 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Sentinel: An AI Pipeline For Real-time Disease Outbreak Detection
Jun 24, 2025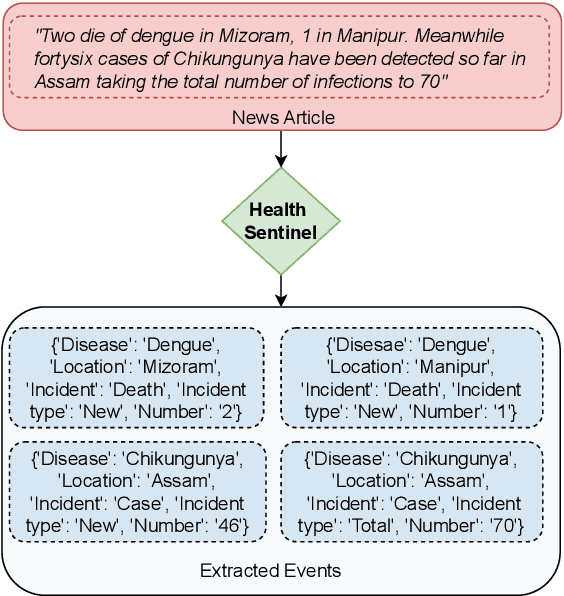
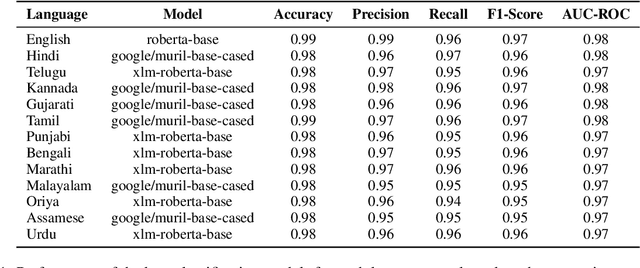
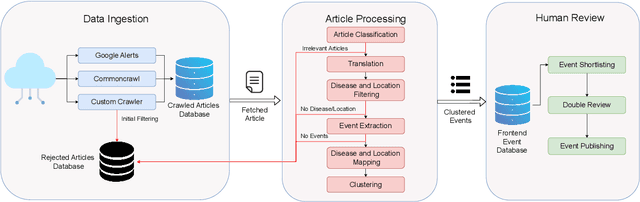
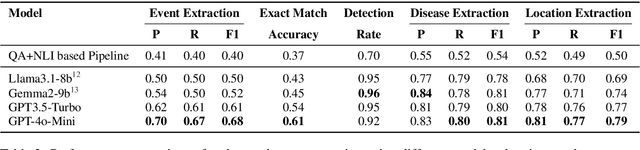
Early detection of disease outbreaks is crucial to ensure timely intervention by the health authorities. Due to the challenges associated with traditional indicator-based surveillance, monitoring informal sources such as online media has become increasingly popular. However, owing to the number of online articles getting published everyday, manual screening of the articles is impractical. To address this, we propose Health Sentinel. It is a multi-stage information extraction pipeline that uses a combination of ML and non-ML methods to extract events-structured information concerning disease outbreaks or other unusual health events-from online articles. The extracted events are made available to the Media Scanning and Verification Cell (MSVC) at the National Centre for Disease Control (NCDC), Delhi for analysis, interpretation and further dissemination to local agencies for timely intervention. From April 2022 till date, Health Sentinel has processed over 300 million news articles and identified over 95,000 unique health events across India of which over 3,500 events were shortlisted by the public health experts at NCDC as potential outbreaks.
Understanding Video Scenes through Text: Insights from Text-based Video Question Answering
Sep 11, 2023



Researchers have extensively studied the field of vision and language, discovering that both visual and textual content is crucial for understanding scenes effectively. Particularly, comprehending text in videos holds great significance, requiring both scene text understanding and temporal reasoning. This paper focuses on exploring two recently introduced datasets, NewsVideoQA and M4-ViteVQA, which aim to address video question answering based on textual content. The NewsVideoQA dataset contains question-answer pairs related to the text in news videos, while M4-ViteVQA comprises question-answer pairs from diverse categories like vlogging, traveling, and shopping. We provide an analysis of the formulation of these datasets on various levels, exploring the degree of visual understanding and multi-frame comprehension required for answering the questions. Additionally, the study includes experimentation with BERT-QA, a text-only model, which demonstrates comparable performance to the original methods on both datasets, indicating the shortcomings in the formulation of these datasets. Furthermore, we also look into the domain adaptation aspect by examining the effectiveness of training on M4-ViteVQA and evaluating on NewsVideoQA and vice-versa, thereby shedding light on the challenges and potential benefits of out-of-domain training.
