 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical study of CTC based models for OCR of Indian languages
May 13, 2022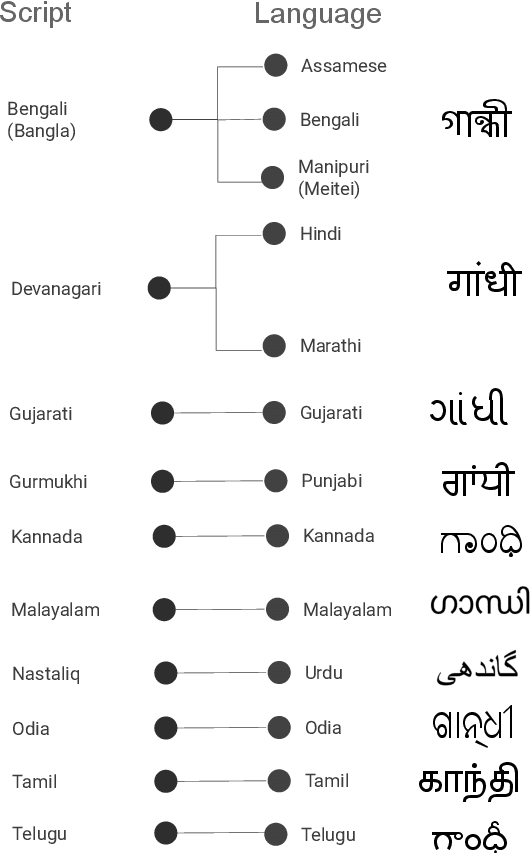
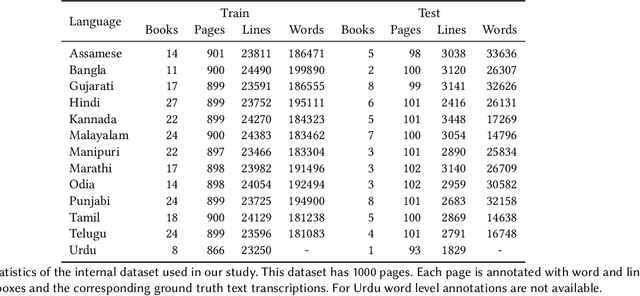
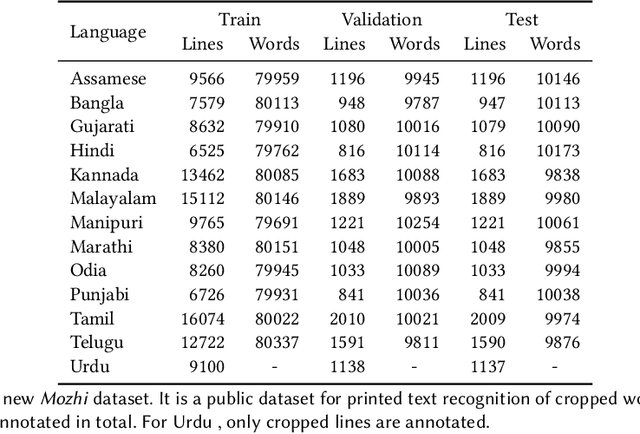

Recognition of text on word or line images, without the need for sub-word segmentation has become the mainstream of research and development of text recognition for Indian languages. Modelling unsegmented sequences using Connectionist Temporal Classification (CTC) is the most commonly used approach for segmentation-free OCR. In this work we present a comprehensive empirical study of various neural network models that uses CTC for transcribing step-wise predictions in the neural network output to a Unicode sequence. The study is conducted for 13 Indian languages, using an internal dataset that has around 1000 pages per language. We study the choice of line vs word as the recognition unit, and use of synthetic data to train the models. We compare our models with popular publicly available OCR tools for end-to-end document image recognition. Our end-to-end pipeline that employ our recognition models and existing text segmentation tools outperform these public OCR tools for 8 out of the 13 languages. We also introduce a new public dataset called Mozhi for word and line recognition in Indian language. The dataset contains more than 1.2 million annotated word images (120 thousand text lines) across 13 Indian languages. Our code, trained models and the Mozhi dataset will be made available at http://cvit.iiit.ac.in/research/projects/cvit-projects/
Classification of histopathology images using ConvNets to detect Lupus Nephritis
Dec 14, 2021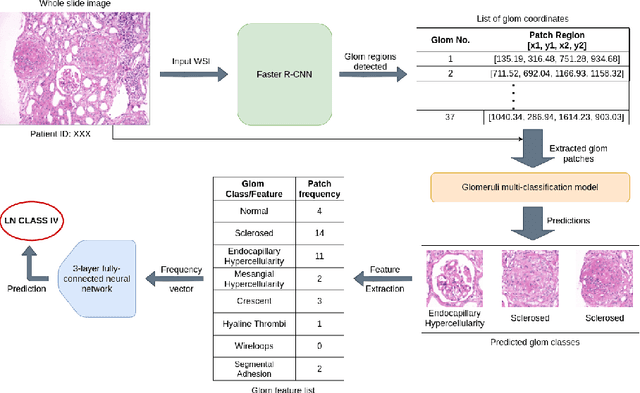
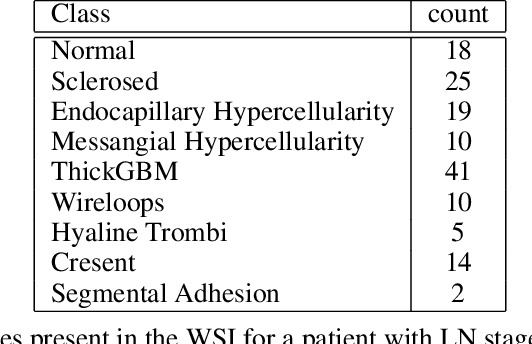
