 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUST: Leveraging Text Robustness for Unsupervised Domain Adaptation
Aug 08, 2025Recent unsupervised domain adaptation (UDA) methods have shown great success in addressing classical domain shifts (e.g., synthetic-to-real), but they still suffer under complex shifts (e.g. geographical shift), where both the background and object appearances differ significantly across domains. Prior works showed that the language modality can help in the adaptation process, exhibiting more robustness to such complex shifts. In this paper, we introduce TRUST, a novel UDA approach that exploits the robustness of the language modality to guide the adaptation of a vision model. TRUST generates pseudo-labels for target samples from their captions and introduces a novel uncertainty estimation strategy that uses normalised CLIP similarity scores to estimate the uncertainty of the generated pseudo-labels. Such estimated uncertainty is then used to reweight the classification loss, mitigating the adverse effects of wrong pseudo-labels obtained from low-quality captions. To further increase the robustness of the vision model, we propose a multimodal soft-contrastive learning loss that aligns the vision and language feature spaces, by leveraging captions to guide the contrastive training of the vision model on target images. In our contrastive loss, each pair of images acts as both a positive and a negative pair and their feature representations are attracted and repulsed with a strength proportional to the similarity of their captions. This solution avoids the need for hardly determining positive and negative pairs, which is critical in the UDA setting. Our approach outperforms previous methods, setting the new state-of-the-art on classical (DomainNet) and complex (GeoNet) domain shifts. The code will be available upon acceptance.
PhenoAssistant: A Conversational Multi-Agent AI System for Automated Plant Phenotyping
Apr 28, 2025Plant phenotyping increasingly relies on (semi-)automated image-based analysis workflows to improve its accuracy and scalability. However, many existing solutions remain overly complex, difficult to reimplement and maintain, and pose high barriers for users without substantial computational expertise. To address these challenges, we introduce PhenoAssistant: a pioneering AI-driven system that streamlines plant phenotyping via intuitive natural language interaction. PhenoAssistant leverages a large language model to orchestrate a curated toolkit supporting tasks including automated phenotype extraction, data visualisation and automated model training. We validate PhenoAssistant through several representative case studies and a set of evaluation tasks. By significantly lowering technical hurdles, PhenoAssistant underscores the promise of AI-driven methodologies to democratising AI adoption in plant biology.
GMT: Guided Mask Transformer for Leaf Instance Segmentation
Jun 24, 2024



Leaf instance segmentation is a challenging multi-instance segmentation task, aiming to separate and delineate each leaf in an image of a plant. The delineation of each leaf is a necessary prerequisite task for several biology-related applications such as the fine-grained monitoring of plant growth, and crop yield estimation. The task is challenging because self-similarity of instances is high (similar shape and colour) and instances vary greatly in size under heavy occulusion. We believe that the key to overcoming the aforementioned challenges lies in the specific spatial patterns of leaf distribution. For example, leaves typically grow around the plant's center, with smaller leaves clustering and overlapped near this central point. In this paper, we propose a novel approach named Guided Mask Transformer (GMT), which contains three key components, namely Guided Positional Encoding (GPE), Guided Embedding Fusion Module (GEFM) and Guided Dynamic Positional Queries (GDPQ), to extend the meta-architecture of Mask2Former and incorporate with a set of harmonic guide functions. These guide functions are tailored to the pixel positions of instances and trained to separate distinct instances in an embedding space. The proposed GMT consistently outperforms State-of-the-Art models on three public plant datasets.
Uncertainty-guided Open-Set Source-Free Unsupervised Domain Adaptation with Target-private Class Segregation
Apr 16, 2024Standard Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target but usually requires simultaneous access to both source and target data. Moreover, UDA approaches commonly assume that source and target domains share the same labels space. Yet, these two assumptions are hardly satisfied in real-world scenarios. This paper considers the more challenging Source-Free Open-set Domain Adaptation (SF-OSDA) setting, where both assumptions are dropped. We propose a novel approach for SF-OSDA that exploits the granularity of target-private categories by segregating their samples into multiple unknown classes. Starting from an initial clustering-based assignment, our method progressively improves the segregation of target-private samples by refining their pseudo-labels with the guide of an uncertainty-based sample selection module. Additionally, we propose a novel contrastive loss, named NL-InfoNCELoss, that, integrating negative learning into self-supervised contrastive learning, enhances the model robustness to noisy pseudo-labels. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed method over existing approaches, establishing new state-of-the-art performance. Notably, additional analyses show that our method is able to learn the underlying semantics of novel classes, opening the possibility to perform novel class discovery.