Reading Between the Lanes: Text VideoQA on the Road
Jul 08, 2023Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness. Scene text recognition in motion is a challenging problem, while textual cues typically appear for a short time span, and early detection at a distance is necessary. Systems that exploit such information to assist the driver should not only extract and incorporate visual and textual cues from the video stream but also reason over time. To address this issue, we introduce RoadTextVQA, a new dataset for the task of video question answering (VideoQA) in the context of driver assistance. RoadTextVQA consists of $3,222$ driving videos collected from multiple countries, annotated with $10,500$ questions, all based on text or road signs present in the driving videos. We assess the performance of state-of-the-art video question answering models on our RoadTextVQA dataset, highlighting the significant potential for improvement in this domain and the usefulness of the dataset in advancing research on in-vehicle support systems and text-aware multimodal question answering. The dataset is available at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtextvqa
Watching the News: Towards VideoQA Models that can Read
Nov 10, 2022



Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisation cues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the ``NewsVideoQA'' dataset that comprises more than $8,600$ QA pairs on $3,000+$ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.
An empirical study of CTC based models for OCR of Indian languages
May 13, 2022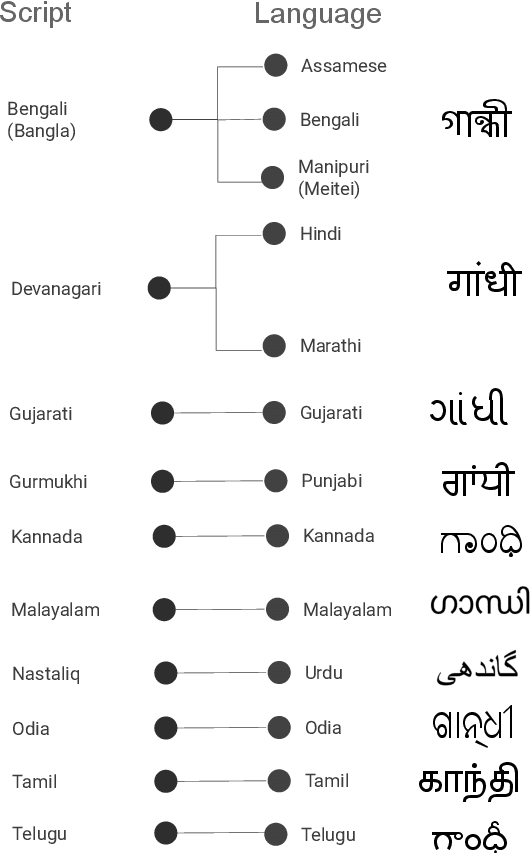
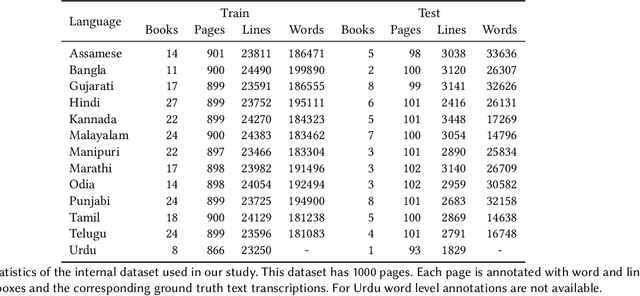
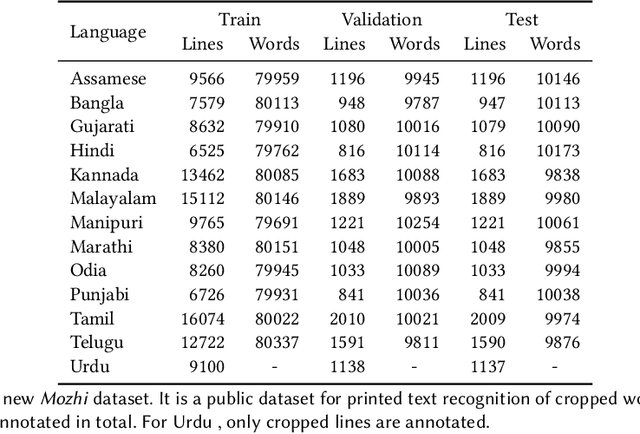

Recognition of text on word or line images, without the need for sub-word segmentation has become the mainstream of research and development of text recognition for Indian languages. Modelling unsegmented sequences using Connectionist Temporal Classification (CTC) is the most commonly used approach for segmentation-free OCR. In this