 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards MOOCs for Lip Reading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Paper and Code
Aug 21, 2022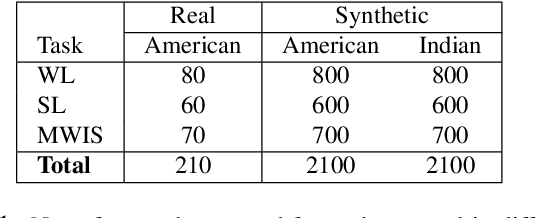
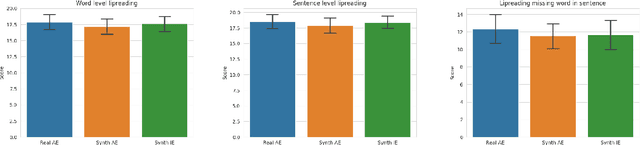
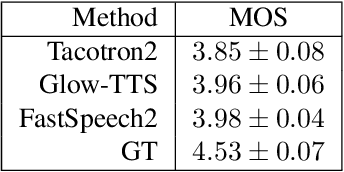

Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in COVID$19$ pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many kinds of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in the vocabulary, supported languages, accents, and speakers, and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can be used to easily incorporate larger vocabularies, variations in accent, and even local languages, and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking heading video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading exercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point towards the potential of our approach for the development of a large-scale lipreading MOOCs platform that can impact millions of people with hearing loss.