Systemic lupus erythematosus (SLE) is an autoimmune disease in which the immune system of the patient starts attacking healthy tissues of the body. Lupus Nephritis (LN) refers to the inflammation of kidney tissues resulting in renal failure due to these attacks. The International Society of Nephrology/Renal Pathology Society (ISN/RPS) has released a classification system based on various patterns observed during renal injury in SLE. Traditional methods require meticulous pathological assessment of the renal biopsy and are time-consuming. Recently, computational techniques have helped to alleviate this issue by using virtual microscopy or Whole Slide Imaging (WSI). With the use of deep learning and modern computer vision techniques, we propose a pipeline that is able to automate the process of 1) detection of various glomeruli patterns present in these whole slide images and 2) classification of each image using the extracted glomeruli features.
Asking questions on handwritten document collections
Oct 02, 2021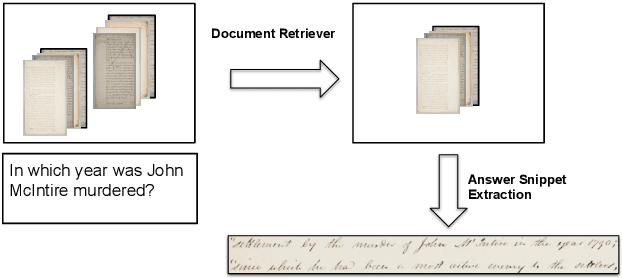

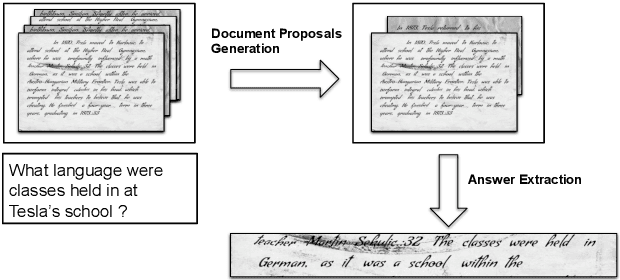

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
Benchmarking Scene Text Recognition in Devanagari, Telugu and Malayalam
Apr 09, 2021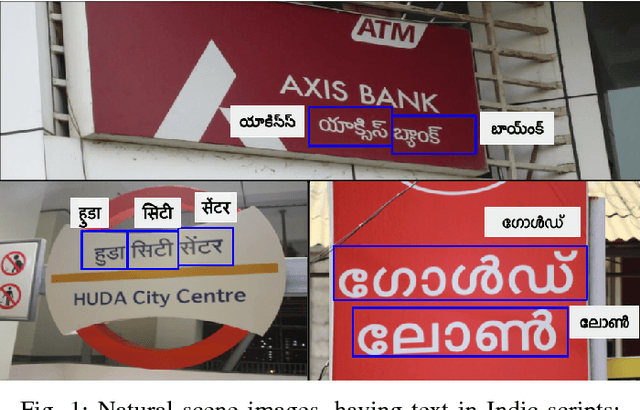
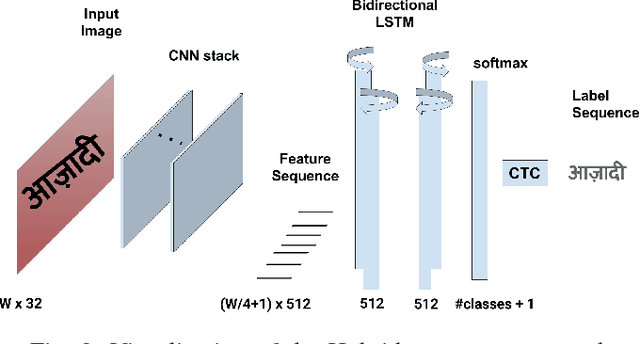


Inspired by the success of Deep Learning based approaches to English scene text recognition, we pose and benchmark scene text recognition for three Indic scripts - Devanagari, Telugu and Malayalam. Synthetic word images rendered from Unicode fonts are used for training the recognition system. And the performance is bench-marked on a new IIIT-ILST dataset comprising of hundreds of real scene images containing text in the above mentioned scripts. We use a segmentation free, hybrid but end-to-end trainable CNN-RNN deep neural network for transcribing the word images to the corresponding texts. The cropped word images need not be segmented into the sub-word units and the error is calculated and backpropagated for the the given word image at once. The network is trained using CTC loss, which is proven quite effective for sequence-to-sequence transcription tasks. The CNN layers in the network learn to extract robust feature representations from word images. The sequence of features learnt by the convolutional block is transcribed to a sequence of labels by the