work we present a comprehensive empirical study of various neural network models that uses CTC for transcribing step-wise predictions in the neural network output to a Unicode sequence. The study is conducted for 13 Indian languages, using an internal dataset that has around 1000 pages per language. We study the choice of line vs word as the recognition unit, and use of synthetic data to train the models. We compare our models with popular publicly available OCR tools for end-to-end document image recognition. Our end-to-end pipeline that employ our recognition models and existing text segmentation tools outperform these public OCR tools for 8 out of the 13 languages. We also introduce a new public dataset called Mozhi for word and line recognition in Indian language. The dataset contains more than 1.2 million annotated word images (120 thousand text lines) across 13 Indian languages. Our code, trained models and the Mozhi dataset will be made available at http://cvit.iiit.ac.in/research/projects/cvit-projects/
ICDAR 2021 Competition on Document VisualQuestion Answering
Nov 10, 2021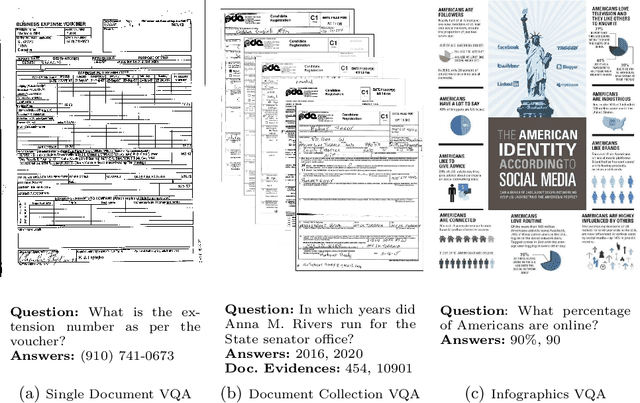
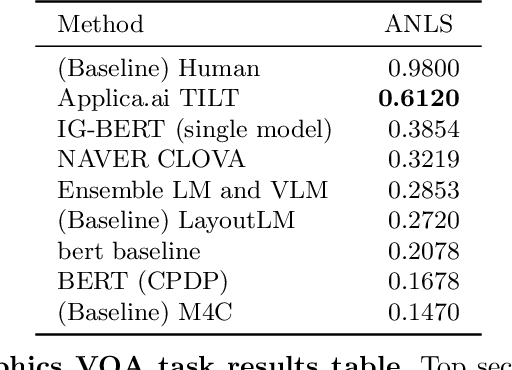
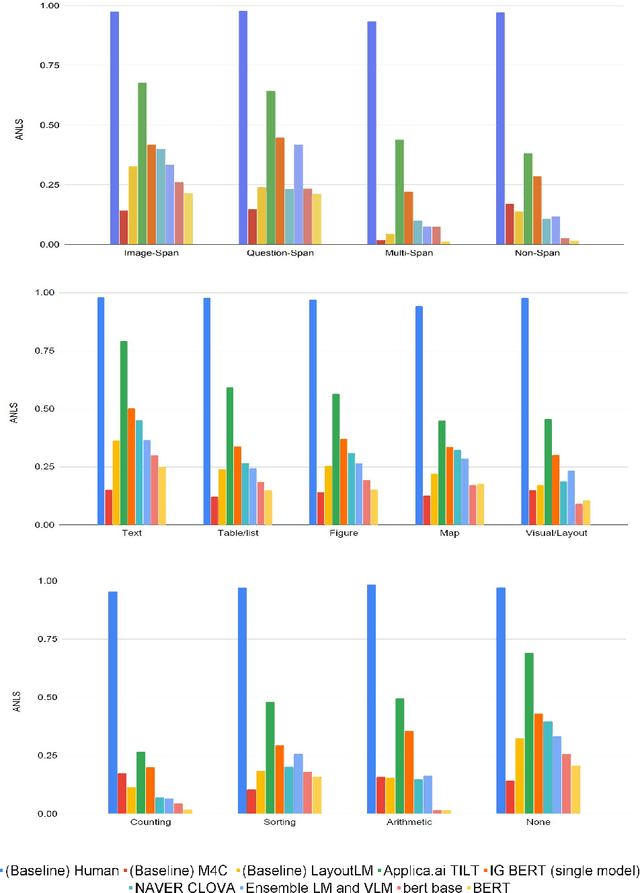
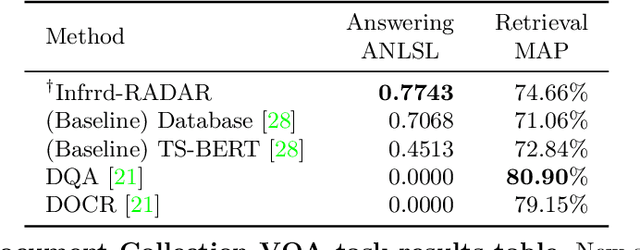
In this report we present results of the ICDAR 2021 edition of the Document Visual Question Challenges. This edition complements the previous tasks on Single Document VQA and Document Collection VQA with a newly introduced on Infographics VQA. Infographics VQA is based on a new dataset of more than 5,000 infographics images and 30,000 question-answer pairs. The winner methods have scored 0.6120 ANLS in Infographics VQA task, 0.7743 ANLSL in Document Collection VQA task and 0.8705 ANLS in Single Document VQA. We present a summary of the datasets used for each task, description of each of the submitted methods and the results and analysis of their performance. A summary of the progress made on Single Document VQA since the first edition of the DocVQA 2020 challenge is also presented.
