 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhenoAssistant: A Conversational Multi-Agent AI System for Automated Plant Phenotyping
Apr 28, 2025Plant phenotyping increasingly relies on (semi-)automated image-based analysis workflows to improve its accuracy and scalability. However, many existing solutions remain overly complex, difficult to reimplement and maintain, and pose high barriers for users without substantial computational expertise. To address these challenges, we introduce PhenoAssistant: a pioneering AI-driven system that streamlines plant phenotyping via intuitive natural language interaction. PhenoAssistant leverages a large language model to orchestrate a curated toolkit supporting tasks including automated phenotype extraction, data visualisation and automated model training. We validate PhenoAssistant through several representative case studies and a set of evaluation tasks. By significantly lowering technical hurdles, PhenoAssistant underscores the promise of AI-driven methodologies to democratising AI adoption in plant biology.
ZipNN: Lossless Compression for AI Models
Nov 07, 2024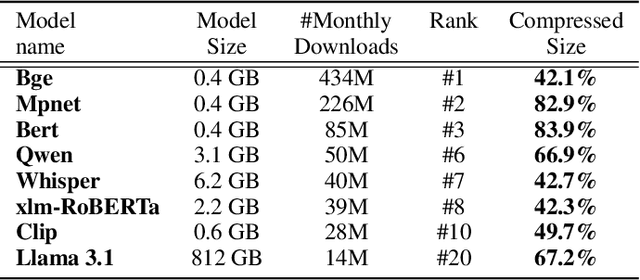
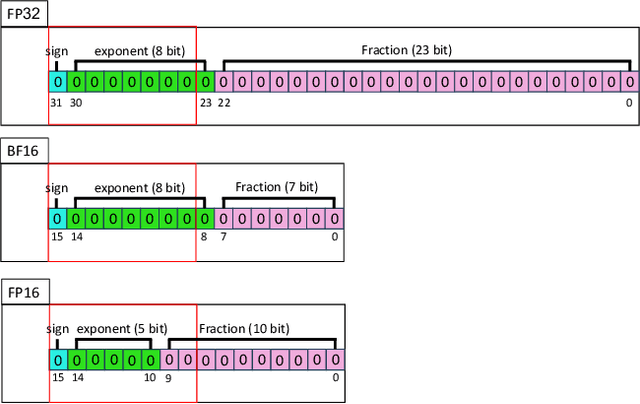
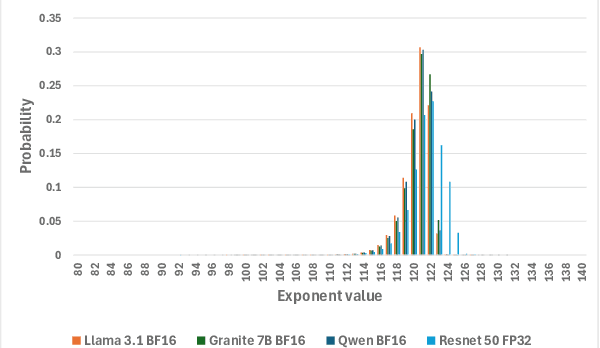
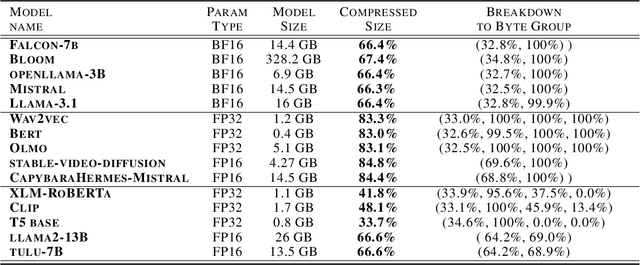
With the growth of model sizes and the scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast model compression literature deleting parts of the model weights for faster inference, we investigate a more traditional type of compression - one that represents the model in a compact form and is coupled with a decompression algorithm that returns it to its original form and size - namely lossless compression. We present ZipNN a lossless compression tailored to neural networks. Somewhat surprisingly, we show that specific lossless compression can gain significant network and storage reduction on popular models, often saving 33% and at times reducing over 50% of the model size. We investigate the source of model compressibility and introduce specialized compression variants tailored for models that further increase the effectiveness of compression. On popular models (e.g. Llama 3) ZipNN shows space savings that are over 17% better than vanilla compression while also improving compression and decompression speeds by 62%. We estimate that these methods could save over an ExaByte per month of network traffic downloaded from a large model hub like Hugging Face.
