 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting
Dec 11, 2025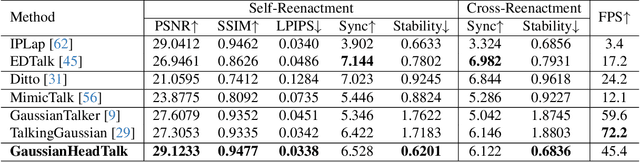
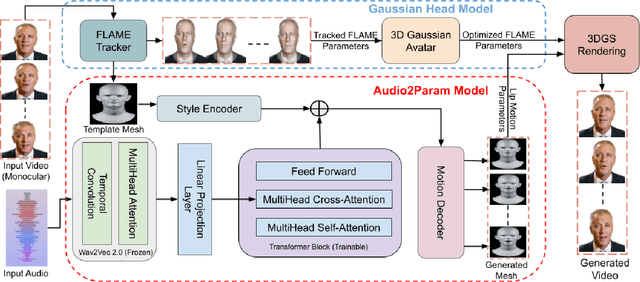
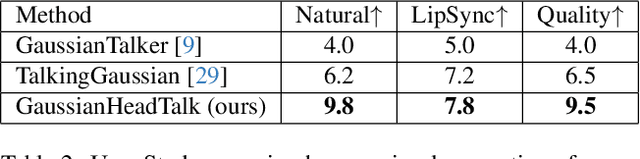

Speech-driven talking heads have recently emerged and enable interactive avatars. However, real-world applications are limited, as current methods achieve high visual fidelity but slow or fast yet temporally unstable. Diffusion methods provide realistic image generation, yet struggle with oneshot settings. Gaussian Splatting approaches are real-time, yet inaccuracies in facial tracking, or inconsistent Gaussian mappings, lead to unstable outputs and video artifacts that are detrimental to realistic use cases. We address this problem by mapping Gaussian Splatting using 3D Morphable Models to generate person-specific avatars. We introduce transformer-based prediction of model parameters, directly from audio, to drive temporal consistency. From monocular video and independent audio speech inputs, our method enables generation of real-time talking head videos where we report competitive quantitative and qualitative performance.
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022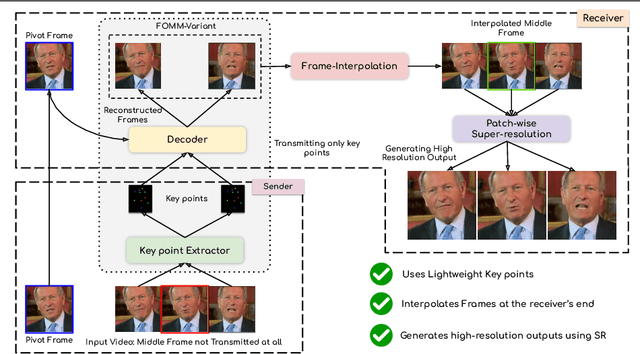
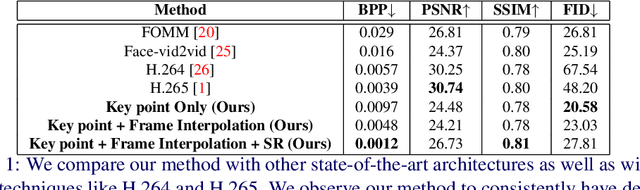
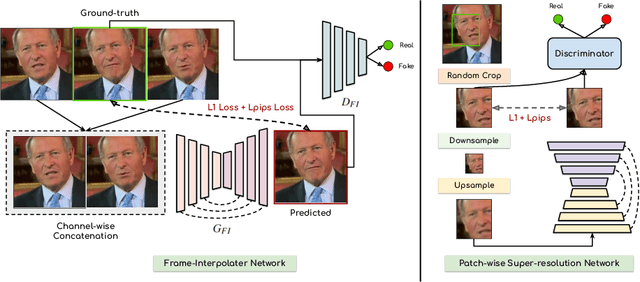
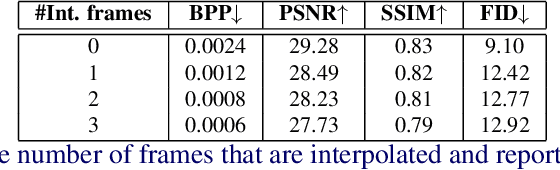
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
Audio-Visual Face Reenactment
Oct 06, 2022
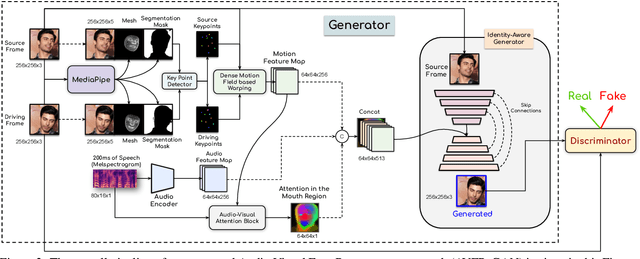


