 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Scene Text Recognition in Devanagari, Telugu and Malayalam
Paper and Code
Apr 09, 2021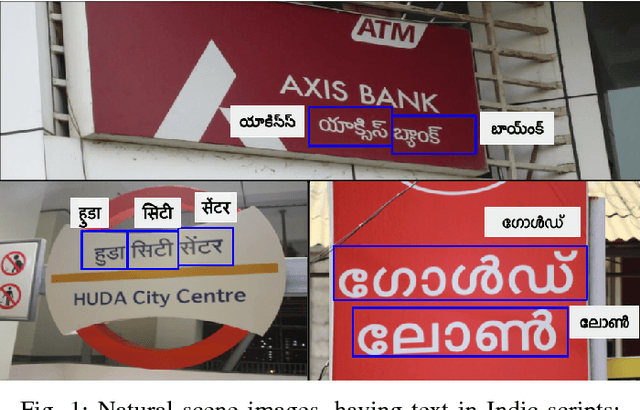
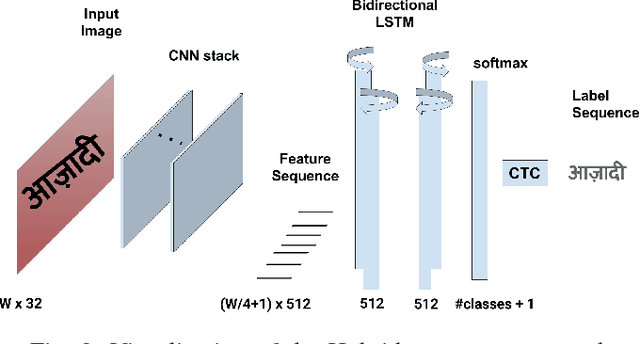


Inspired by the success of Deep Learning based approaches to English scene text recognition, we pose and benchmark scene text recognition for three Indic scripts - Devanagari, Telugu and Malayalam. Synthetic word images rendered from Unicode fonts are used for training the recognition system. And the performance is bench-marked on a new IIIT-ILST dataset comprising of hundreds of real scene images containing text in the above mentioned scripts. We use a segmentation free, hybrid but end-to-end trainable CNN-RNN deep neural network for transcribing the word images to the corresponding texts. The cropped word images need not be segmented into the sub-word units and the error is calculated and backpropagated for the the given word image at once. The network is trained using CTC loss, which is proven quite effective for sequence-to-sequence transcription tasks. The CNN layers in the network learn to extract robust feature representations from word images. The sequence of features learnt by the convolutional block is transcribed to a sequence of labels by the RNN+CTC block. The transcription is not bound by word length or a lexicon and is ideal for Indian languages which are highly inflectional. IIIT-ILST dataset, synthetic word images dataset and the script used to render synthetic images are available at http://cvit.iiit.ac.in/research/projects/cvit-projects/iiit-ilst