AI Age Discrepancy: A Novel Parameter for Frailty Assessment in Kidney Tumor Patients
Jul 02, 2024Kidney cancer is a global health concern, and accurate assessment of patient frailty is crucial for optimizing surgical outcomes. This paper introduces AI Age Discrepancy, a novel metric derived from machine learning analysis of preoperative abdominal CT scans, as a potential indicator of frailty and postoperative risk in kidney cancer patients. This retrospective study of 599 patients from the 2023 Kidney Tumor Segmentation (KiTS) challenge dataset found that a higher AI Age Discrepancy is significantly associated with longer hospital stays and lower overall survival rates, independent of established factors. This suggests that AI Age Discrepancy may provide valuable insights into patient frailty and could thus inform clinical decision-making in kidney cancer treatment.
Non-Volatile Memory Accelerated Posterior Estimation
Feb 21, 2022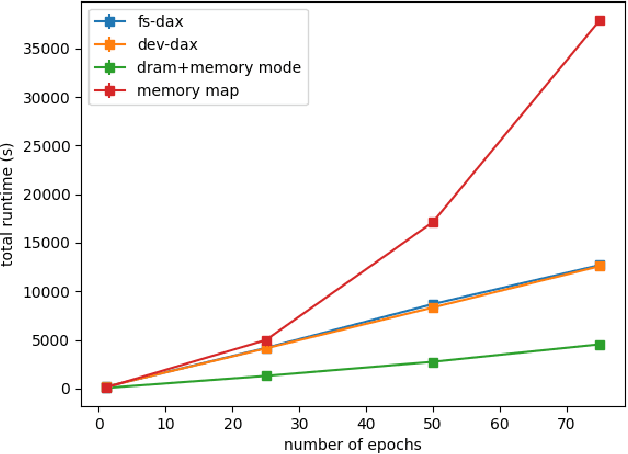

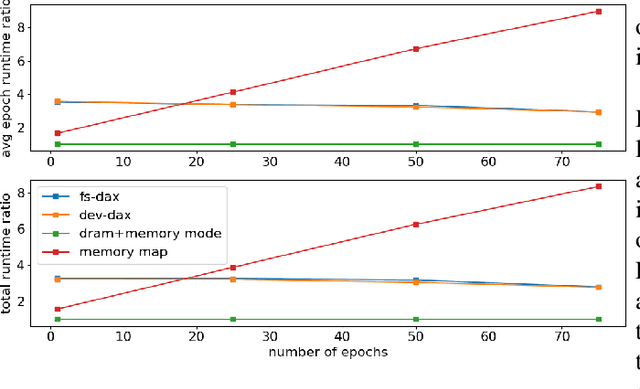
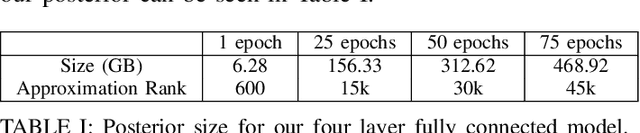
Bayesian inference allows machine learning models to express uncertainty. Current machine learning models use only a single learnable parameter combination when making predictions, and as a result are highly overconfident when their predictions are wrong. To use more learnable parameter combinations efficiently, these samples must be drawn from the posterior distribution. Unfortunately computing the posterior directly is infeasible, so often researchers approximate it with a well known distribution such as a Gaussian. In this paper, we show that through the use of high-capacity persistent storage, models whose posterior distribution was too big to approximate are now feasible, leading to improved predictions in downstream tasks.
Non-Volatile Memory Accelerated Geometric Multi-Scale Resolution Analysis
Feb 21, 2022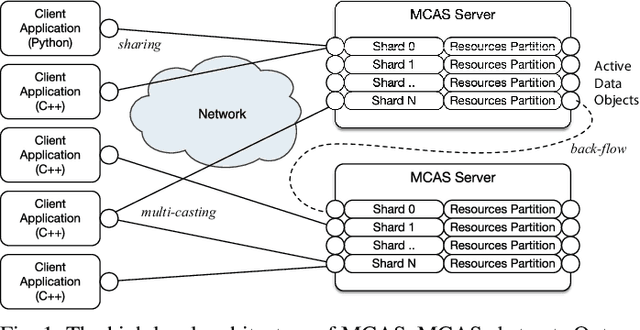
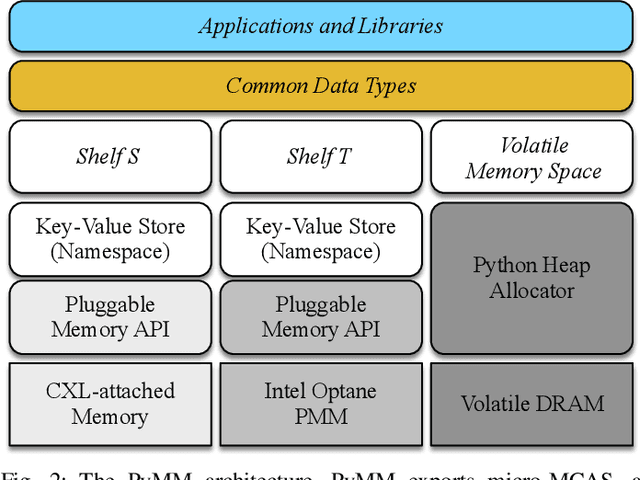
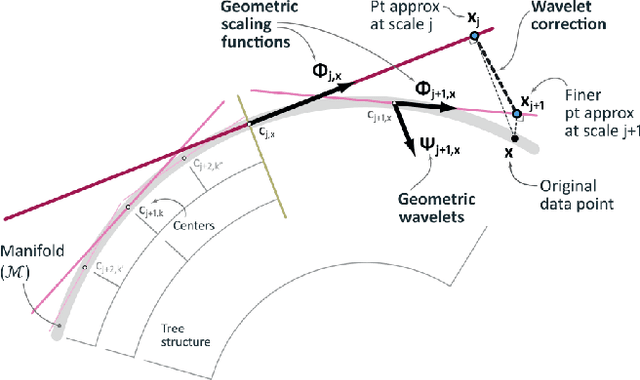
Dimensionality reduction algorithms are standard tools in a researcher's toolbox. Dimensionality reduction algorithms are frequently used to augment downstream tasks such as machine learning, data science, and also are exploratory methods for understanding complex phenomena. For instance, dimensionality reduction is commonly used in Biology as well as Neuroscience to understand data collected from biological subjects. However, dimensionality reduction techniques are