This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.
Making AI 'Smart': Bridging AI and Cognitive Science
Dec 31, 2021The last two decades have seen tremendous advances in Artificial Intelligence. The exponential growth in terms of computation capabilities has given us hope of developing humans like robots. The question is: are we there yet? Maybe not. With the integration of cognitive science, the 'artificial' characteristic of Artificial Intelligence (AI) might soon be replaced with 'smart'. This will help develop more powerful AI systems and simultaneously gives us a better understanding of how the human brain works. We discuss the various possibilities and challenges of bridging these two fields and how they can benefit each other. We argue that the possibility of AI taking over human civilization is low as developing such an advanced system requires a better understanding of the human brain first.
CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images
Aug 25, 2020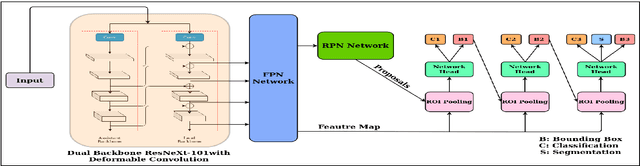
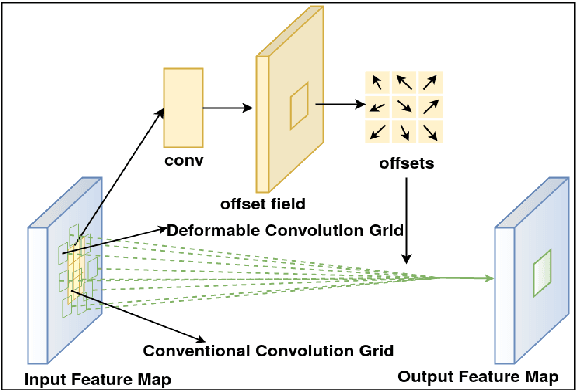

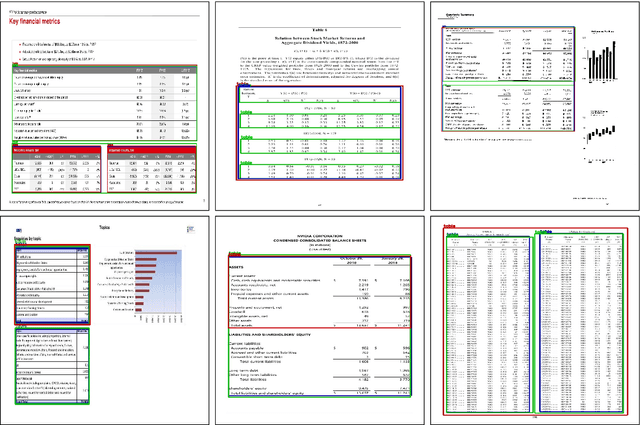
Localizing page elements/objects such as tables, figures, equations, etc. is the primary step in extracting information from document images. We propose a novel end-to-end trainable deep network, (CDeC-Net) for detecting tables present in the documents. The proposed network consists of a multistage extension of Mask R-CNN with a dual backbone having deformable convolution for detecting tables varying in scale with high detection accuracy at higher IoU threshold. We empirically evaluate CDeC-Net on all the publicly available benchmark datasets - ICDAR-2013, ICDAR-2017, ICDAR-2019,UNLV, Marmot, PubLayNet, and TableBank - with extensive experiments. Our solution has three important properties: (i) a single trained model CDeC-Net{\ddag} performs well across all the popular benchmark datasets; (ii) we report excellent performances across multiple, including higher, thresholds of IoU; (iii) by following the same protocol of the recent papers for each of the benchmarks, we consistently demonstrate the superior quantitative performance. Our code and models will be publicly released for enabling the reproducibility of the results.