RNN+CTC block. The transcription is not bound by word length or a lexicon and is ideal for Indian languages which are highly inflectional. IIIT-ILST dataset, synthetic word images dataset and the script used to render synthetic images are available at http://cvit.iiit.ac.in/research/projects/cvit-projects/iiit-ilst
MMBERT: Multimodal BERT Pretraining for Improved Medical VQA
Apr 03, 2021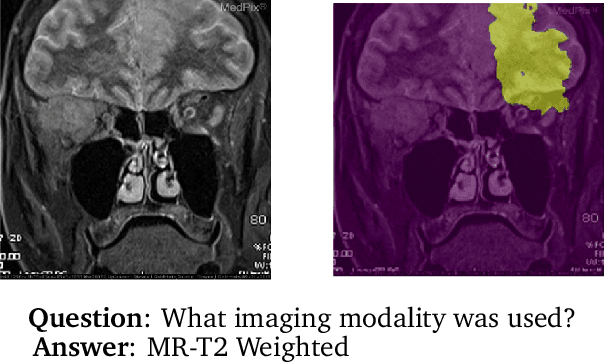

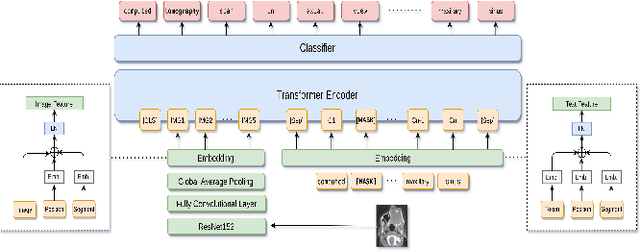
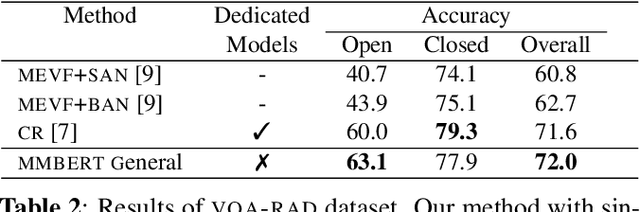
Images in the medical domain are fundamentally different from the general domain images. Consequently, it is infeasible to directly employ general domain Visual Question Answering (VQA) models for the medical domain. Additionally, medical images annotation is a costly and time-consuming process. To overcome these limitations, we propose a solution inspired by self-supervised pretraining of Transformer-style architectures for NLP, Vision and Language tasks. Our method involves learning richer medical image and text semantic representations using Masked Language Modeling (MLM) with image features as the pretext task on a large medical image+caption dataset. The proposed solution achieves new state-of-the-art performance on two VQA datasets for radiology images -- VQA-Med 2019 and VQA-RAD, outperforming even the ensemble models of previous best solutions. Moreover, our solution provides attention maps which help in model interpretability. The code is available at https://github.com/VirajBagal/MMBERT
Exploring Genetic-histologic Relationships in Breast Cancer
Mar 15, 2021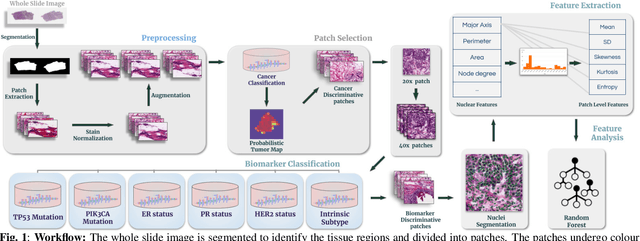
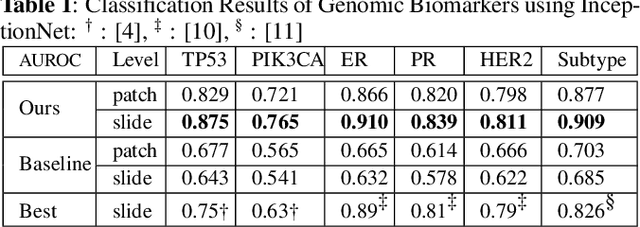
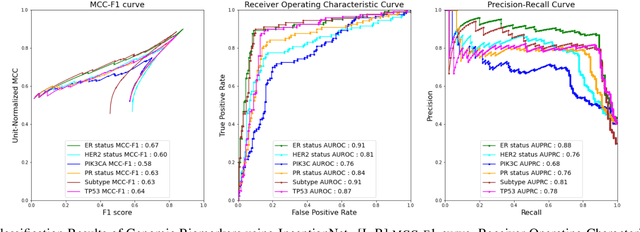
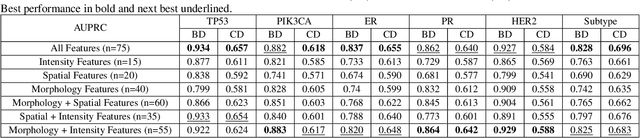
The advent of digital pathology presents opportunities for computer vision for fast, accurate, and objective solutions for histopathological images and aid in knowledge discovery. This work uses deep learning to predict genomic biomarkers - TP53 mutation, PIK3CA mutation, ER status, PR status, HER2 status, and intrinsic subtypes, from