and ablation studies, demonstrating our approach's superiority over the current state-of-the-art methods on various benchmark datasets. Further, we demonstrate an essential practical application of our method in assistive technology by generating speech for an ALS patient who has lost the voice but can make mouth movements. Our demo video, code, and additional details can be found at \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/ms-l2s-itw}.
* 8 pages of content, 1 page of references and 4 figures
Dubbing for Everyone: Data-Efficient Visual Dubbing using Neural Rendering Priors
Jan 11, 2024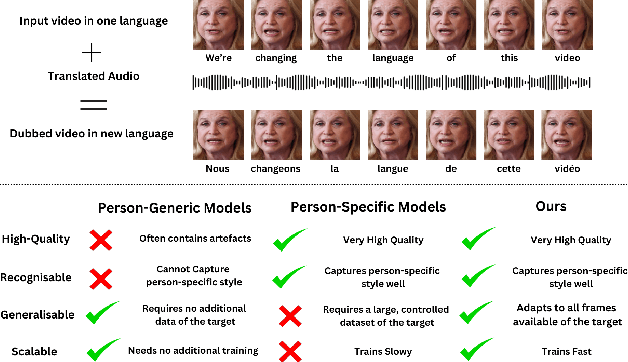



Visual dubbing is the process of generating lip motions of an actor in a video to synchronise with given audio. Recent advances have made progress towards this goal but have not been able to produce an approach suitable for mass adoption. Existing methods are split into either person-generic or person-specific models. Person-specific models produce results almost indistinguishable from reality but rely on long training times using large single-person datasets. Person-generic works have allowed for the visual dubbing of any video to any audio without further training, but these fail to capture the person-specific nuances and often suffer from visual artefacts. Our method, based on data-efficient neural rendering priors, overcomes the limitations of existing approaches. Our pipeline consists of learning a deferred neural rendering prior network and actor-specific adaptation using neural textures. This method allows for $\textbf{high-quality visual dubbing with just a few seconds of data}$, that enables video dubbing for any actor - from A-list celebrities to background actors. We show that we achieve state-of-the-art in terms of $\textbf{visual quality}$ and $\textbf{recognisability}$ both quantitatively, and qualitatively through two user studies. Our prior learning and adaptation method $\textbf{generalises to limited data}$ better and is more $\textbf{scalable}$ than existing person-specific models. Our experiments on real-world, limited data scenarios find that our model is preferred over all others. The project page may be found at https://dubbingforeveryone.github.io/
FACTS: Facial Animation Creation using the Transfer of Styles
Jul 18, 2023



The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
READ Avatars: Realistic Emotion-controllable Audio Driven Avatars
Mar 01, 2023We present READ Avatars, a 3D-based approach for generating 2D avatars that are driven by audio input with direct and granular control over the emotion. Previous methods are unable to achieve realistic animation due to the many-to-many nature of audio to expression mappings. We alleviate this issue by introducing an adversarial loss in the audio-to-expression generation process. This removes the smoothing effect of regression-based models and helps to improve the realism and expressiveness of the generated avatars. We note furthermore, that audio should be directly utilized when generating mouth interiors and that other 3D-based methods do not attempt this. We address this with audio-conditioned neural textures, which are resolution-independent. To evaluate the performance of our method, we perform quantitative and qualitative experiments, including a user study. We also propose a new metric for comparing how well an actor's emotion is reconstructed in the generated avatar. Our results show that our approach outperforms state of the art audio-driven avatar generation methods across several metrics. A demo video can be found at \url{https://youtu.be/QSyMl3vV0pA}
Audio-Visual Face Reenactment
Oct 06, 2022
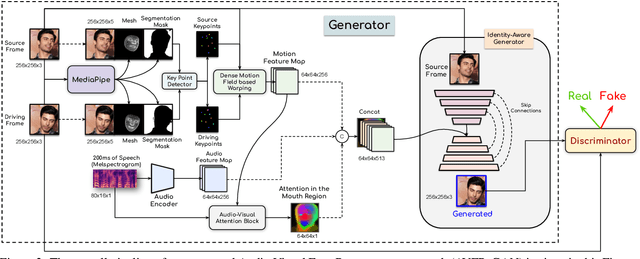


This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.