limited by the von-Neumann architectures that they execute on. Specifically, data intensive algorithms such as dimensionality reduction techniques often require fast, high capacity, persistent memory which historically hardware has been unable to provide at the same time. In this paper, we present a re-implementation of an existing dimensionality reduction technique called Geometric Multi-Scale Resolution Analysis (GMRA) which has been accelerated via novel persistent memory technology called Memory Centric Active Storage (MCAS). Our implementation uses a specialized version of MCAS called PyMM that provides native support for Python datatypes including NumPy arrays and PyTorch tensors. We compare our PyMM implementation against a DRAM implementation, and show that when data fits in DRAM, PyMM offers competitive runtimes. When data does not fit in DRAM, our PyMM implementation is still able to process the data.
What is Learned in Knowledge Graph Embeddings?
Oct 19, 2021
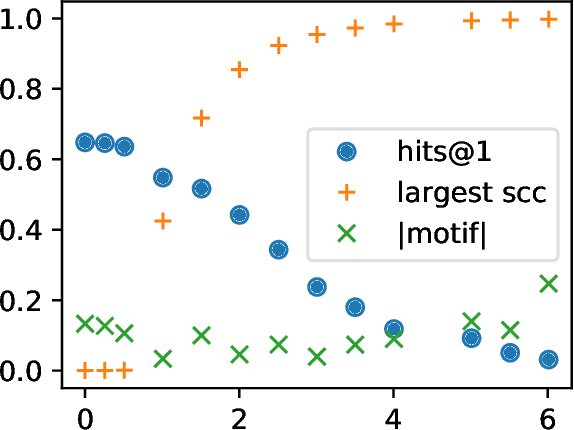

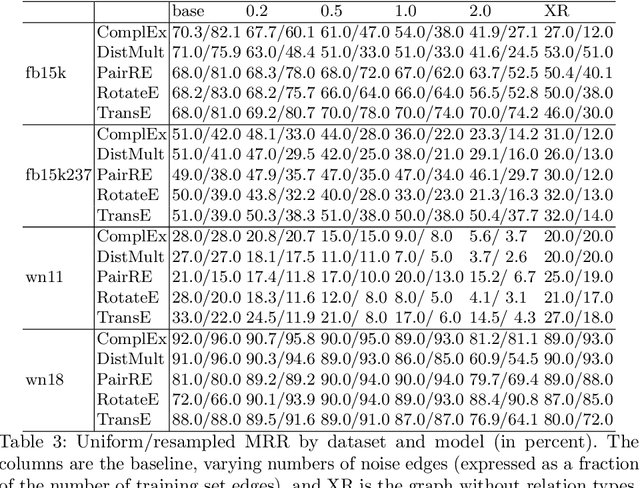
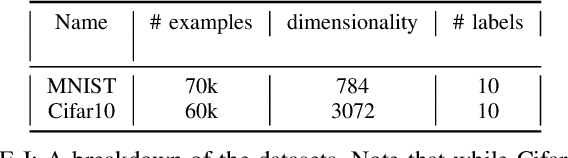
A knowledge graph (KG) is a data structure which represents entities and relations as the vertices and edges of a directed graph with edge types. KGs are an important primitive in modern machine learning and artificial intelligence. Embedding-based models, such as the seminal TransE [Bordes et al., 2013] and the recent PairRE [Chao et al., 2020] are among the most popular and successful approaches for representing KGs and inferring missing edges (link completion). Their relative success is often credited in the literature to their ability to learn logical rules between the relations. In this work, we investigate whether learning rules between relations is indeed what drives the performance of embedding-based methods. We define motif learning and two alternative mechanisms, network learning (based only on the connectivity of the KG, ignoring the relation types), and unstructured statistical learning (ignoring the connectivity of the graph). Using experiments on synthetic KGs, we show that KG models can learn motifs and how this ability is degraded by non-motif (noise) edges. We propose tests to distinguish the contributions of the three mechanisms to performance, and apply them to popular KG benchmarks. We also discuss an issue with the standard performance testing protocol and suggest an improvement. To appear in the proceedings of Complex Networks 2021.