Synchronization is All You Need: Exocentric-to-Egocentric Transfer for Temporal Action Segmentation with Unlabeled Synchronized Video Pairs
Dec 05, 2023



We consider the problem of transferring a temporal action segmentation system initially designed for exocentric (fixed) cameras to an egocentric scenario, where wearable cameras capture video data. The conventional supervised approach requires the collection and labeling of a new set of egocentric videos to adapt the model, which is costly and time-consuming. Instead, we propose a novel methodology which performs the adaptation leveraging existing labeled exocentric videos and a new set of unlabeled, synchronized exocentric-egocentric video pairs, for which temporal action segmentation annotations do not need to be collected. We implement the proposed methodology with an approach based on knowledge distillation, which we investigate both at the feature and model level. To evaluate our approach, we introduce a new benchmark based on the Assembly101 dataset. Results demonstrate the feasibility and effectiveness of the proposed method against classic unsupervised domain adaptation and temporal sequence alignment approaches. Remarkably, without bells and whistles, our best model performs on par with supervised approaches trained on labeled egocentric data, without ever seeing a single egocentric label, achieving a +15.99% (28.59% vs 12.60%) improvement in the edit score on the Assembly101 dataset compared to a baseline model trained solely on exocentric data.
Transfer Learning via Test-Time Neural Networks Aggregation
Jun 27, 2022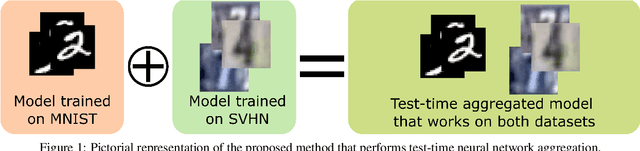
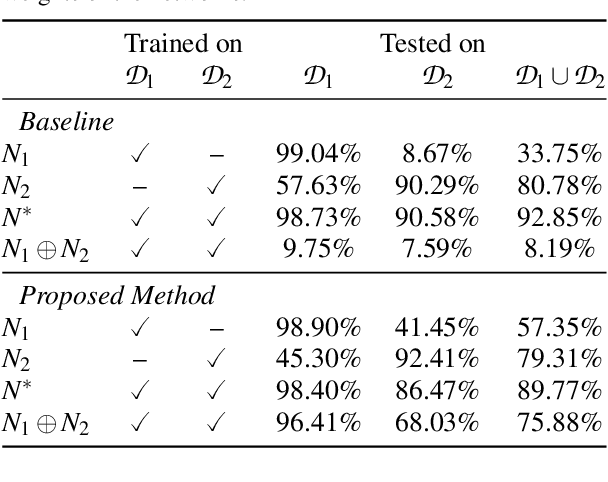
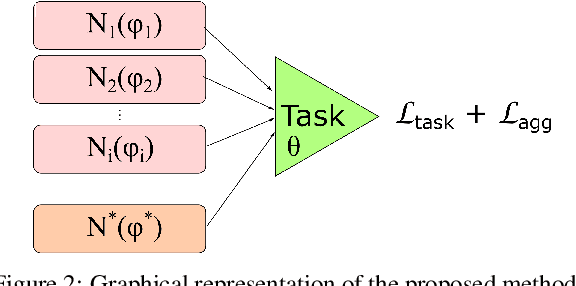
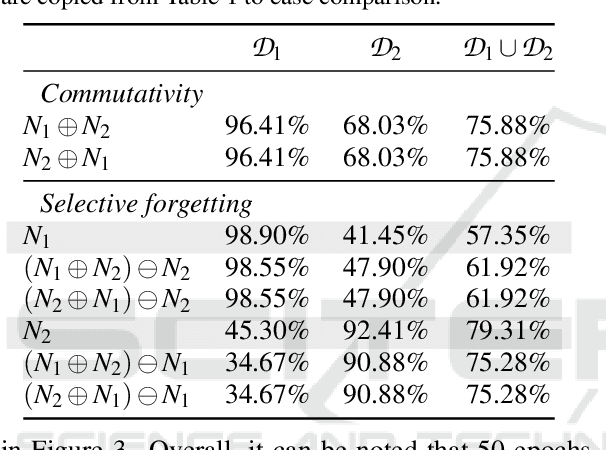
It has been demonstrated that deep neural networks outperform traditional machine learning. However, deep networks lack generalisability, that is, they will not perform as good as in a new (testing) set drawn from a different distribution due to the domain shift. In order to tackle this known issue, several transfer learning approaches have been proposed, where the knowledge of a trained model is transferred into another to improve performance with