Asking questions on handwritten document collections
Oct 02, 2021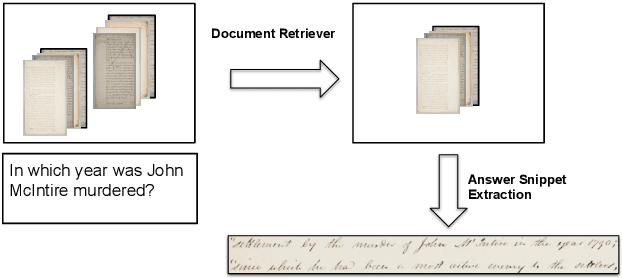

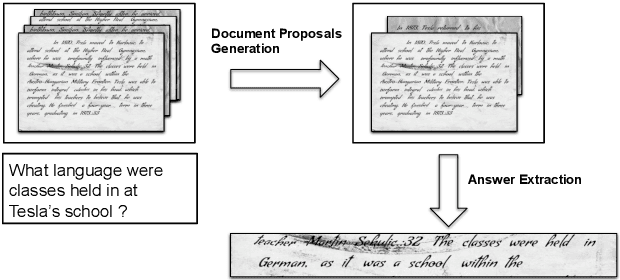

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
InfographicVQA
Apr 26, 2021
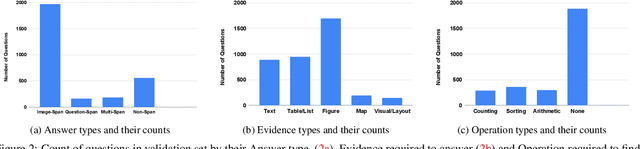
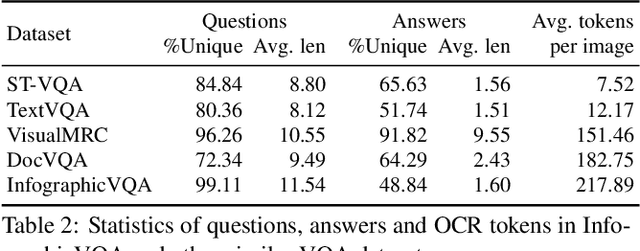
Infographics are documents designed to effectively communicate information using a combination of textual, graphical and visual elements. In this work, we explore the automatic understanding of infographic images by using Visual Question Answering technique.To this end, we present InfographicVQA, a new dataset that comprises a diverse collection of infographics along with natural language questions and answers annotations. The collected questions require methods to jointly reason over the document layout, textual content, graphical elements, and data visualizations. We curate the dataset with emphasis on questions that require elementary reasoning and basic arithmetic skills. Finally, we evaluate two strong baselines based on state of the art multi-modal VQA models, and establish baseline performance for the new task. The dataset, code and leaderboard will be made available at http://docvqa.org
Benchmarking Scene Text Recognition in Devanagari, Telugu and Malayalam
Apr 09, 2021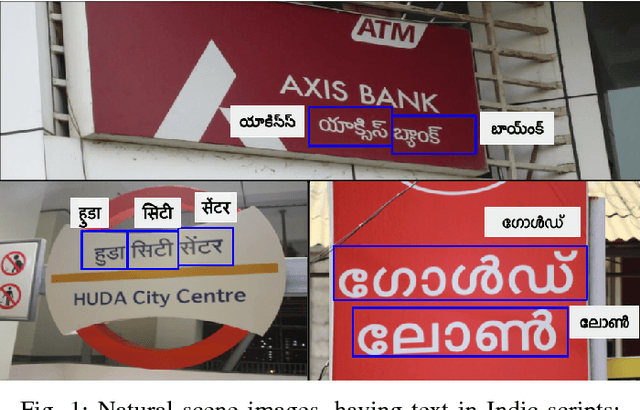
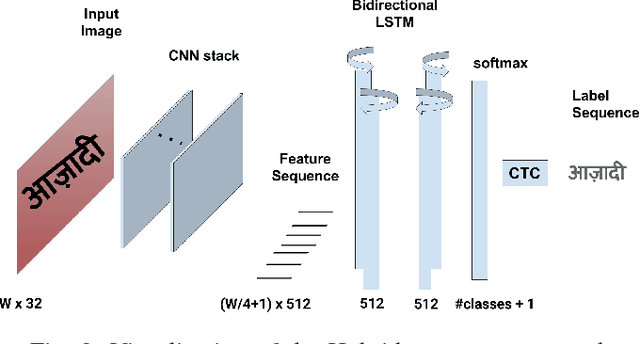


Inspired by the success of Deep Learning based approaches to English scene text recognition, we pose and benchmark scene text recognition for three Indic scripts - Devanagari, Telugu and Malayalam. Synthetic word images rendered from Unicode fonts are used for training the recognition system. And the performance is bench-marked on a new IIIT-ILST dataset comprising of hundreds of real scene images containing text in the above mentioned scripts. We use a segmentation free, hybrid but end-to-end trainable CNN-RNN deep neural network for transcribing the word images to the corresponding texts. The