 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cost Efficient Approach to Correct OCR Errors in Large Document Collections
Paper and Code
May 28, 2019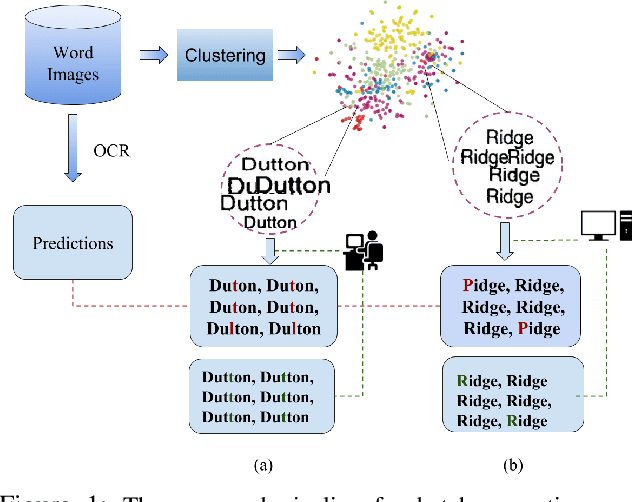


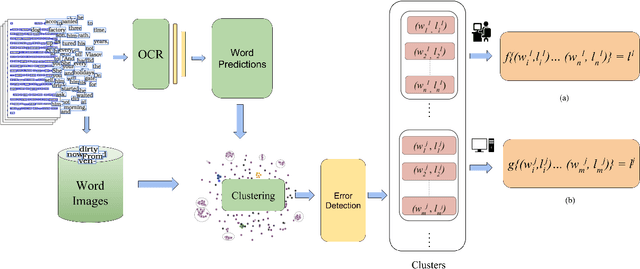
Word error rate of an ocr is often higher than its character error rate. This is especially true when ocrs are designed by recognizing characters. High word accuracies are critical to tasks like the creation of content in digital libraries and text-to-speech applications. In order to detect and correct the misrecognised words, it is common for an ocr module to employ a post-processor to further improve the word accuracy. However, conventional approaches to post-processing like looking up a dictionary or using a statistical language model (slm), are still limited. In many such scenarios, it is often required to remove the outstanding errors manually. We observe that the traditional post-processing schemes look at error words sequentially since ocrs process documents one at a time. We propose a cost-efficient model to address the error words in batches rather than correcting them individually. We exploit the fact that a collection of documents, unlike a single document, has a structure leading to repetition of words. Such words, if efficiently grouped together and corrected as a whole can lead to a significant reduction in the cost. Correction can be fully automatic or with a human in the loop. Towards this, we employ a novel clustering scheme to obtain fairly homogeneous clusters. We compare the performance of our model with various baseline approaches including the case where all the errors are removed by a human. We demonstrate the efficacy of our solution empirically by reporting more than 70% reduction in the human effort with near perfect error correction. We validate our method on Books from multiple languages.