different data. However, most of these approaches require additional training steps, or they suffer from catastrophic forgetting that occurs when a trained model has overwritten previously learnt knowledge. We address both problems with a novel transfer learning approach that uses network aggregation. We train dataset-specific networks together with an aggregation network in a unified framework. The loss function includes two main components: a task-specific loss (such as cross-entropy) and an aggregation loss. The proposed aggregation loss allows our model to learn how trained deep network parameters can be aggregated with an aggregation operator. We demonstrate that the proposed approach learns model aggregation at test time without any further training step, reducing the burden of transfer learning to a simple arithmetical operation. The proposed approach achieves comparable performance w.r.t. the baseline. Besides, if the aggregation operator has an inverse, we will show that our model also inherently allows for selective forgetting, i.e., the aggregated model can forget one of the datasets it was trained on, retaining information on the others.
* 8 pages
Blind Inpainting of Large-scale Masks of Thin Structures with Adversarial and Reinforcement Learning
Dec 05, 2019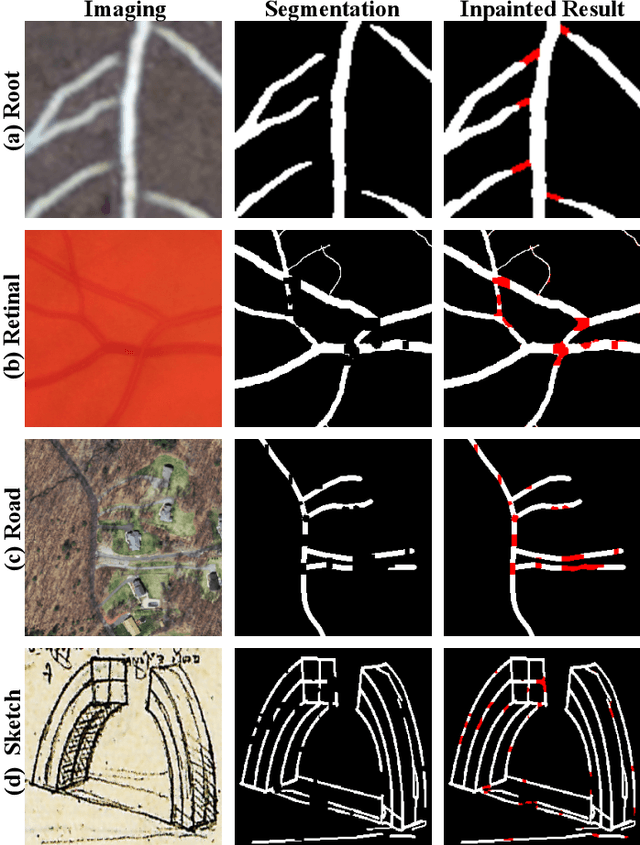
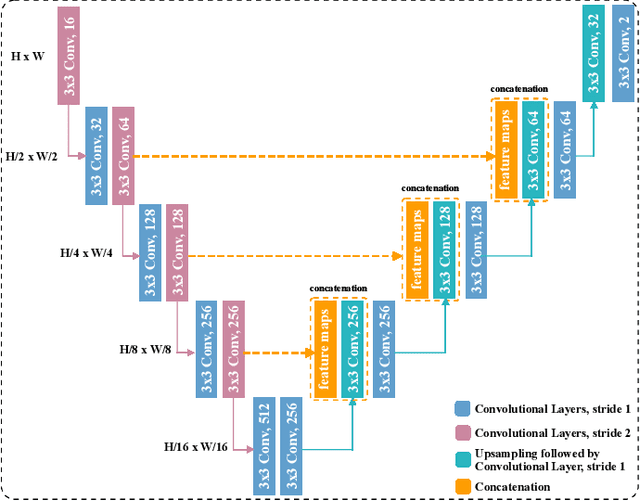
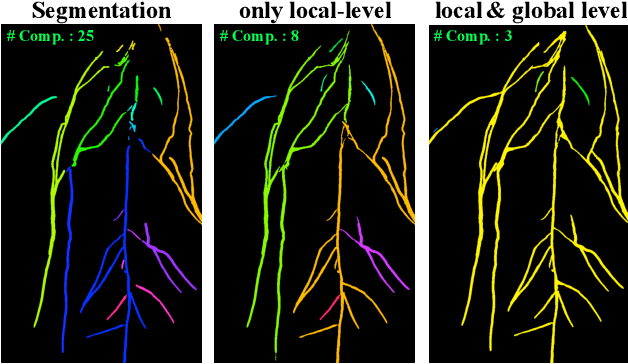
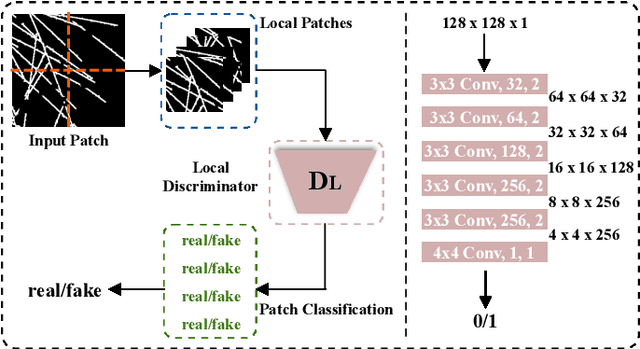
Several imaging applications (vessels, retina, plant roots, road networks from satellites) require the accurate segmentation of thin structures for subsequent analysis. Discontinuities (gaps) in the extracted foreground may hinder down-stream image-based analysis of biomarkers, organ structure and topology. In this paper, we propose a general post-processing technique to recover such gaps in large-scale segmentation masks. We cast this problem as a blind inpainting task, where the regions of missing lines in the segmentation masks are not known to the algorithm, which we solve with an adversarially trained neural network. One challenge of using large images is the memory capacity of current GPUs. The typical approach of dividing a large image into smaller