 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfographicVQA
Apr 26, 2021
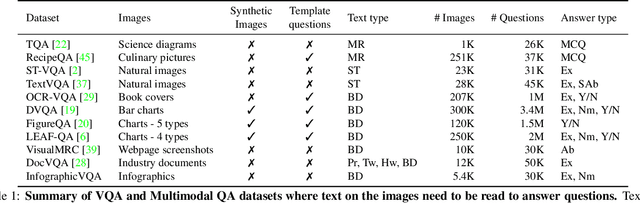
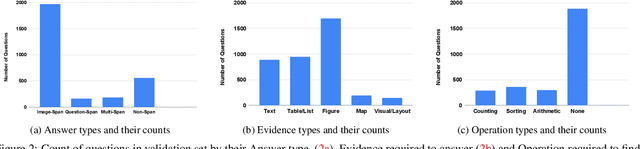
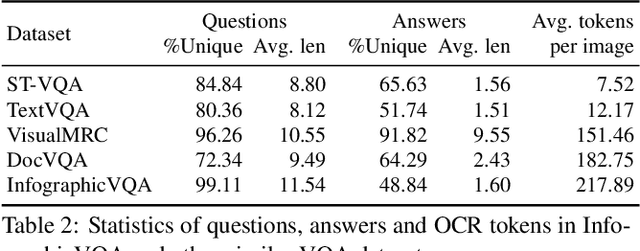
Infographics are documents designed to effectively communicate information using a combination of textual, graphical and visual elements. In this work, we explore the automatic understanding of infographic images by using Visual Question Answering technique.To this end, we present InfographicVQA, a new dataset that comprises a diverse collection of infographics along with natural language questions and answers annotations. The collected questions require methods to jointly reason over the document layout, textual content, graphical elements, and data visualizations. We curate the dataset with emphasis on questions that require elementary reasoning and basic arithmetic skills. Finally, we evaluate two strong baselines based on state of the art multi-modal VQA models, and establish baseline performance for the new task. The dataset, code and leaderboard will be made available at http://docvqa.org
MMBERT: Multimodal BERT Pretraining for Improved Medical VQA
Apr 03, 2021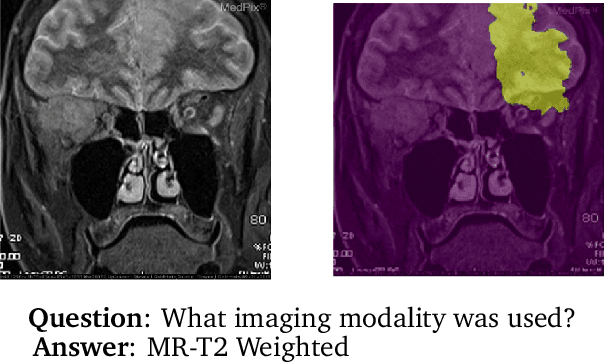

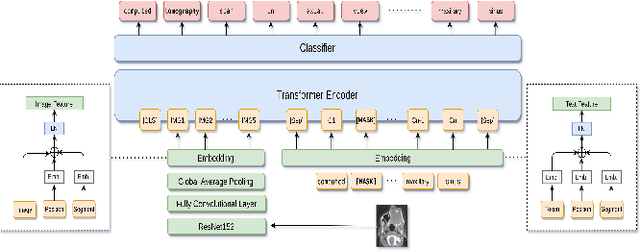
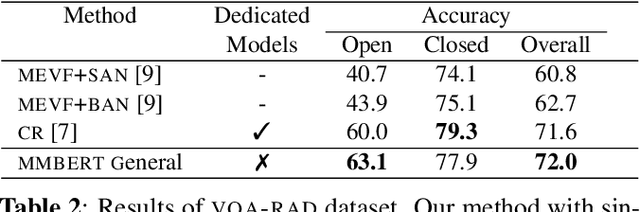
Images in the medical domain are fundamentally different from the general domain images. Consequently, it is infeasible to directly employ general domain Visual Question Answering (VQA) models for the medical domain. Additionally, medical images annotation is a costly and time-consuming process. To overcome these limitations, we propose a solution inspired by self-supervised pretraining of Transformer-style architectures for NLP, Vision and Language tasks. Our method involves learning richer medical image and text semantic representations using Masked Language Modeling (MLM) with image features as the pretext task on a large medical image+caption dataset. The proposed solution achieves new state-of-the-art performance on two VQA datasets for radiology images -- VQA-Med 2019 and VQA-RAD, outperforming even the ensemble models of previous best solutions. Moreover, our solution provides attention maps which help in model interpretability. The code is available at https://github.com/VirajBagal/MMBERT