cropped word images need not be segmented into the sub-word units and the error is calculated and backpropagated for the the given word image at once. The network is trained using CTC loss, which is proven quite effective for sequence-to-sequence transcription tasks. The CNN layers in the network learn to extract robust feature representations from word images. The sequence of features learnt by the convolutional block is transcribed to a sequence of labels by the RNN+CTC block. The transcription is not bound by word length or a lexicon and is ideal for Indian languages which are highly inflectional. IIIT-ILST dataset, synthetic word images dataset and the script used to render synthetic images are available at http://cvit.iiit.ac.in/research/projects/cvit-projects/iiit-ilst
MMBERT: Multimodal BERT Pretraining for Improved Medical VQA
Apr 03, 2021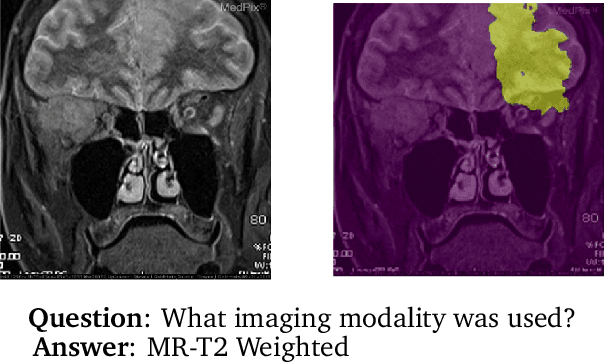

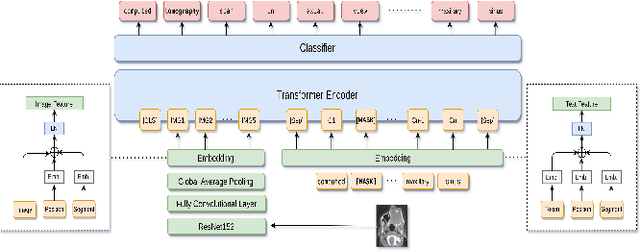
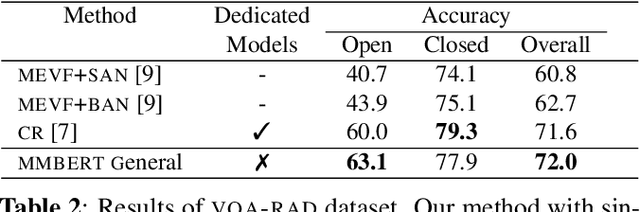
Images in the medical domain are fundamentally different from the general domain images. Consequently, it is infeasible to directly employ general domain Visual Question Answering (VQA) models for the medical domain. Additionally, medical images annotation is a costly and time-consuming process. To overcome these limitations, we propose a solution inspired by self-supervised pretraining of Transformer-style architectures for NLP, Vision and Language tasks. Our method involves learning richer medical image and text semantic representations using Masked Language Modeling (MLM) with image features as the pretext task on a large medical image+caption dataset. The proposed solution achieves new state-of-the-art performance on two VQA datasets for radiology images -- VQA-Med 2019 and VQA-RAD, outperforming even the ensemble models of previous best solutions. Moreover, our solution provides attention maps which help in model interpretability. The code is available at https://github.com/VirajBagal/MMBERT