patches to train the network does not guarantee global coherence of the reconstructed image that preserves structure and topology. We use adversarial training and reinforcement learning (Policy Gradient) to endow the model with both global context and local details. We evaluate our method in several datasets in medical imaging, plant science, and remote sensing. Our experiments demonstrate that our model produces the most realistic and complete inpainted results, outperforming other approaches. In a dedicated study on plant roots we find that our approach is also comparable to human performance. Implementation available at \url{https://github.com/Hhhhhhhhhhao/Thin-Structure-Inpainting}.
Leveraging multiple datasets for deep leaf counting
Sep 05, 2017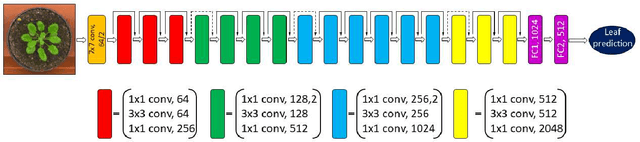
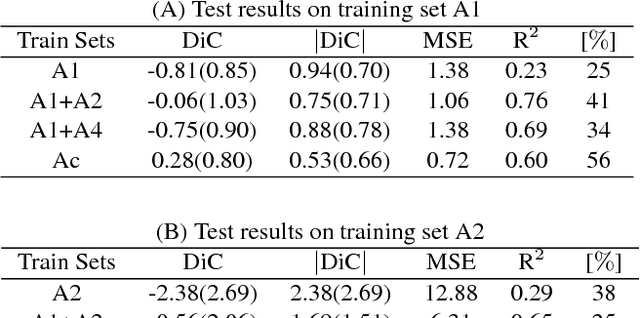

The number of leaves a plant has is one of the key traits (phenotypes) describing its development and growth. Here, we propose an automated, deep learning based approach for counting leaves in model rosette plants. While state-of-the-art results on leaf counting with deep learning methods have recently been reported, they obtain the count as a result of leaf segmentation and thus require per-leaf (instance) segmentation to train the models (a rather strong annotation). Instead, our method treats leaf counting as a direct regression problem and thus only requires as annotation the total leaf count per plant. We argue that combining different datasets when training a deep neural network is beneficial and improves the results of the proposed approach. We evaluate our method on the CVPPP 2017 Leaf Counting Challenge dataset, which contains images of Arabidopsis and tobacco plants. Experimental results show that the proposed method significantly outperforms the winner of the previous CVPPP challenge, improving the results by a minimum of ~50% on each of the test datasets, and can achieve this performance without knowing the experimental origin of the data (i.e. in the wild setting of the challenge). We also compare the counting accuracy of our model with that of per leaf segmentation algorithms, achieving a 20% decrease in mean absolute difference in count (|DiC|).