GymFG: A Framework with a Gym Interface for FlightGear
Apr 26, 2020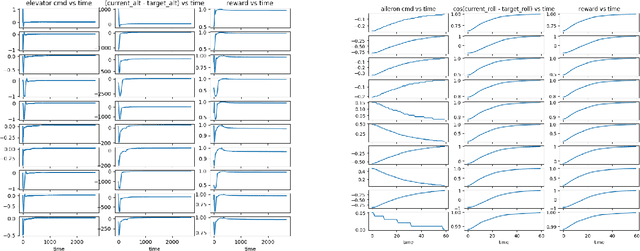
Over the past decades, progress in deployable autonomous flight systems has slowly stagnated. This is reflected in today's production air-crafts, where pilots only enable simple physics-based systems such as autopilot for takeoff, landing, navigation, and terrain/traffic avoidance. Evidently, autonomy has not gained the trust of the community where higher problem complexity and cognitive workload are required. To address trust, we must revisit the process for developing autonomous capabilities: modeling and simulation. Given the prohibitive costs for live tests, we need to prototype and evaluate autonomous aerial agents in a high fidelity flight simulator with autonomous learning capabilities applicable to flight systems: such a open-source development platform is not available. As a result, we have developed GymFG: GymFG couples and extends a high fidelity, open-source flight simulator and a robust agent learning framework to facilitate learning of more complex tasks. Furthermore, we have demonstrated the use of GymFG to train an autonomous aerial agent using Imitation Learning. With GymFG, we can now deploy innovative ideas to address complex problems and build the trust necessary to move prototypes to the real-world.
Detecting Speech Act Types in Developer Question/Answer Conversations During Bug Repair
Jul 03, 2018
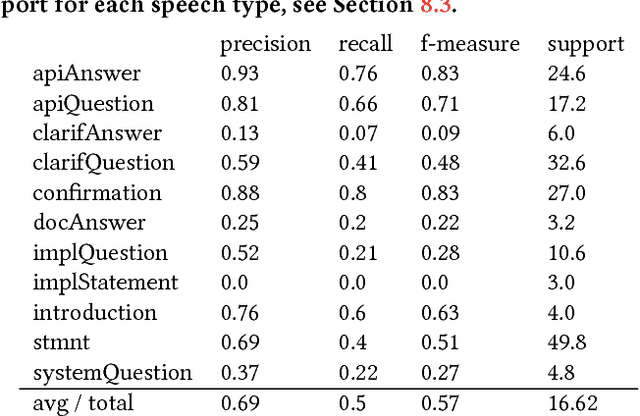
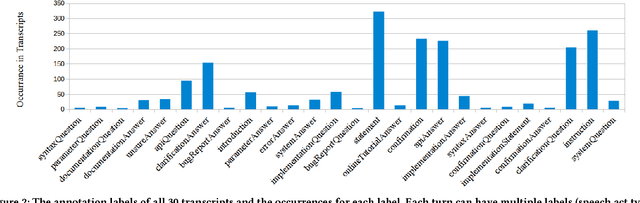

This paper targets the problem of speech act detection in conversations about bug repair. We conduct a "Wizard of Oz" experiment with 30 professional programmers, in which the programmers fix bugs for two hours, and use a simulated virtual assistant for help. Then, we use an open coding manual annotation procedure to identify the speech act types in the conversations. Finally, we train and evaluate a supervised learning algorithm to automatically detect the speech act types in the conversations. In 30 two-hour conversations, we made 2459 annotations and uncovered 26 speech act types. Our automated detection achieved 69% precision and 50% recall. The key application of this work is to advance the state of the art for virtual assistants in software engineering. Virtual assistant technology is growing rapidly, though applications in software engineering are behind those in other areas, largely due to a lack of relevant data and experiments. This paper targets this problem in the area of developer Q/A conversations about bug repair.