breast cancer histopathology images. Furthermore, we attempt to understand the underlying morphology as to how these genomic biomarkers manifest in images. Since gene sequencing is expensive, not always available, or even feasible, predicting these biomarkers from images would help in diagnosis, prognosis, and effective treatment planning. We outperform the existing works with a minimum improvement of 0.02 and a maximum of 0.13 AUROC scores across all tasks. We also gain insights that can serve as hypotheses for further experimentations, including the presence of lymphocytes and karyorrhexis. Moreover, our fully automated workflow can be extended to other tasks across other cancer subtypes.
Fine-Grain Annotation of Cricket Videos
Sep 27, 2017


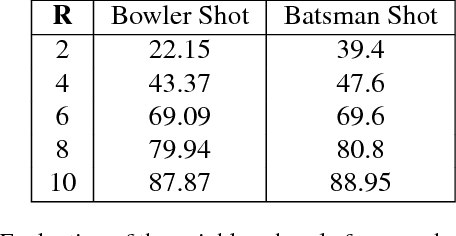
The recognition of human activities is one of the key problems in video understanding. Action recognition is challenging even for specific categories of videos, such as sports, that contain only a small set of actions. Interestingly, sports videos are accompanied by detailed commentaries available online, which could be used to perform action annotation in a weakly-supervised setting. For the specific case of Cricket videos, we address the challenge of temporal segmentation and annotation of ctions with semantic descriptions. Our solution consists of two stages. In the first stage, the video is segmented into "scenes", by utilizing the scene category information extracted from text-commentary. The second stage consists of classifying video-shots as well as the phrases in the textual description into various categories. The relevant phrases are then suitably mapped to the video-shots. The novel aspect of this work is the fine temporal scale at which semantic information is assigned to the video. As a result of our approach, we enable retrieval of specific actions that last only a few seconds, from several hours of video. This solution yields a large number of labeled exemplars, with no manual effort, that could be used by machine learning algorithms to learn complex actions.