* 8 pages, 3 figures, 3 tables
ARIGAN: Synthetic Arabidopsis Plants using Generative Adversarial Network
Sep 04, 2017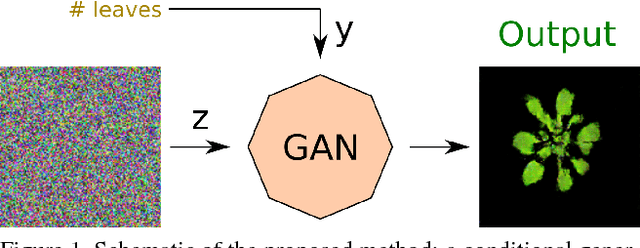
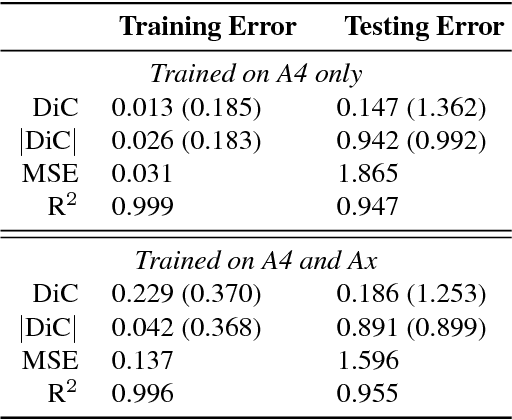
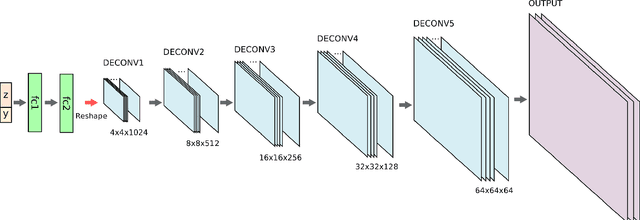
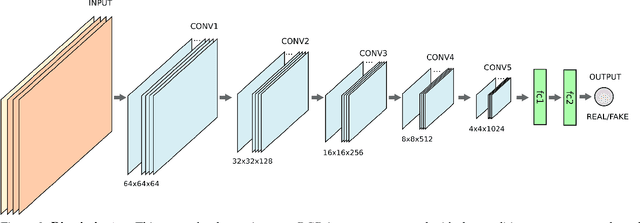
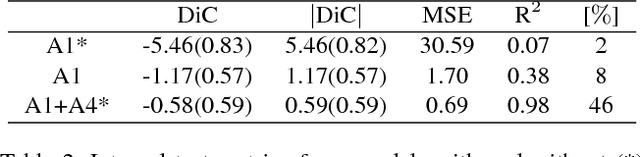
In recent years, there has been an increasing interest in image-based plant phenotyping, applying state-of-the-art machine learning approaches to tackle challenging problems, such as leaf segmentation (a multi-instance problem) and counting. Most of these algorithms need labelled data to learn a model for the task at hand. Despite the recent release of a few plant phenotyping datasets, large annotated plant image datasets for the purpose of training deep learning algorithms are lacking. One common approach to alleviate the lack of training data is dataset augmentation. Herein, we propose an alternative solution to dataset augmentation for plant phenotyping, creating artificial images of plants using generative neural networks. We propose the Arabidopsis Rosette Image Generator (through) Adversarial Network: a deep convolutional network that is able to generate synthetic rosette-shaped plants, inspired by DCGAN (a recent adversarial network model using convolutional layers). Specifically, we trained the network using A1, A2, and A4 of the CVPPP 2017 LCC dataset, containing Arabidopsis Thaliana plants. We show that our model is able to generate realistic 128x128 colour images of plants. We train our network conditioning on leaf count, such that it is possible to generate plants with a given number of leaves suitable, among others, for training regression based models. We propose a new Ax dataset of artificial plants images, obtained by our ARIGAN. We evaluate this new dataset using a state-of-the-art leaf counting algorithm, showing that the testing error is reduced when Ax is used as part of the training data.
Theta-RBM: Unfactored Gated Restricted Boltzmann Machine for Rotation-Invariant Representations
Jun 29, 2016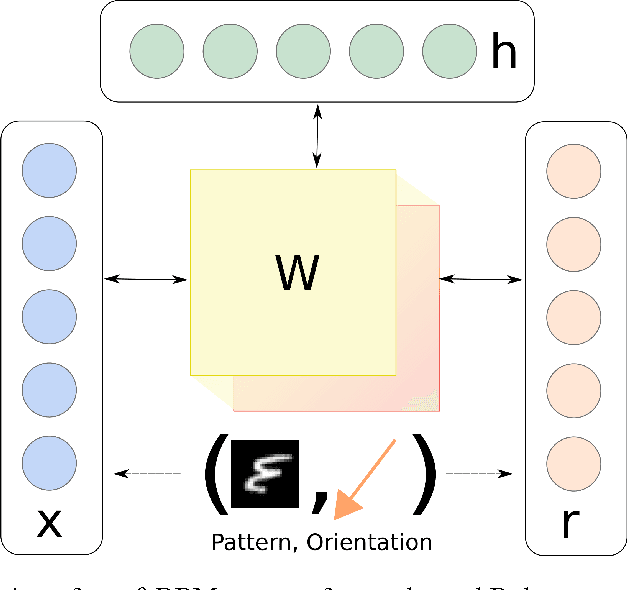
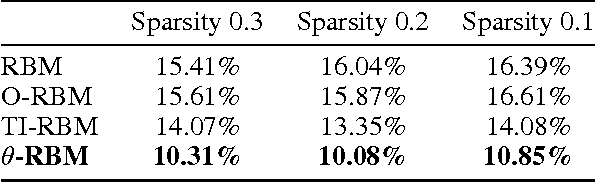
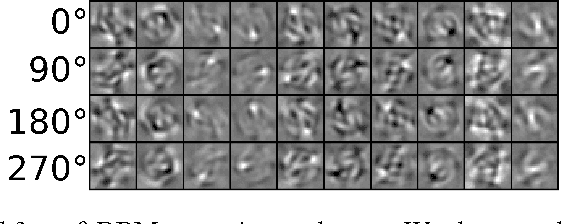
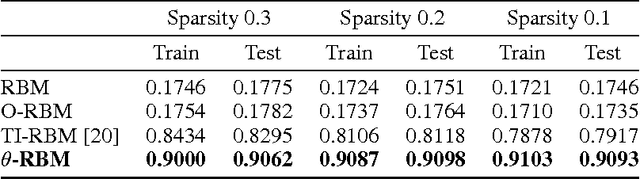
Learning invariant representations is a critical task in computer vision. In this paper, we propose the Theta-Restricted Boltzmann Machine ({\theta}-RBM in short), which builds upon the original RBM formulation and injects the notion of rotation-invariance during the learning procedure. In contrast to previous approaches, we do not transform the training set with all possible rotations. Instead, we rotate the gradient filters when they are computed during the Contrastive Divergence algorithm. We formulate our model as an unfactored gated Boltzmann machine, where another input layer is used to modulate the input visible layer to drive the optimisation procedure. Among our contributions is a mathematical proof that demonstrates that {\theta}-RBM is able to learn rotation-invariant features according to a recently proposed invariance measure. Our method reaches an invariance score of ~90% on mnist-rot dataset, which is the highest result compared with the baseline methods and the current state of the art in transformation-invariant feature learning in RBM. Using an SVM classifier, we also showed that our network learns discriminative features as well, obtaining ~10% of testing error.